이 장에서는 간단한 interconnection network의 구조와 설계를 살펴보며 전체적인 개요를 제공한다. 가장 단순한 형태의 네트워크인 butterfly network with dropping flow control을 다룬다. 이 네트워크는 비용이 많이 들지만, interconnection network 설계의 주요 개념을 강조하는 데 유용하다. 이후 장에서는 더 효율적이고 실용적인 네트워크를 만드는 방법을 다룰 것이다.
2.1 Network Specifications and Constraints
모든 공학적 설계 문제와 마찬가지로, 네트워크 설계는 무엇을 만들고 싶은지를 정의하는 사양(specifications)과 가능한 해법의 범위를 제한하는 제약조건(constraints)에서 출발한다. 이 장에서의 예제 네트워크 사양은 아래의 Table 2.1에 요약되어 있다. 네트워크의 크기(64개의 포트)와 포트당 요구되는 bandwidth가 포함된다. 테이블에서 보이듯, peak bandwidth와 average bandwidth가 같으며, 이는 입력이 0.25 Gbyte/s의 속도로 지속적으로 메시지를 inject한다는 것을 의미한다. 각 입력이 각 출력을 동일한 확률로 선택하는 random traffic이 예상되며, 메시지 크기는 4~64 bytes이다. 또한 QoS와 신뢰성 사양은 packet drop을 허용한다. 즉, 모든 packet이 목적지에 반드시 전달될 필요는 없다. 이는 flow control 구현을 단순하게 만들어준다. 실제 시스템에서는 dropped packet의 비율과 조건 등을 명시한 더 상세한 QoS 사양이 포함되겠지만, 여기서는 설계 개념을 설명하는 데 이 정도면 충분하다.
예제 네트워크 설계의 제약조건은 Table 2.2에 정리되어 있다. 이 제약은 각 수준의 패키징(capacity and cost)을 정의한다. 네트워크는 chip들로 구성되고, chip은 circuit board에 실장되며, board는 cable로 연결된다. 제약조건은 각 계층에서 module interface를 통해 전송할 수 있는 signal 수와 각 module의 비용을 지정한다. cable의 경우, bandwidth 감소 없이 도달할 수 있는 최대 거리도 명시되어 있다.
- signal은 반드시 pin을 의미하지는 않는다. 예를 들어, differential signaling에서는 signal당 두 개의 핀이 필요하다.
- bandwidth × distance² (Bd²)가 일정한 케이블의 특성상, 2배 길이로 전송할 경우 bandwidth는 4분의 1로 줄어든다.
Table 2.1 Example Network Specifications
| Input ports | 64 |
| Output ports | 64 |
| Peak bandwidth | 0.25 Gbyte/s |
| Average bandwidth | 0.25 Gbyte/s |
| Message latency | 100 ns |
| Message size | 4–64 bytes |
| Traffic pattern | random |
| Quality of service | dropping acceptable |
| Reliability | dropping acceptable |
Table 2.2 Example Network Constraints
| Port width | 2 bits |
| Signaling rate | 1 GHz |
| Signals per chip | 150 |
| Chip cost | $200 |
| Chip pin bandwidth | 1 Gbit/s |
| Signals per board | 750 |
| Board cost | $200 |
| Signals per cable | 80 |
| Cable cost | $50 |
| Cable length limit | 4 m at 1 Gbit/s |
2.2 Topology
예제 네트워크는 단순화를 위하여 butterfly topology를 갖는다. 하나의 입력 포트 입장에서 보면, butterfly는 tree처럼 보인다(Figure 2.1 참고). 각 단계(level)는 switching node로 구성되며, 이들은 terminal node와 달리 packet을 보내거나 받지 않고 전달만 한다. 또한 channel은 unidirectional로, 화살표 방향(입력에서 출력, 왼쪽에서 오른쪽)으로 흐른다. topology로 butterfly를 선택했지만, 이는 아직 설계의 절반이다. network의 speedup, butterfly의 radix, 그리고 topology의 패키징 맵핑을 결정해야 한다.

speedup은 network의 총 입력 bandwidth와 이상적인 network capacity의 비율이다. 여기서 capacity는 이상적인 라우팅과 flow control이 있다고 가정했을 때 가능한 최대 throughput이다. speedup이 1이면, 입력 요구량과 네트워크가 제공할 수 있는 용량이 일치한다는 의미이다. 더 큰 speedup을 제공하면 여유(margin)가 생기며 비이상적 상황에 대응할 수 있다. 이는 건축의 안전계수(safety factor) 개념과 유사하다.
butterfly에서 각 channel의 bandwidth를 입력 포트와 동일하게 설계하면 speedup은 1이 된다. random traffic에서는 각 입력이 모든 출력에 균등하게 보내기 때문에, 모든 channel은 동일한 수요를 받는다. 본 예제에서는 각 channel이 0.25 Gbyte/s의 bandwidth를 갖는다. 하지만, 단순성을 위해 speedup 8을 선택한다. 이는 매우 큰 수치지만(브루클린 브리지는 safety factor 6), 이후에는 이 수치를 줄이는 법을 배운다.
speedup과 패키징 제약조건을 고려하여, 각 switch node의 입력/출력 수(radix)가 결정된다. 예를 들어, Figure 2.1의 butterfly는 radix 2이다. 하나의 switch node는 chip 하나에 구현되며, chip당 총 signal 수는 150을 넘지 않아야 한다. speedup 8을 구현하려면 8 × 0.25 = 2 Gbyte/s의 channel bandwidth가 필요하고, 이는 1 Gbit/s의 signal 16개를 사용하여 구성된다. 여기에 overhead signal 2개를 더하면, channel은 18 signal로 구성되며, chip당 150/18 ≈ 8개의 channel만 탑재 가능하다. 따라서 radix-4 butterfly, 즉 입력/출력 4개씩을 가지는 switch node를 선택한다.
64개의 출력 포트에 연결하려면 log₄64 = 3 단계의 switch node가 필요하다. 따라서 이 네트워크는 radix-4, 3-stage butterfly, 즉 4-ary 3-fly이다. 전체 topology는 Figure 2.2에 나와 있다. Figure 2.1의 확장판이며, input 1에서 시작해 64개의 출력으로 향하는 경로는 여전히 tree 형태이며, tree의 degree는 radix인 4이다.
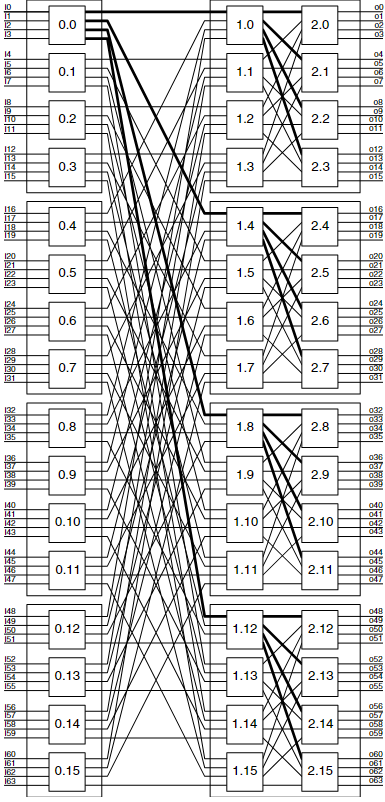
topology 설계의 마지막 단계는 패키징이다. 이미 각 switch node를 chip 하나로 배치하기로 결정했다. radix를 chip 제약조건에 맞춰 정했기 때문에, chip은 설계 제약을 충족한다. 이제 이 chip을 board에 실장해야 하며, 비용을 최소화하기 위해 한 board에 가능한 많은 chip을 넣고 싶다. 하지만 board당 signal 수는 750을 초과할 수 없다. 이는 커넥터 한쪽 면을 통해 보낼 수 있는 최대 signal 수, 즉 connector density × 길이에 의해 결정된다.
유효한 board 간 partitioning은 Figure 2.2에 표시되어 있으며, 각 board의 경계는 점선 상자로 나타나 있다. 첫 번째 stage는 4개의 board에, board당 4개의 chip으로 배치된다. 다음 두 stage는 4개의 board에, board당 8개의 chip으로 배치된다. 각 board에는 18 signal로 구성된 channel이 32개 입출력되며, 총 32 × 18 = 576 signals로 제약을 만족한다.
각 board에는 총 32개의 channel이 존재하며, 각 channel은 18개의 signal을 사용하므로 총 576 signal이 필요하다. 이는 750 signal 제한 내에 충분히 들어간다. 날카로운 독자는 첫 번째 stage의 board에 router chip 5개를 실을 수도 있다고 생각할 수 있다(40개 channel, 즉 720 signals). 하지만 그렇게 하더라도 여전히 4개의 첫 번째 stage board가 필요하므로 비효율적이다. 또한 두 번째 stage의 board에 router chip 10개를 실을 수는 없다. 필요한 46개 채널은 총 828 signal이 되며, board의 pinout을 초과하기 때문이다.
마지막으로, board 간 연결은 Figure 2.3에서 보듯이 cable을 통해 이루어진다. 그림의 굵은 회색 선 하나는 하나의 cable을 나타내며, 이는 하나의 circuit board에서 다른 board로 18-bit channel 4개를 전달한다. 8개의 circuit board는 이런 cable 16개로 연결된다. 즉, 각 첫 번째 stage board에서 두 번째 및 세 번째 stage board로 각각 cable을 연결한다. 이 8개의 board가 하나의 chassis 내에 배치되므로 cable의 길이는 제약 내에 있다.

한 걸음 물러서서 보면, 이 topology에서 어떻게 모든 입력을 모든 출력에 연결할 수 있는지 확인할 수 있다. 첫 번째 stage의 switch는 나머지 stage가 있는 4개의 circuit board 중 하나를 선택한다. 두 번째 stage는 선택된 board 내의 4개의 chip 중 하나를 선택한다. 마지막 stage는 원하는 출력 포트를 선택한다. 이러한 분할 정복(divide-and-conquer) 구조는 패킷을 라우팅할 때 효율적으로 사용된다.
2.3 Routing
우리의 단순한 butterfly network는 destination-tag routing을 사용한다. 이는 destination address의 비트를 이용해 네트워크의 각 단계에서 출력 포트를 선택하는 방식이다.
64개의 노드를 갖는 이 네트워크에서 destination address는 6비트이다. 각 switch는 이 중 2비트(dibit)를 사용하여 4개의 출력 중 하나를 선택하고, 이는 남은 노드 집합의 1/4로 라우팅된다.
예를 들어, 입력 포트 12에서 출력 노드 35 (= 100011₂)로 패킷을 보내는 경우를 보자. 가장 상위 dibit인 10은 switch 0.3의 세 번째 출력 포트를 선택하여 패킷을 switch 1.11로 보낸다. 그 다음 중간 dibit 00은 switch 1.11의 첫 번째 출력 포트를 선택하여 패킷을 switch 2.8로 보낸다. 마지막으로 가장 하위 dibit 11은 switch 2.8의 마지막 출력 포트를 선택하여 출력 포트 35로 패킷을 전달한다.
이러한 출력 포트 선택 순서는 입력 포트와 무관하다. 예를 들어, 입력 포트 51에서 출력 포트 35로 보내도 같은 선택 순서를 따른다. 즉, 라우팅 알고리즘은 패킷과 함께 destination address만 저장하면 된다.
일관성을 위해, 모든 switch node는 destination address의 가장 상위 dibit만 참조한다. 그런 다음, 패킷이 node를 떠나기 전에 address는 왼쪽으로 2비트 shift되어 방금 사용한 bit는 제거되고 다음 dibit이 상위 위치로 올라온다. 예를 들어, node 35로 라우팅을 시작할 때 address 100011₂는 shift 되어 001100₂이 된다.
이러한 convention 덕분에 모든 switch node가 동일한 방식으로 동작할 수 있고, 특별한 설정 없이도 사용 가능하다. 또한, address field의 크기만 확장하면 더 많은 노드를 가지는 네트워크로 확장할 수 있다.
2.4 Flow Control
이 네트워크의 각 채널은 한 cycle당 16-bit의 physical digit, 즉 phit을 전달한다. 그러나 네트워크는 32~512bit 크기의 전체 패킷을 전달해야 하므로, Figure 2.4에 제시된 간단한 프로토콜을 사용하여 여러 phit을 packet으로 조립한다.
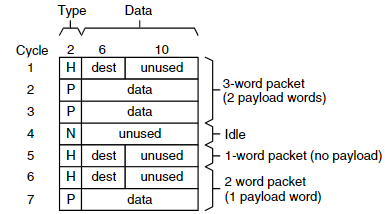
각 packet은 header phit으로 시작하고, 그 뒤에 0개 이상의 payload phit가 따라온다. header phit은 새로운 packet의 시작을 나타내며, 라우팅 알고리즘에 사용될 destination address도 포함한다. payload phit은 실제 데이터를 담고 있으며, 16-bit 단위로 나뉜다.
하나의 packet을 구성하는 phit은 연속적이어야 하며, 중간에 끊기지 않아야 한다. 단, packet 사이에는 얼마든지 null phit이 있을 수 있다. 각 16-bit word가 header인지 payload인지 또는 null인지 구별하기 위해, 각 채널에 2-bit type field를 추가로 붙인다.
이 field는 다음과 같은 역할을 한다:
- H: Header
- P: Payload
- N: Null
따라서 각 packet은 하나의 H word와 그 뒤를 따르는 0개 이상의 P word, 그리고 0개 이상의 N word로 구성된다. 이를 정규 표현식으로 표현하면 (HP*N*)* 형식이다. 즉, link 위에는 여러 개의 packet이 흐를 수 있으며, 각 packet은 위의 구조를 갖는다.
이제 phit을 packet으로 조립했으니, flow control의 핵심, 즉 packet에 자원을 할당하는 과정으로 넘어간다. 단순화를 위해, 우리의 butterfly network는 dropping flow control을 사용한다. 패킷이 switch에 도달했을 때 필요한 output port가 사용 중이면, 해당 packet은 drop (폐기)된다. 이러한 flow control은 end-to-end error control protocol이 존재함을 가정하고 있다.
Figure 2.4는 네트워크에서 사용되는 packet format을 보여준다. 세로 방향은 시간(cycle)을, 가로 방향은 채널의 18개 signal을 나타낸다. 왼쪽 2개 signal은 phit type (H, P, N)을 담고, 나머지 16개 signal은 destination address 또는 data를 담거나 null일 경우 비워진다.
Table 2.3은 이 네트워크에서 사용하는 phit type의 encoding을 보여준다:
| H | 11 |
| P | 10 |
| N | 00 |
패킷을 재전송하는 역할은 상위의 end-to-end error control protocol이 담당할 것으로 가정한다. 패킷을 drop하는 것은 가장 비효율적인 flow control 방식 중 하나이다. 패킷 손실률이 높고, 결국 drop되는 패킷에 채널 bandwidth를 낭비하게 된다. 이보다 훨씬 나은 flow control 기법들이 있으며, Chapter 12에서 다룬다. 그러나 이 장에서는 개념과 구현이 매우 단순하기 때문에 dropping flow control이 적합하다.
2.5 Router Design
butterfly network의 각 switching node는 router로, 입력으로부터 패킷을 받고, 라우팅 알고리즘에 따라 목적지를 결정한 후, 적절한 출력으로 패킷을 전달한다. 지금까지의 설계 결정은 매우 단순한 router를 가능하게 한다.

Figure 2.5는 router의 block diagram이다. 이 router의 datapath는 다음으로 구성된다:
- 18-bit input register 4개
- 18-bit 4:1 multiplexer 4개
- routing field를 shift하는 shifter 4개
- 18-bit output register 4개
총 144-bit의 register와 약 650개의 2-input NAND gate에 해당하는 회로가 사용된다.
phit은 매 cycle마다 input register에 도착하며, 모든 multiplexer로 전달된다. 각 multiplexer에서 연결된 allocator는 각 phit의 type과 header phit의 next hop field를 검사하고 switch를 설정한다.
선택된 입력의 phit은 이후 shifter로 전달된다. allocator의 제어 하에, header phit은 routing field를 왼쪽으로 2비트 shift하여 현재 field를 제거하고 다음 field를 노출한다. payload phit은 변경 없이 그대로 전달된다.
router의 제어는 전적으로 4개의 allocator에 의해 이루어진다. 이들은 각 출력 포트를 제어하며 multiplexer와 shifter를 조작한다. allocator는 4개의 입력 중 하나에 출력 포트를 할당한다.
Allocator 구성 (Figure 2.6)

각 allocator는 거의 동일한 구조의 bit slice 4개로 구성되며, 각 slice는 다음 세 영역으로 나뉜다:
- Decode
- 각 입력 phit의 상위 4비트를 해독한다.
- request_i: 입력 i의 phit이 header이고, route field의 상위 2비트가 현재 출력 포트 번호와 일치하면 true
- payload_i: 입력 i의 phit이 payload이면 true
- Arbitrate
- 4-input fixed-priority arbiter를 사용한다.
- 요청 신호 중 첫 번째(위쪽부터)의 입력에 grant를 부여한다.
- grant 시, 해당 입력을 multiplexer에서 선택하도록 select 신호를 활성화
- header가 통과하면 shift 신호도 활성화되어 routing field를 shift함
- Hold
- 동일한 packet의 payload가 따라오는 동안, 출력을 해당 입력에 고정
- last_i는 이전 cycle에 선택된 입력을 기억
- 이번 cycle에도 payload가 입력되면, hold_i를 활성화하고 avail을 비활성화하여 새로운 header의 할당을 막는다
Note: 실제 시스템에서는 fixed-priority arbiter는 사용하지 않는다. 불공정성과 livelock 또는 starvation 문제를 유발하기 때문이다. Chapter 18과 19에서 더 나은 arbitration 방법들을 다룬다.
Verilog RTL 모델 (Figure 2.7)
아래는 Figure 2.6의 allocator를 Verilog로 구현한 것이다.

- 각 입력 phit에서 routing 정보와 type 정보를 해석
- 현재 출력 포트(thisPort)에 맞는 입력을 선택
- payload가 이어질 경우 hold 상태 유지
- shift 제어 신호를 통해 header field를 업데이트
- 고정 우선순위 방식으로 grant 결정
Verilog는 텍스트 기반으로 하드웨어를 기술할 수 있는 편리한 방법이며, simulation 및 synthesis input 언어로도 사용 가능하다. 따라서 이 방식으로 기술한 후 simulation으로 동작을 검증하고, ASIC 또는 FPGA를 위한 gate-level 디자인으로 synthesis할 수 있다.
// simple four-input four output router with dropping flow control
module simple_router(clk,i0,i1,i2,i3,o0,o1,o2,o3) ;
input clk ; // chip clock
input [17:0] i0,i1,i2,i3 ; // input phits
output [17:0] o0,o1,o2,o3 ; // output phits
reg [17:0] r0,r1,r2,r3 ; // outputs of input registers
reg [17:0] o0,o1,o2,o3 ; // output registers
wire [17:0] s0,s1,s2,s3 ; // output of shifters
wire [17:0] m0,m1,m2,m3 ; // output of multiplexers
wire [3:0] sel0, sel1, sel2, sel3 ; // multiplexer control
wire shift0, shift1, shift2, shift3 ; // shifter control
// the four allocators
alloc a0(clk, 2’b00, r0[17:14], r1[17:14], r2[17:14], r3[17:14], sel0, shift0) ;
alloc a1(clk, 2’b01, r0[17:14], r1[17:14], r2[17:14], r3[17:14], sel1, shift1) ;
alloc a2(clk, 2’b10, r0[17:14], r1[17:14], r2[17:14], r3[17:14], sel2, shift2) ;
alloc a3(clk, 2’b11, r0[17:14], r1[17:14], r2[17:14], r3[17:14], sel3, shift3) ;
// multiplexers
mux4_18 mx0(sel0, r0, r1, r2, r3, m0) ;
mux4_18 mx1(sel1, r0, r1, r2, r3, m1) ;
mux4_18 mx2(sel2, r0, r1, r2, r3, m2) ;
mux4_18 mx3(sel3, r0, r1, r2, r3, m3) ;
// shifters
shiftp sh0(shift0, m0, s0) ;
shiftp sh1(shift1, m1, s1) ;
shiftp sh2(shift2, m2, s2) ;
shiftp sh3(shift3, m3, s3) ;
// flip flops
always @(posedge clk)
begin
r0=i0 ; r1=i1 ; r2=i2 ; r3=i3 ;
o0=s0 ; o1=s1 ; o2=s2 ; o3=s3 ;
end
endmodule
2.6 Performance Analysis
dropping flow control에서는 성능 지표들이 패킷이 drop될 확률에 크게 영향을 받는다.
네트워크 모델 (Figure 2.9)
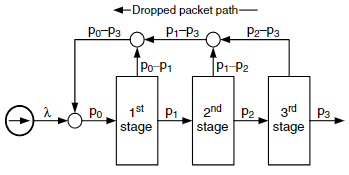
Dropped packet을 재전송한다고 가정하고, 간단한 모델로 분석을 시작한다.
입력과 출력 사이의 대칭성, random traffic 패턴 때문에, 하나의 입력만 고려하면 충분하다.
- 패킷은 λ의 비율로 네트워크에 주입된다.
- λ는 2 Gbyte/s 채널 대역폭으로 정규화되어 있으며, λ = 1은 최대 속도 의미.
- 재전송되는 패킷도 합쳐져서 p₀라는 총 주입률이 된다.
각 단계에서:
- 일부 패킷은 충돌로 drop됨.
- 다음 단계로 통과하는 비율은 p₁, p₂, p₃.
- drop된 패킷은 입력으로 다시 돌아가며 재전송됨.
수식 (Equation 2.2)
네트워크의 각 stage i에서 다음 stage의 출력률 pᵢ₊₁은 다음과 같다:
pi+1=1−(1−pi4)4p_{i+1} = 1 - \left(1 - \frac{p_i}{4} \right)^4
입력 λ = 0.125 (speedup = 8)일 때, 각 stage 출력은:
- p₁ = 0.119
- p₂ = 0.114
- p₃ = 0.109
즉, 입력이 0.125일 때 실제 throughput은 0.109이며, 0.016(=12.6%)는 drop된다.
재전송의 피드백
drop된 패킷의 재전송은 전체 입력률 p₀를 증가시키고, 이는 또 drop률을 높인다. 이 과정이 안정되면, 다음 조건이 성립한다:
- 안정 조건: p₀ ≤ 1
- 최종적으로 p₃ = λ 이면 수렴
Throughput 곡선 (Figure 2.10)

Figure 2.10은 injection rate에 따른 throughput을 보여준다.
- 낮은 부하: throughput ≈ injection rate
- 높은 부하: drop이 심해져 throughput 감소
- 포화(saturation): 최대 throughput은 0.432 (43.2%)
- 재전송을 하든 안 하든, 이 이상은 낼 수 없다.
따라서 이 네트워크는 speedup 2.5 이상이면 충분하지만, latency 개선을 위해 speedup 8을 선택한 것이다.
dropping flow control이 실제 사용되지 않는 이유는 바로 이 throughput의 비효율성 때문이다.
Chapter 12에서는 채널 대역폭의 90% 이상을 효율적으로 사용하는 flow control 기법들을 소개한다.
Latency 모델

latency도 channel capacity 기준으로 정규화한다.
패킷이 drop 없이 네트워크를 통과할 때는 6-cycle의 지연이 있다. 이를 relative latency = 1.0으로 정의.
하지만 drop되는 패킷은 다시 전송되며, latency가 누적된다.
- drop 비율 pᴰ:PD=p0−p3p0P_D = \frac{p_0 - p_3}{p_0}
- 평균 latency T는 다음 수식으로 계산:
T=∑i=0∞(i+1)PDi(1−PD)=11−PD=p0p3T = \sum_{i=0}^\infty (i+1) P_D^i (1 - P_D) = \frac{1}{1 - P_D} = \frac{p_0}{p_3}
(Figure 2.11에 그래프 있음)
- throughput이 0.39일 때 latency는 2배가 된다.
- throughput이 0.43에서 포화, 그 이상은 latency 증가만 발생
실제 시스템에서는 drop을 즉시 감지하고 6 cycle 내에 재전송하는 것은 비현실적이다.
재전송 패킷과 신규 패킷이 충돌할 가능성이 증가하므로, queueing delay도 고려해야 한다.
Figure 2.11은 queueing이 포함된 latency 곡선도 함께 보여준다. 이 곡선은 포화에 가까워질수록 무한대로 증가하는 전형적인 interconnection network의 형태를 갖는다.
Figure 2.11은 offered traffic (injection rate)에 따른 relative latency를 나타낸다.
실선은 본문에서 제시한 단순 모델을, 점선은 queueing delay를 고려한 모델을 나타낸다.
Equation 2.3과 Figure 2.11은 평균 latency만을 보여준다.
하지만 많은 응용에서는 평균뿐만 아니라 latency의 분포, 특히 최악의 latency나 **latency의 변동성(jitter)**이 중요하다.
예를 들어, 비디오 재생 시스템에서는 패킷을 재생 전에 저장하는 버퍼 크기는 평균 latency가 아니라 jitter에 의해 결정된다.
우리 예제 네트워크에서는, relative latency가 정확히 i가 될 확률은 다음과 같다:
P(T=i)=PDi−1(1−PD)P(T = i) = P_D^{i - 1} (1 - P_D)
이러한 지수 분포는 이론상 무한한 최대 latency와 무한한 jitter를 의미한다.
현실적으로는 전체 패킷 중 일정 비율(예: 99%)이 도달하는 데 걸리는 최대 지연 시간으로 jitter를 정의할 수 있다.
지금까지 논의된 성능 측정은 모두 uniform random traffic을 기준으로 한다.
butterfly network에서는 이것이 최상의 경우이다.
그러나, 예를 들어 bit-reversal과 같은 특정 traffic pattern에서는 성능이 훨씬 나빠질 수 있다.
bit-reversal traffic pattern:
이진 주소 {bₙ₋₁, bₙ₋₂, ..., b₀}를 가진 노드가 {b₀, b₁, ..., bₙ₋₁}를 목적지로 패킷을 보낸다.
이처럼 성능이 나빠지는 주요 원인은 각 입력에서 출력까지 경로가 단 하나이기 때문이다.
경로 다양성(path diversity)이 있는 네트워크는 이러한 부하 조건에서도 훨씬 좋은 성능을 보인다.
2.7 Exercises
2.1 Simple Network의 비용
Table 2.1과 2.2의 데이터를 이용하여 이 단순 네트워크의 비용을 계산하라.
2.2 전력 제한 조건 추가
board당 chip 개수를 6개로 제한하자. 이는 chip에 충분한 전력을 공급하고 열을 적절히 분산시키기 위함이다.
이 새로운 제약 조건을 포함하면서 기존 조건도 만족하는 packaging을 설계하라. 해당 packaging의 비용은?
2.3 공정한 allocator
Figure 2.7에 제시된 Verilog allocator 코드를 수정하여 더 공정한 arbitration을 구현하라.
시뮬레이션을 통해 새 allocator를 검증하고 설계를 설명하라.
2.4 router의 degree 확장
simple router를 4×4가 아닌 5×5 switch로 확장한다면, 이를 2-D mesh 또는 torus network 구현에 사용할 수 있다.
router와 packet format을 어떻게 확장해야 할지 설명하라.
2.5 재전송 우선 처리
Verilog 코드를 수정하여 재전송 패킷에 우선권을 부여하라.
예를 들어, 동일한 switch에서 두 개의 head phit이 동일한 출력을 요청할 경우,
항상 재전송된 패킷이 우선권을 갖도록 한다.
이를 위해 phit header에 priority field를 추가하고, 패킷이 재주입될 때 이 필드가 적절히 설정된다고 가정한다.
2.6 여러 번 drop되는 것 줄이기
2.5에서 제안한 것처럼 동일한 패킷이 여러 번 drop되는 것을 줄이면,
평균 latency는 감소하는가? 그 이유를 설명하라.
2.7 butterfly 확장에 따른 drop률 변화
예제 butterfly network에 stage를 추가하여 노드 수를 늘리면, drop되는 패킷의 비율은 어떻게 될까?
반대로, switch의 degree를 증가시키면 어떻게 될까?
drop 확률만을 고려할 때, 노드를 늘릴 경우 stage를 늘리는 것과 switch degree를 키우는 것 중 무엇이 더 효율적인가?
2.8 현실적인 drop delay
실제 네트워크에서는 drop된 패킷을 다시 전송하기까지 상당한 지연이 존재한다.
예를 들어, acknowledgment가 source에 도달하고, timeout까지 기다려야 한다.
이러한 delay를 반영하여 Equation 2.3을 수정하라.
2.9 시뮬레이션
우리 예제 네트워크를 시뮬레이션하는 간단한 프로그램을 작성하라.
이를 통해 injection rate에 따른 latency를 실험적으로 측정하라.
결과를 Equation 2.3과 Figure 2.11의 분석 결과, 그리고 queueing 모델과 비교하라:
T=T02+p0p3(T02+p02(1−p0))T = \frac{T_0}{2} + \frac{p_0}{p_3} \left( \frac{T_0}{2} + \frac{p_0}{2(1 - p_0)} \right)
여기서 T0T_0는 zero-load latency, 즉 drop되지 않은 패킷의 latency이다.
2.10 timeout 메커니즘 추가
Exercise 2.9의 시뮬레이터에 timeout 기능을 추가하라.
Exercise 2.8에서 제시된 모델과 비교하고, 주요 차이점을 설명하라.
'System-on-Chip Design > NoC' 카테고리의 다른 글
| Butterfly Networks (1) | 2025.06.02 |
|---|---|
| Topology Basics (4) | 2025.06.01 |
| Introduction to Interconnection Networks (6) | 2025.06.01 |
| Run-time Deadlock Detection (5) | 2025.06.01 |
| A Heuristic Framework for Designing and Exploring Deterministic Routing Algorithm for NoCs (2) | 2025.06.01 |