책 전반에서 살펴본 바와 같이, interconnection network의 설계는 성능 요구사항 명세와 몇 가지 패키징 및 비용 제약 조건으로부터 시작된다. 이러한 기준들이 해당 네트워크의 topology, routing, flow-control 선택을 이끈다. 이러한 설계 초기 결정들을 안내하기 위해, 우리는 zero-load latency와 throughput 같은 단순한 성능 예측 지표들을 소개했다. 물론 이 지표들은 네트워크에 대한 몇 가지 가정을 포함한다. 예를 들어, routing algorithm과 topology에 대한 대부분의 분석에서 이상적인 flow control을 가정했다. 네트워크 설계 초기에는 단순한 모델이 합리적이지만, 네트워크의 정확한 성능을 정확히 특성화하려면 더 정밀한 모델이 필요하다.
이 장에서는 먼저 네트워크의 기본적인 성능 지표들을 정의하고, 이 지표들을 어떻게 추정하고 해석하는지를 설명한다. 이어서 queuing model과 확률적 기법을 포함하는 상위 수준 네트워크 동작 모델링에 유용한 분석 도구들을 소개한다. 24장에서는 보다 정밀한 네트워크 시뮬레이터 사용을 다루고, 25장에서는 여러 네트워크 구성에서의 시뮬레이션 결과를 제시한다.
23.1 Interconnection Network 성능 측정 지표
특정 네트워크의 성능을 측정하고 표현하는 방법은 여러 가지가 있지만, 여기서는 throughput, latency, fault tolerance의 세 가지 기본 항목에 초점을 맞춘다. 이 용어들은 일반적으로 들릴 수 있으나, 그 정확한 정의는 어떻게 측정하느냐, 즉 측정 환경에 강하게 의존한다.
측정 구성

interconnection network의 표준 측정 구성은 그림 23.1에 나타나 있다. 네트워크 성능을 측정하기 위해, 네트워크의 각 terminal 또는 port에 terminal instrumentation을 부착한다. 이 instrumentation은 지정된 traffic pattern, packet 길이 분포, interarrival 시간 분포에 따라 packet을 생성하는 packet source를 포함한다. 각 terminal에서는 packet source와 네트워크 사이에 무한 깊이의 source queue가 존재한다. 이 source queue는 시뮬레이션 대상 네트워크의 일부는 아니며, traffic process와 네트워크를 분리하기 위해 사용된다. packet source와 source queue 사이에는 입력 packet을 카운트하고 각 packet의 시작 시간을 측정하는 input packet measurement process가 있다. 이 측정 프로세스는 반드시 source queue 이전에 위치해야 한다. 그래야 source에 의해 생성되었지만 아직 네트워크에 주입되지 않은 packet도 고려되며, packet의 latency가 source queue에서의 시간도 포함하게 된다. 각 출력 terminal에도 대응되는 측정 프로세스가 있어 packet을 카운트하고 각 packet의 종료 시간을 기록한다. throughput은 각 출력에서 도착한 packet을 카운트하여 측정하고, latency는 각 packet의 종료 시간에서 시작 시간을 뺀 값으로 측정한다.
Open-loop 측정
이러한 open-loop 측정 구성은 traffic parameter를 네트워크와 독립적으로 제어할 수 있게 해 준다. source queue가 없다면, packet source가 네트워크 terminal이 수용 불가능한 시점—예를 들어 input buffer가 가득 찼을 때—에 packet을 주입하려 할 수 있다. 이 경우, source가 생성한 traffic은 네트워크에 의해 영향을 받아 원래 지정한 traffic pattern이 아니게 된다. 우리는 일반적으로 특정 traffic pattern에서 네트워크를 평가하는 것이 목표이므로, throughput, latency, fault tolerance 측정을 위해 open-loop 방식을 사용한다.
Closed-loop 측정
네트워크가 traffic에 영향을 미치는 closed-loop 측정 시스템은 전체 시스템 성능을 측정할 때 유용하다. 예를 들어, multicomputer의 성능을 추정하려면 terminal instrumentation을 multicomputer processor 시뮬레이션으로 대체한 시뮬레이션을 수행한다. 생성되는 traffic은 실제 애플리케이션 실행 중 발생하는 프로세서 간 혹은 프로세서-메모리 간 메시지이다. 프로세서는 네트워크와 상호작용하므로 주입률은 쉽게 제어되지 않는다. 예를 들어, 메모리 응답을 기다리는 프로세서는 outstanding request 수 제한으로 인해 요청 수가 줄어든다. 이 설정에서는 보통 애플리케이션 실행 시간이 bandwidth, routing algorithm, flow control 같은 네트워크 parameter에 얼마나 민감한지 테스트하는 데 사용된다.
Steady-state 성능 측정
대부분의 경우, 우리는 네트워크의 정상 상태(steady-state) 성능, 즉 고정된 traffic source가 equilibrium에 도달한 후의 성능에 관심을 가진다. 네트워크가 equilibrium에 도달했다는 것은 평균 queue 길이가 정상 상태 값에 도달했다는 의미이다. 정상 상태 측정은 측정 대상 process가 stationary할 때만 의미 있다. 즉, process의 통계적 특성이 시간에 따라 변하지 않아야 한다. transient 성능 측정, 즉 traffic이나 구성 변화에 대한 네트워크의 응답도 때때로 관심 대상이지만, 대부분은 steady-state 측정에 초점을 둔다.
정상 상태 성능을 측정하기 위해 실험(또는 시뮬레이션)을 세 단계로 나눈다: warm-up, measurement, drain.
- Warm-up phase: 네트워크가 equilibrium에 도달할 수 있도록 N₁ 사이클을 실행하며, 이 기간 동안 packet은 측정되지 않는다.
- Measurement phase: N₂ 사이클 동안, source queue에 들어가는 모든 packet에 시작 시간이 태그되며, 이들을 measurement packet이라 부른다.
- Drain phase: measurement packet이 목적지에 모두 도달할 때까지 네트워크를 계속 실행한다. 도착한 packet의 종료 시간을 측정하고 기록한다. 이 측정 구간 동안 도착한 모든 packet은 throughput 측정을 위해 카운트된다. latency는 measurement packet의 시작 시간과 종료 시간으로 계산된다.
모든 measurement packet의 종료 시간을 측정하지 못하면 latency 분포의 꼬리 부분이 잘려 나가게 되므로, simulation을 충분히 길게 실행해야 한다.
※ 네트워크가 공정(fair)하지 않다면 마지막 measurement packet이 도달하는 데 많은 cycle이 걸릴 수 있다. 네트워크가 starvation에 취약하다면 drain phase가 끝나지 않을 수도 있다.
warm-up과 drain phase 동안에도 packet source는 packet을 계속 생성하지만, 이 packet은 측정 대상이 아니다. 그러나 이 packet은 background traffic으로서 measurement packet에 영향을 준다. N₁과 N₂ 값의 결정 방법은 24.3절에서 다룬다.
23.1.1 Throughput
Throughput은 특정 traffic pattern에서 네트워크가 packet을 전달하는 속도이다. 각 flow(즉, source-destination 쌍)에서 지정된 시간 동안 도착한 packet 수를 카운트하여 flow rate를 계산하고, 이로부터 전체 traffic pattern의 일부로서 얼마나 전달되었는지를 계산한다.

Throughput(accepted traffic)은 demand(offered traffic)과 대비된다. demand는 packet source가 packet을 생성하는 속도이다.
Throughput과 demand의 관계를 이해하기 위해 일반적으로 throughput(accepted traffic)을 demand(offered traffic)의 함수로 나타낸 그래프를 사용한다. (그림 23.2 참조) saturation 이하의 traffic 수준에서는 throughput이 demand와 같고, 이때 그래프는 직선이다. offered traffic이 계속 증가하면 결국 saturation에 도달하게 되며, 이는 throughput이 demand와 같게 유지되는 최대 수치이다. demand가 saturation을 넘으면 네트워크는 더 이상 동일한 속도로 packet을 전달할 수 없다.
packet이 생성되는 속도만큼 빠르게 전달되지 못하면 — 또는 적어도 우리가 요구하는 traffic pattern에 대해서는 — 네트워크는 saturation을 초과한 상태가 된다. saturation을 초과한 이후에도 안정적인 네트워크는 지정된 traffic pattern에 대해 최대 throughput을 유지하며 동작한다. 그러나 많은 네트워크는 불안정하며, saturation을 지나면 throughput이 급격히 떨어진다. 예를 들어, 그림 23.2의 네트워크는 안정적이며, saturation throughput은 전체 용량의 43%이다. 그림 23.3은 유사한 네트워크의 성능을 보여주는데, 이 또한 43%에서 saturation이 발생하지만, 그 이후 throughput이 급격히 하락하며 불안정하다. 이는 flow control mechanism의 unfairness 때문이며, 이러한 네트워크는 25.2.5절의 시뮬레이션 예제에서 더 자세히 분석된다.
throughput은 일반적으로 네트워크 용량의 일부로 표현된다. 이렇게 하면 네트워크의 성능을 더 직관적으로 이해할 수 있으며, 크기나 topology가 다른 네트워크 간의 비교도 가능하다. 예를 들어, 그림 23.2의 8-ary 2-mesh 네트워크의 총 용량은 U^,M=4b/k=b/2\hat{U},M = 4b/k = b/2이다. 여기서 b는 channel bandwidth이다. 모든 source가 동일한 양의 traffic을 생성한다고 가정하면, 각 source는 bλ/2b\lambda/2의 속도로 packet을 생성하며, 여기서 λ는 전체 용량 대비 offered traffic 비율이다. saturation은 이 용량의 43%에서 발생한다.
일부 불안정한 네트워크의 경우, saturation을 초과해도 전달된 packet의 총량은 일정하게 유지되지만, 이 packet들의 분포가 지정된 traffic pattern과 일치하지 않는다. 이러한 네트워크의 throughput을 정확히 측정하려면 특정 traffic pattern에 대한 throughput을 측정해야 한다. 이를 위해 네트워크의 모든 입력에 지정된 traffic을 적용하고, 각 flow에 대해 수용된 traffic을 별도로 측정한다. 지정된 traffic pattern에 대한 throughput은 모든 flow에 대해 수용된 traffic과 제공된 traffic의 비율 중 최소값으로 정의된다.

saturation을 초과하여 demand를 증가시키면, 도착지로 전달된 traffic matrix는 다음과 같은 형태를 가진다고 볼 수 있다:

즉, 목적지에 도달한 traffic은 우리가 원하는 traffic pattern의 Θ 단위와 추가적인 traffic X로 구성되며, X는 strictly positive한 행렬이다. throughput 측정 시 이 추가 traffic은 우리가 지정한 traffic pattern에 부합하지 않으므로 계산에 포함되지 않는다.
네트워크 불안정성은 종종 네트워크 내의 fairness 문제로 인해 발생한다. 과거에는 saturation 이후 평균 throughput만을 보고하는 경우가 많았으며, 이는 X에 대해 가산점을 주는 셈이다. 하지만 모든 flow 중 최소 throughput을 보고하면, 어떤 flow가 starvation되고 있는지를 확인할 수 있다. starvation은 일반적으로 unfair flow control의 결과이다. 그림 23.2에서는 saturation 이후에도 accepted traffic이 거의 일정하므로, 네트워크가 각 flow에 bandwidth를 공정하게 할당하고 있다고 볼 수 있다. 반면 그림 23.3에서는 saturation 이후 throughput이 급격히 감소하는데, 이는 flow control이 불공정하다는 것을 시사한다.

심지어 네트워크가 flow 간 bandwidth를 공정하게 할당하더라도, offered traffic이 증가함에 따라 accepted traffic이 줄어들 수 있다. 이는 non-minimal routing algorithm에 의해 발생할 수 있다. routing 결정이 불완전한 정보에 기반할 경우, contention이 증가하면서 misrouting도 늘어나고, 그 결과 packet이 더 많은 hop을 거치게 되어 channel load가 증가한다. 이러한 문제를 피하려면 routing algorithm을 신중히 설계해야 하며, 그렇지 않으면 saturation 이후 throughput이 빠르게 감소할 수 있다.
유사한 상황은 deadlock-free escape path를 사용하는 adaptive routing algorithm에서도 발생할 수 있다. offered traffic이 증가하면 더 많은 packet이 escape path로 밀려나고, accepted throughput은 결국 adaptive algorithm이 아닌 escape routing algorithm의 throughput 수준으로 떨어진다. 이 내용은 25.2절에서 추가로 다룬다.
offered traffic 대비 accepted traffic 그래프는 특정 traffic pattern에서 네트워크의 throughput 성능을 상세히 보여주지만, 여러 traffic pattern의 성능을 한눈에 보려면 saturation throughput에 대한 히스토그램을 그리는 것이 유용하다. 예를 들어, 10³ ~ 10⁶개의 무작위 permutation traffic pattern을 생성해 측정한 결과를 시각화할 수 있다. 이와 관련된 예시는 25.1절에 포함되어 있다.
23.1.2 Latency
Latency는 packet이 source에서 destination까지 네트워크를 통과하는 데 걸리는 시간이다. 지금까지 latency 평가는 주로 zero-load latency에 초점을 맞추었으며, 이는 shared resource에 대한 다른 packet들과의 contention에 의한 latency를 무시한다. contention latency를 모델링이나 시뮬레이션으로 포함하면 latency는 offered traffic의 함수가 되며, 이 함수를 그래프로 표현하면 도움이 된다. 그림 23.4는 latency vs. offered traffic 예시 그래프이다.

latency를 측정할 때는 그림 23.1의 측정 구성으로 traffic을 적용한다. 일반적으로 offered traffic αΛ를 α = 0에서 saturation throughput α = Θ까지 sweep한다. α > Θ인 traffic 수준에서는 latency가 무한대가 되어 측정이 불가능하다. 각 packet에 대해, source가 첫 번째 비트를 생성한 시점부터 마지막 비트가 네트워크를 빠져나가는 시점까지를 latency로 측정한다. 전체 latency는 모든 packet의 평균 latency로 보고된다. 경우에 따라서는 packet latency의 히스토그램, 최악의 packet latency, 특정 flow에 대한 통계도 유용하다. throughput과 마찬가지로 offered traffic은 네트워크 용량의 일부로 표시된다.
latency vs. offered traffic 그래프는 일정한 형태를 갖는다. 이는 zero-load latency의 수평 점근선에서 시작해, saturation throughput의 수직 점근선으로 향한다. low traffic 구간에서는 latency가 zero-load latency에 근접한다.
traffic이 증가함에 따라 contention도 증가하면서, packet은 buffer와 channel을 기다리게 되어 latency가 상승한다. 결국 offered traffic이 saturation throughput에 접근하면 latency 곡선은 수직 점근선에 근접하게 된다. 이 곡선의 형태는 기본적인 queuing theory (23.2.1절 참조)로 설명할 수 있다.
평균 latency도 유용하지만, 전체 또는 특정 subset에 대한 latency 분포를 분석하는 것도 의미 있다. 예를 들어, virtual-channel flow control을 사용하는 경우, 일부 채널은 high-priority traffic에 예약되어 있을 수 있다. 이럴 때 high-priority와 일반 traffic의 latency를 분리하여 분석하면 우선순위 정책의 효과를 평가할 수 있다. 또 하나의 유의미한 subset은 특정 source-destination pair 사이의 packet 전체이다. 특히 non-minimal routing algorithm을 사용하는 경우 유용하며, 해당 경로의 평균 길이를 추정하는 데 활용할 수 있다. 여러 latency 분포 그래프는 25.2절에 제시되어 있다.
23.1.3 Fault Tolerance
Fault tolerance는 하나 이상의 고장이 발생한 상태에서도 네트워크가 동작할 수 있는 능력을 의미한다. 네트워크의 fault tolerance에 대한 가장 중요한 정보는 고장 발생 시에도 정상적으로 동작할 수 있는지 여부이다. 어떤 node나 channel의 단일 고장이 있어도 (faulty terminal을 제외한) 모든 terminal 간 packet 전달이 가능한 경우, 해당 네트워크는 single-point fault tolerant하다고 한다. 많은 시스템에서는 단일 고장만 견딜 수 있어도 충분한데, 이는 단일 고장 확률이 낮고 동시에 여러 고장이 발생할 확률은 매우 낮기 때문이다. 또한 대부분의 고가용성 시스템은 고장이 발생하면 즉시 복구되므로 다른 고장이 발생하기 전에 faulty component가 교체된다.
fault tolerance 요구는 여러 설계 결정에 영향을 준다. 예를 들어, 네트워크가 single-point fault tolerant해야 한다면 deterministic routing을 사용할 수 없다. 특정 channel에 fault가 생기면, 그 경로를 사용하는 모든 node pair가 연결을 잃기 때문이다. fault가 발생해도 성능이 점진적으로 저하된다면, 이를 graceful degradation이라고 부른다. fault-tolerant 네트워크의 성능은 25.3절에서 다룬다.
23.1.4 Common Measurement Pitfalls
interconnection network의 성능을 측정할 때 자주 발생하는 오류가 몇 가지 있다. 저자들 자신도 과거에 이러한 실수를 저질렀으며, 여기에서 소개함으로써 독자들이 같은 실수를 반복하지 않기를 바란다.
Source queue 누락: 네트워크 성능을 측정하면서 source queue를 제대로 구성하지 않는 경우가 많다. 그림 23.5는 source queue의 효과가 누락되는 두 가지 경우를 보여준다. 그림 23.5(a)에서는 아예 source queue가 없다. 이 경우...

그림 23.5 설명
그림 23.5는 무한한 source queue 없이 네트워크 성능을 측정하려는 시도를 보여준다. 결과 시스템은 closed loop가 되며, 적용된 traffic pattern은 원래 의도한 패턴이 아니게 되고, 측정된 latency는 네트워크 진입을 대기한 시간을 포함하지 않는다.
- (a): 입력 채널이 바쁠 때 source는 packet을 drop하거나 입력이 가능해질 때까지 injection을 지연시켜야 한다. 후자의 경우, 이후 packet의 생성도 지연되어야 하며, 그렇지 않으면 queue가 필요하다. 어느 경우든 네트워크의 contention이 traffic pattern에 영향을 주게 된다.
- (b): source queue는 존재하지만, packet 카운팅과 timing이 source queue의 출력에서 시작된다.
source queue가 없이 수행된 측정은 두 가지 이유로 무효이다.
첫째, 측정 지점에서 적용된 traffic pattern이 우리가 의도한 것과 다르다. 예를 들어 그림 23.6의 간단한 두 노드 네트워크를 보자. 여기서 node 1에서 0으로, 그리고 0에서 1로 각각 1 단위의 traffic을 주입하도록 설정한다. 그러나 source queue 출력 이후에서 packet을 측정하면, 실제 routing에 수락된 0 → 1 방향의 0.1 단위 traffic만 카운트되며, 반대 방향은 전체 1 단위가 그대로 측정된다. 이 결과는 우리가 측정하고자 하는 traffic pattern이 아니다.
둘째, source queue를 생략하면 packet latency가 과소 추정된다. queue 깊이가 얕고 blocking flow control을 사용하는 네트워크에서는 고부하 상황에서 발생하는 contention latency의 대부분이 source queue에서 발생한다. 실제로 네트워크 내부로 packet이 들어가면, 빠르게 전달되는 경우가 많다. 입력 채널을 기다리는 시간을 제외하면 실제 latency보다 훨씬 낮은 값이 측정된다.
평균 throughput만 보고하는 문제
입력 측정에서는 source queue 생략이 문제였다면, 출력 측정에서는 flow별 최소 throughput이 아닌 평균 throughput을 보고하면 문제가 된다. 이 경우에도 실제 측정 대상 traffic pattern과 다른 결과가 나온다.

예를 들어 그림 23.6의 네트워크를 보자. 두 목적지에 도달한 traffic의 평균을 내면, 1과 0.1의 평균인 0.55 단위에서 saturation이 일어난다고 결론 내릴 수 있다. 그러나 실제로 네트워크는 아래와 같이 전달하고 있다:
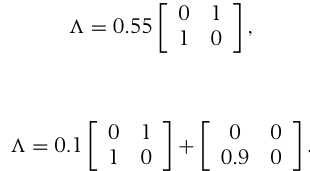
즉, 지정된 traffic pattern의 0.1 단위만 전달되고 나머지는 추가 traffic일 뿐이다. flow 중 최소 수용량을 측정해야 정확한 throughput을 알 수 있다.
특정 flow가 starvation되는 네트워크에서는 평균 throughput만 보고하면 이러한 문제가 완전히 감춰진다. 예를 들어 chaotic routing에서는 네트워크 내부의 packet에 절대적인 우선권을 부여하므로, 일부 input에서는 네트워크가 바쁠 경우 packet이 전혀 진입하지 못해 완전히 starving될 수 있다. 이때 평균 throughput은 여전히 높게 유지되므로, 네트워크가 안정적인 것처럼 보이지만 실제로는 일부 flow가 완전히 차단된 불안정한 상태다.
Latency와 throughput을 함께 나타내는 그래프

일부 연구자는 latency vs. offered traffic 곡선과 accepted vs. offered traffic 곡선을 하나의 그래프로 표현하려 한다. 그림 23.7이 그 예시이다. 이 그래프는 latency를 accepted traffic의 함수로 나타내며, 곡선 위의 각 점은 offered traffic의 다양한 수준을 나타낸다. 불안정한 네트워크에서는 accepted traffic이 saturation 이후 감소하기 때문에, 곡선이 왼쪽으로 되돌아가는 모양을 보인다.
이런 형태의 가장 큰 문제점은 source queue가 측정에 포함되지 않았다는 것을 드러낸다는 점이다. source queue를 고려했다면, saturation을 초과한 모든 offered traffic에서 latency는 무한대가 되어야 하며, 곡선은 wrap-around되지 않고 최대 accepted traffic에서 점근선 형태로 끝나야 한다.
게다가 BNF(Burton Normal Form) 차트는 일반적으로 steady-state 성능을 반영하지 않는다. 대부분의 불안정한 네트워크에서는 saturation 직후 accepted traffic이 급격히 낮아진 후, 그 이후 offered traffic이 증가해도 그 수준에 머문다. 이는 saturation 이후 source queue가 무한히 커지기 시작하기 때문이며, steady-state에서는 큐 크기가 고정된 것이 아니라 무한이 된다. BNF 차트에서 gradual fold-back이 보인다면, simulation이 충분히 오래 실행되지 않았다는 뜻이다.
테스트 구간 동안 생성된 모든 packet을 측정하지 않은 경우
간혹 목적지에서 수신된 packet들의 latency 평균만을 측정하는 경우가 있는데, 이는 측정 구간 동안 생성된 모든 packet을 측정한 것이 아니므로 오류다. 이 경우 긴 latency를 가진 packet들은 측정에 포함되지 않아 latency 분포의 꼬리 부분이 잘리고 평균 latency도 과소 추정된다. warm-up 이후 생성된 packet의 unbiased 샘플을 사용해야 한다. arrival 기준으로 선택한 packet은 편향된 샘플이다.
무작위 traffic만 사용하는 문제
Uniform random traffic은 네트워크 채널 간 load를 자연스럽게 균등하게 분산시켜주는 아주 benign한 패턴이다. nearest-neighbor traffic보다는 약하지만, 거의 best-case workload에 가깝다. 이 때문에 좋지 않은 routing algorithm조차 무난하게 보이게 할 수 있다. 따라서 다양한 adversarial traffic pattern (3.2절 참조)과 충분히 많은 무작위 permutation을 함께 사용해야 한다.
23.2 Analysis
interconnection network의 성능을 측정하기 위해 여러 도구들이 존재한다. 분석(analysis), 시뮬레이션(simulation), 실험(experiment) 모두 네트워크 평가에서 중요한 역할을 한다.
우리는 일반적으로 수학적 모델을 통해 네트워크 성능을 추정하는 분석으로부터 시작한다. 분석은 적은 노력으로 근사적인 성능 수치를 제공하며, 다양한 요소들이 성능에 어떻게 영향을 미치는지를 파악할 수 있게 해 준다. 또한, 분석을 통해 다양한 파라미터나 설정을 가진 네트워크 전체에 대한 성능 예측을 할 수 있는 수식 집합을 도출할 수 있다.
하지만 분석은 보통 여러 가지 근사나 가정을 포함하게 되므로 결과의 정확도에 영향을 줄 수 있다.
분석을 통해 근사적인 결과를 얻은 후에는 보통 시뮬레이션을 수행하여 분석 결과를 검증하고 보다 정확한 성능 추정을 얻는다. 좋은 모델을 사용할 경우 시뮬레이션은 정확한 성능 예측을 제공하지만, 그만큼 시간이 많이 소요된다. 각 시뮬레이션 실행은 단일 네트워크 구성, traffic pattern, load point만 평가할 수 있다. 또한 시뮬레이션은 결과만 요약해서 보여주므로, 어떤 요인이 성능에 영향을 주었는지 직접적인 통찰을 제공하지는 않는다.
※ 하지만 적절한 instrumentation을 사용할 경우, 시뮬레이션을 통해 성능 문제를 진단할 수도 있다.
router의 타이밍과 arbitration을 무시하는 시뮬레이터는 정확도가 매우 낮은 결과를 낼 수 있다.
네트워크가 실제로 구축된 후에는, 실험을 통해 실제 성능을 측정하고 시뮬레이션 모델을 검증한다. 물론 이 시점에서 성능 문제가 발견되면 수정하기 어렵고, 시간과 비용이 많이 든다.
이 절에서는 네트워크 성능 평가의 첫 번째 단계인 분석(analysis)을 다룬다. 특히, analytic performance analysis를 위한 두 가지 기본 도구인 queuing theory와 probability theory를 소개한다. queuing theory는 packet이 대부분의 시간을 큐에서 대기하는 네트워크 분석에 유용하고, probability theory는 contention 시간이 주로 blocking에 의해 발생하는 경우에 적합하다.
23.2.1 Queuing Theory
interconnection network에서 packet은 많은 시간을 큐에서 대기하며 보낸다. 측정 구성에서의 source queue뿐 아니라, 경로상 각 단계의 input buffer들도 큐로 간주된다. queuing theory를 이용하여 각 큐에서 packet이 대기하는 평균 시간을 예측함으로써, packet latency의 구성 요소들을 근사할 수 있다.
queuing theory 전체를 다루는 것은 이 책의 범위를 넘지만, 이 절에서는 queuing theory의 기본 개념을 소개하고 이를 단순한 interconnection network 분석에 어떻게 적용할 수 있는지 설명한다. 보다 자세한 내용은 queuing theory 전문 서적 [99]을 참고하라.
그림 23.8은 기본적인 큐잉 시스템을 보여준다.

source는 초당 λ개의 packet을 생성한다. 이 packet들은 service를 기다리며 큐에 저장된다. server는 큐에서 순차적으로 packet을 꺼내 평균 T초의 시간 동안 처리하며, 평균 처리율은 μ = 1/T packet/초이다.
interconnection network에서의 packet source는 terminal에서 packet을 주입하거나 다른 node로부터 packet을 전달하는 channel이다. arrival rate λ는 input terminal에서 들어오는 traffic rate이거나, 네트워크 channel에 들어오는 traffic의 superposition일 수 있다. server는 네트워크에서 packet을 제거하는 terminal이거나, packet을 다른 node로 운반하는 channel이다. 두 경우 모두 service time T는 packet이 channel 또는 terminal을 통과하는 시간이며, packet 길이에 비례하므로 T = L/b로 표현된다.
Markov Chain을 이용한 모델링
분석을 단순화하기 위해, 우리는 현실과 다르다는 것을 알고 있으면서도 몇 가지 가정을 한다.
- 큐는 무한 길이를 가진다고 가정
- packet 간 도착 시간(inter-arrival time)과 service time은 exponential distribution을 따른다고 가정
exponential process는 memoryless라고도 하며, 새 이벤트(예: packet 도착)가 발생할 확률이 과거 이벤트에 영향을 받지 않는다. arrival과 service를 이렇게 단순화하면, queuing system을 Markov chain으로 모델링할 수 있다 (그림 23.9 참조).

그림 23.9의 Markov chain은 큐의 상태 전이를 나타낸다. 각 원은 큐의 상태를 나타내며, 해당 상태에서 큐에 존재하는 packet 수로 라벨링된다. packet은 λ의 속도로 큐에 도착하고, 이에 따라 상태는 오른쪽으로 전이된다. 반대로 packet이 큐에서 제거되면 μ의 속도로 왼쪽 상태로 전이된다.
정상 상태에서는 어떤 상태로 들어오는 속도와 나가는 속도가 같아야 한다.
예를 들어 상태 p₀에 대해서는 다음과 같다:


기대 queue 길이 및 대기 시간
각 상태의 확률을 구했으므로, 큐에 있는 평균 entry 수(기대 queue 길이)는 다음과 같다:
E(NQ)=∑i=0∞ipi=ρ/(1−ρ)E(N_Q) = ∑_{i=0}^{∞} i p_i = ρ / (1 - ρ)
즉, 도착한 packet은 앞서 있는 packet들을 기다려야 하므로 평균 대기 시간은 다음과 같이 계산된다:
E(TW)=T×E(NQ)=Tρ/(1−ρ)=ρμ(1−ρ)E(T_W) = T × E(N_Q) = Tρ / (1 - ρ) = \frac{ρ}{μ(1 - ρ)}
이 관계는 Little's law로 알려져 있다.
분산 및 다른 queue 유형
queue entry 수의 분산(variance)은 다음과 같다:
Var(NQ)=E(σNQ2)=ρ/(1−ρ)2Var(N_Q) = E(σ^2_{N_Q}) = ρ / (1 - ρ)^2
우리는 지금 M/M/1 queuing system에 대해 계산하였다. 이는 도착 및 서비스 시간이 exponential distribution을 따르며 server가 1개인 시스템이다.
다음은 기타 queue 유형과 비교한 결과:
- M/D/1 (deterministic service time)의 경우:
E(NQ)=ρ2(1−ρ)E(N_Q) = \frac{ρ}{2(1 - ρ)}
- M/G/1 (general service time)의 경우:
E(NQ)=λ2X22(1−ρ)E(N_Q) = \frac{λ^2 X^2}{2(1 - ρ)}
여기서 X²는 service time의 두 번째 모멘트이다. 많은 네트워크에서는 packet 길이, 즉 service time이 일정하거나 거의 일정하기 때문에, 일반적으로 위 식 (23.8) 또는 (23.9)를 사용하는 것이 식 (23.5)보다 더 적절하다.
주의할 점은, λ ≥ μ 또는 ρ ≥ 1인 경우 위 식들이 무효라는 것이다. 이때 latency는 무한이 되며, 위 식들은 음수를 반환하므로 적용할 수 없다.
네트워크 모델 예시: Butterfly Network

그림 23.10은 queuing theory를 사용하여 4-terminal butterfly network를 모델링하는 예를 보여준다.
- (a): 2-ary 2-fly 네트워크가 uniform traffic을 전달
- (b): 이를 queuing system으로 모델링
각 source는 λ 속도의 packet stream을 생성하는 source로, 각 destination은 service rate μ를 가지는 server로 모델링된다.
각 2×2 switch는 splitter(입력), combiner(출력), 그리고 output queue 두 개로 구성된다.
- splitter는 λ rate의 입력을 λ/2씩 나누어 각 switch 출력으로 보낸다.
- 각 combiner는 입력 두 개로부터 λ/2 stream을 받아 λ rate로 output queue로 전달한다.
각 switch의 output queue는 combiner에 의해 합쳐진 traffic을 받아들인다. 이 큐는 내부 채널에 의해 μc 속도로 서비스되며, 마지막 단계에서는 terminal에 의해 μ 속도로 서비스된다.
이러한 switch model은 Poisson arrival process의 특성을 활용한다. 즉, exponential inter-arrival time을 갖는 stream을 나누면 여전히 exponential 특성을 유지하는 stream들이 생성된다.

23.2.2 Probabilistic Analysis
queuing theory를 보완하기 위해, 우리는 probabilistic analysis를 사용하여 buffer가 없는 네트워크 또는 네트워크 구성 요소를 분석한다.

Section 2.6에서 dropping flow control이 적용된 네트워크의 성능을 추정하기 위해 probabilistic analysis를 사용한 예제를 이미 살펴본 바 있다. 이 절에서는 blocking flow control을 사용하는 네트워크의 성능을 어떻게 추정하는지 보여준다.
예를 들어, 그림 23.12(a)와 같은 blocking flow control과 queuing이 없는 2×2 switch를 생각해 보자. 각 출력 포트의 service time은 같고, deterministic하며, To로 설정한다. 두 입력의 traffic rate는 동일하며, λ₁ = λ₂ = λ이고, 양쪽 입력에서 나오는 traffic은 두 출력에 대해 균일하게 분포되어 있다고 가정한다. 즉, λᵢⱼ = λ / 2 (∀i, j).
i₁ 입력 채널이 바쁜(busy) 시간 Ti를 계산하기 위해, 먼저 i₁에 들어온 packet이 대기해야 할 확률 Pw를 계산한다:
Pw=λTo2=ρo2P_w = \frac{λ T_o}{2} = \frac{ρ_o}{2}
여기서 ρₒ = λ To 는 출력 링크의 duty factor이다.
packet이 대기해야 하는 경우, 평균 대기 시간 Twc는 다음과 같다:
Twc=To2T_{wc} = \frac{T_o}{2}
이를 종합하면, 전체 packet에 대한 평균 대기 시간 Tw는:
Tw=PwTwc=λTo24=ρoTo4T_w = P_w T_{wc} = \frac{λ T_o^2}{4} = \frac{ρ_o T_o}{4}
결국 입력 채널의 busy 시간 Ti는 다음과 같다:
Ti=To+Tw=To(1+λTo4)=To(1+ρo4)T_i = T_o + T_w = T_o \left(1 + \frac{λ T_o}{4} \right) = T_o \left(1 + \frac{ρ_o}{4} \right)
이 식은 switch의 입력 측 busy 시간이 출력 링크의 duty factor에 비례해 증가함을 보여준다.
collision이 발생했을 때의 대기 시간 Twc는 service time의 분산에 큰 영향을 받는다. deterministic한 service time의 경우, 평균적으로 packet은 이미 처리 중인 packet의 중간 지점에서 도착하므로 Twc = To / 2가 된다. 만약 service time이 exponential 분포를 따른다면, 기대 대기 시간은 두 배로 증가하여:
Twc=To,Tw=λTo22=ρoTo2,Ti=To(1+ρo2)T_{wc} = T_o, \quad T_w = \frac{λ T_o^2}{2} = \frac{ρ_o T_o}{2}, \quad T_i = T_o \left(1 + \frac{ρ_o}{2} \right)
이처럼 service time의 분산이 커지면 대기 시간도 증가한다. 이는 긴 service time을 가진 packet들이 전체 busy 시간에서 더 많은 비율을 차지하기 때문이다. multistage network를 분석할 때는 각 단계마다 분산이 다를 수 있다. 예를 들어, 그림 23.12의 switch는 deterministic한 출력 service time을 갖지만, 여전히 non-zero variance를 가진다.
23.3 Validation
queuing theory, probabilistic analysis, 또는 simulation이 interconnection network의 성능을 얼마나 정확하게 예측할 수 있는지는 해당 분석에서 사용한 모델의 정확도에 달려 있다.
모델이 네트워크의 모든 관련 동작을 정확하게 반영한다면, 분석은 매우 정확해질 수 있으며, 넓은 설계 공간을 빠르게 탐색하거나 성능에 영향을 주는 요인을 이해하는 데 강력한 도구가 될 수 있다. 반면, 중요한 네트워크 특성을 누락하거나 부적절한 근사치를 사용하면 실제 네트워크 성능과 크게 다른 결과가 나올 수 있다. 시뮬레이션도 마찬가지로, 부정확한 모델은 부정확한 결과를 낳는다.
Validation은 analytic model 또는 simulation model이 실제로 정확한지를 검증하는 과정이다. 예를 들어, 실제 네트워크에서 측정한 latency vs. offered traffic 데이터를 보유하고 있다면, 이를 사용해 simulation 또는 analysis 결과와 비교해 볼 수 있다. 결과가 일치하면 해당 모델이 중요한 요소들을 정확히 반영하고 있다고 판단할 수 있으며, 유사한 네트워크나 조건에서도 정확할 가능성이 높다.
실험 데이터가 없는 경우, 신뢰할 수 있는 simulation 결과를 기준으로 analytic model을 검증할 수도 있다. 그림 23.11은 이런 방식의 validation 예시다.
모델을 검증하려면 다양한 동작 지점과 네트워크 구성에서의 결과를 대표적인 데이터와 비교해야 한다. 특정 하나의 지점에서 모델이 정확하다고 해서, 매우 다른 조건에서도 정확할 것이라고 단정할 수는 없다. 예를 들어, zero-load latency를 정확히 예측한다고 해서 saturation 근처의 latency를 정확히 예측한다고 보장할 수는 없다.
23.4 사례 연구: BBN Monarch Network의 효율성과 손실
BBN Advanced Computer Systems는 Butterfly TC-2000 (Section 4.5)을 계승한 시스템으로 BBN Monarch [156]를 설계했다. Monarch는 많은 흥미로운 구조적 특징을 포함하고 있었지만, 결국 완성되지 못했다.
Monarch는 uniform-memory-access shared memory 시스템이었다. 최대 64K개의 processor가 butterfly-like 네트워크를 통해 N개의 memory module에 접근했다. 이 네트워크는 다음과 같은 특징을 가지고 있었다:
- dropping flow control 사용
- 목적지 memory module을 무작위화하기 위한 hashed memory address
- hot-spot traffic 처리를 위한 access combining 기법
접근은 동기적(synchronous)으로 이루어졌는데, 이는 combining을 단순화하기 위한 목적이었다. 시간은 frame으로 나뉘며, 각 processor는 frame 시작 시 1회의 memory access를 수행할 수 있었다. 같은 frame 내에서 같은 위치로 접근하는 요청들은 네트워크 내부 노드에서 결합(combine) 되어 단일 access packet으로 memory module로 전달되었다.
Monarch 네트워크는 그림 23.13과 같이 switch와 concentrator 단계를 번갈아 배치하여 구성되었다.
- 각 switch는 최대 12개의 입력과 32개의 출력을 가졌으며, 최대 4비트의 주소를 해석할 수 있었다.
- switch의 출력 포트는 그룹 단위로 구성되어, 같은 방향으로 여러 packet이 동시에 전송될 수 있도록 했다.
예를 들어, 하나의 switch는 2포트씩 16개의 출력 그룹, 또는 4포트씩 8개의 출력 그룹으로 구성할 수 있었다.
packet은 switch의 어떤 입력 포트로 도착하든, 구성된 출력 그룹 내의 어떤 포트를 통해도 전송이 가능했다.

그림 23.13에 보이는 BBN Monarch 네트워크(1990)는 switch와 concentrator를 번갈아 배치한 stage들로 구성되어 있다. 각 stage에서의 concentration ratio는 효율성을 극대화하고 dropping flow control로 인한 손실을 최소화하기 위해 조정되었다. 각 채널은 직렬(serial) 방식으로 작동하며, 대역폭은 350 Mbit/s였다.
각 packet은 요청한 출력 그룹의 어느 채널이든 하나를 얻을 수 있으면 다음 stage로 진행했다. 그렇지 못하면 drop되었다.
Concentrator는 여러 개의 lightly loaded 채널을 더 적은 수의 heavily loaded 채널로 multiplexing하는 역할을 한다. 예를 들어, 여러 패키징 단계를 거쳐야 하는 고비용 채널 전에 이를 사용하는 방식이다.
- 각 concentrator 칩은 최대 32개의 입력과 12개의 출력을 지원한다.
- 모든 입력과 출력은 동등하며, 매 frame마다 32개 입력 중 어떤 12개에서든 도착한 최대 12개의 packet만이 출력으로 라우팅된다.
- 추가로 도착한 packet은 drop된다.
손실 확률 계산
probabilistic analysis를 이용하여 Monarch 네트워크 각 단계에서의 packet 손실 확률을 계산할 수 있다. 다음의 가정을 사용한다:
- 모든 입력 채널은 균일하게 load됨
- traffic은 출력에 대해 균일하게 분포됨
- address hashing과 access combining이 이 가정을 현실적으로 만들어 줌
어떤 switch가 I 개의 입력, G 개의 출력 그룹, 그리고 각 그룹당 C개의 채널을 가질 때, 입력 duty factor가 Pi라고 하자. 특정 입력 i가 특정 출력 그룹 j를 요청할 확률은 다음과 같다:
Pij=PiGP_{ij} = \frac{P_i}{G}
이때, k개의 입력이 같은 출력 j를 요청할 확률은 이항 분포를 따른다:
Pk=(Ik)(PiG)k(1−PiG)I−kP_k = \binom{I}{k} \left( \frac{P_i}{G} \right)^k \left( 1 - \frac{P_i}{G} \right)^{I - k}
출력 채널 j가 busy할 확률 Po는, k ≤ C인 경우에 대해 다음과 같이 계산된다.
k개의 요청 중 (C - k)/C 비율만큼은 채널이 idle이므로:
Po=1−∑k=0C−1(C−kC)PkP_o = 1 - \sum_{k=0}^{C-1} \left( \frac{C - k}{C} \right) P_k
이를 정리하면:
Po=1−∑k=0C−1(C−kC)(Ik)(PiG)k(1−PiG)I−k(23.14)P_o = 1 - \sum_{k=0}^{C-1} \left( \frac{C - k}{C} \right) \binom{I}{k} \left( \frac{P_i}{G} \right)^k \left( 1 - \frac{P_i}{G} \right)^{I - k} \tag{23.14}
효율성과 손실 계산
각 단계의 efficiency는 출력 traffic의 총합을 입력 traffic의 총합으로 나눈 값이다:
P(transmit)=GCPoIPi(23.15)P(\text{transmit}) = \frac{G C P_o}{I P_i} \tag{23.15}
손실률은 다음과 같다:
P(drop)=1−P(transmit)=1−GCPoIPi(23.16)P(\text{drop}) = 1 - P(\text{transmit}) = 1 - \frac{G C P_o}{I P_i} \tag{23.16}
표 23.1은 64K 포트를 갖는 Monarch 네트워크의 구성과 손실 분석 결과를 보여준다.
각 stage마다 식 (23.14)를 사용해 Po를 계산하고, 이 값을 다음 단계의 Pi로 사용하여 efficiency 및 손실률을 계산한다.
| Switch 1 | 8 | 16 | 2 | 1.00 | 0.977 | 0.023 |
| Concentrator 1 | 32 | 1 | 12 | 0.24 | 0.993 | 0.007 |
| Switch 2 | 12 | 16 | 2 | 0.65 | 0.975 | 0.025 |
| Concentrator 2 | 32 | 1 | 12 | 0.24 | 0.995 | 0.005 |
| Switch 3 | 12 | 8 | 3 | 0.63 | 0.986 | 0.014 |
| Switch 4 | 12 | 16 | 2 | 0.62 | 0.977 | 0.023 |
| TOTAL | 0.907 | 0.093 |
결과적으로 이 네트워크는 100% input load에서도 손실률 10% 미만을 달성할 수 있다.
단, 그 대가로 링크를 과도하게 구성하여 각 switch의 입력은 65% 미만, 각 concentrator의 입력은 25% 미만만 사용하도록 설계되었다. 이와 관련된 duty factor와 loss 간의 관계는 연습문제 23.7에서 탐구한다.
버퍼링의 영향
버퍼를 추가하면 output이 바쁠 때 packet을 drop하지 않고 대기시킬 수 있으므로 손실을 줄일 수 있다.
버퍼는 있지만 backpressure가 없는 경우, 모든 output이 busy하고 모든 버퍼가 가득 찼을 때만 packet이 drop된다. Monarch와 유사한 네트워크에 대해 buffering이 있는 경우의 분석은 연습문제 23.9에서 다룬다.
23.5 참고 문헌
- queuing theory의 일반적인 참고 문헌: Kleinrock [99]
- 네트워크에 특화된 모델링 기법: Bertekas [20]
- 네트워크의 probabilistic 분석 예시: Dally [46], Agarwal [2]
- 부분적으로 차 있는 유한 큐에 대한 분석 모델: Dally [47]
- k-ary n-cube 네트워크에서 deadlock에 대한 모델링: Pinkston and Warnakulasuriya [152]
23.6 연습문제
각 문제는 앞서 배운 개념과 분석 기법을 실제 적용해보는 연습이다.
(간략 정리)
- 23.1: 그림 23.10의 트래픽을 비균일하게 수정하여 latency vs. offered traffic 곡선 계산
- 23.2: 4:1 concentrator에서 over-subscription 확률과 average queuing delay 계산
- 23.3: dropping flow control의 queuing 모델 유도
- 23.4: 2-ary 3-fly 회로 스위칭 네트워크의 expected throughput 계산
- 23.5~23.6: k 입력 스위치 및 임의 traffic matrix에 대한 확률적 모델링 확장
- 23.7~23.8: Monarch 네트워크의 duty factor, cost와 loss 간의 관계 그래프화
- 23.9: 버퍼가 추가된 Monarch 네트워크에서 dropping 확률 계산 (F=8인 경우)
- 23.10~23.12: 위 문제들에 대한 simulation 수행 및 모델과의 비교 분석
'System-on-Chip Design > NoC' 카테고리의 다른 글
| Simulation Example (3) | 2025.06.16 |
|---|---|
| Simulation (2) | 2025.06.16 |
| Buses (0) | 2025.06.16 |
| Error Control (0) | 2025.06.16 |
| Network Interfaces (0) | 2025.06.16 |