네트워크 topology는 interconnection network에서 channel과 node의 정적인 배치를 의미한다. 이는 packet이 이동하는 경로에 해당한다. 네트워크 설계의 첫 단계는 topology를 선택하는 것으로, routing 전략과 flow-control 방식이 topology에 크게 의존하기 때문이다. 경로를 선택하고 그 경로를 따라 이동을 계획하기 위해선 먼저 지도(topology)가 필요하다. Chapter 2에서 예시로 보여준 것처럼, topology는 네트워크의 종류(예: butterfly network)뿐 아니라, switch의 radix, stage의 수, 각 channel의 너비와 bit-rate 같은 세부 사항도 정의한다.
좋은 topology를 선택하는 일은 네트워크 요구사항을 사용 가능한 패키징 기술에 맞추는 작업이다. 한편으로는 포트 수, 포트당 bandwidth 및 duty factor가 설계를 이끌고, 다른 한편으로는 칩과 보드당 사용 가능한 핀 수, 배선 밀도, 가능한 signaling rate, 케이블 길이 요구사항이 제약 조건이 된다.
Topology는 비용과 성능에 기반하여 선택된다. 비용은 네트워크를 구현하기 위해 필요한 칩의 수와 복잡도, 이 칩들 간 보드 또는 케이블을 통한 interconnection의 밀도 및 길이에 의해 결정된다. 성능은 bandwidth와 latency 두 요소로 구성되며, 이 둘은 topology 외의 요소들 — 예: flow control, routing 전략, traffic 패턴 — 에 의해서도 영향을 받는다. 따라서 topology만을 평가하기 위해, bisection bandwidth, channel load, path delay 등의 지표를 사용하여 topology가 성능에 미치는 영향을 측정한다.
네트워크 설계자들이 흔히 저지르는 실수 중 하나는, 네트워크의 topology를 당면 문제의 데이터 통신 패턴에 맞추려는 것이다. 표면적으로는 좋은 생각처럼 보인다. 예를 들어, divide-and-conquer 알고리즘을 수행하며 tree-structured communication pattern을 사용하는 머신이라면, tree network가 최적의 선택처럼 보일 수 있다. 하지만 대부분의 경우, 이는 적절하지 않다. 여러 이유로, 특정 목적의 topology는 문제가 발생하기 쉽다. 예를 들어 문제의 동적 부하 불균형이나 문제 크기와 머신 크기 간 불일치로 인해 부하가 잘 분산되지 않을 수 있다. 데이터를 재배치해 부하를 조정하면, 네트워크와 문제 간의 매칭이 무너지게 된다. 또한 특정 문제에 특화된 네트워크는 사용 가능한 패키징 기술과 잘 맞지 않아 긴 배선이나 높은 node degree를 요구하는 경우가 많다. 마지막으로 이런 네트워크는 유연하지 않다. 알고리즘이 바뀌어 다른 통신 패턴을 요구할 경우, 네트워크는 쉽게 변경될 수 없다. 대부분의 경우, 특정 문제에 최적화된 네트워크보다, 일반적인 용도의 좋은 네트워크를 사용하는 것이 훨씬 낫다.
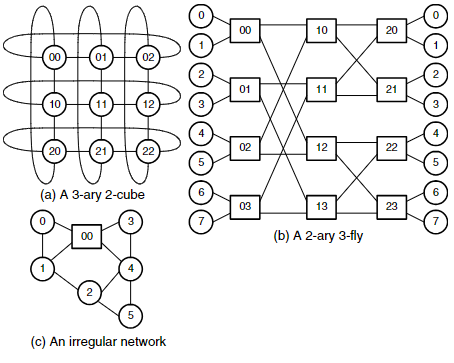
Figure 3.1은 세 가지 예시 topology를 보여준다. (a)는 2차원 torus 구조로 각 차원에 3개의 노드를 가지는 3-ary 2-cube, (b)는 radix-2 butterfly 네트워크로 3-stage 구조인 2-ary 3-fly, (c)는 irregular network다. cube 구조에서는 각 node가 terminal이자 switching node다. 반면 butterfly 구조는 terminal node와 switch node가 구분되며, 가운데에는 switch-only node가 위치한다. 불규칙한 구조도 별도로 제시되어 있다.
3.1 용어 정의
3.1.1 Channels와 Nodes
interconnection network의 topology는 node 집합 N과, 이를 연결하는 channel 집합 C로 정의된다. 메시지는 terminal node 집합 N (단, N ⊆ N)에서 생성되고 종료된다. 모든 node가 terminal인 네트워크에서는 단순히 node 집합을 N으로 표현한다.
각 channel c = (x, y) ∈ C는 source node x와 destination node y를 연결하며, x, y ∈ N이다. channel c의 source는 sc, destination은 dc로 표현한다. Figure 3.1의 각 edge는 양방향 channel 쌍을 의미한다. 이러한 topology 정의는 directed graph와 동일하며, 많은 용어가 graph theory에서 차용되었다. 편의상 node 수는 |N| 대신 N*, channel 수도 |C| 대신 C로 표현한다.
channel c = (x, y)는 다음으로 특징 지어진다:
- 너비 wc 또는 wxy: 병렬 신호의 개수
- 주파수 fc 또는 fxy: 각 신호에서 bit가 전송되는 속도
- 지연 tc 또는 txy: bit가 x에서 y로 도달하는 시간
대부분의 경우, 지연은 물리적 길이 lc와 전파 속도 v의 곱으로 표현된다: lc = vtc. bandwidth는 bc = wc * fc 로 계산된다. 모든 channel의 bandwidth가 동일한 경우, b로 통일해 표현한다.
각 switch node x는 다음과 같은 channel 집합을 가진다:
- 입력 채널 집합: CIx = {c ∈ C | dc = x}
- 출력 채널 집합: COx = {c ∈ C | sc = x}
- 전체 degree: δx = |Cx| = |CIx| + |COx|
모든 node가 같은 degree를 가진다면, δ로 간단히 표현한다.
3.1.2 Direct Network와 Indirect Network
네트워크 node는 packet을 생성하고 소모하는 terminal node, packet을 forwarding하는 switch node, 또는 둘 모두일 수 있다.
- Direct network: 예를 들어 Figure 3.1(a)의 torus에서는 모든 node가 terminal이자 switch이다.
- Indirect network: Figure 3.1(b)의 butterfly에서는 각 node가 terminal(원형) 또는 switch(사각형) 중 하나만 수행한다.
direct network는 terminal node 간에 직접 packet을 전달하고, indirect network는 전용 switch node를 통해 간접적으로 전달한다. Figure 3.1(c)처럼 direct도 indirect도 아닌 network도 존재한다. 모든 direct network는 각 node를 terminal과 switch로 분리하여 indirect 형태로 그릴 수 있다 (Figure 3.2 참조). 이 경우, direct와 indirect 간 구분은 학문적인 의미에 가깝다.

direct network의 장점 중 하나는, terminal의 자원(예: 컴퓨터)을 switch에서도 사용할 수 있다는 점이다. 초기 네트워크에서는 switch 기능이 terminal CPU에서 실행되는 소프트웨어로 구현되었으며, buffer도 terminal의 메모리를 사용했다. 하지만 소프트웨어 switching은 매우 느리고 terminal 자원을 많이 소모하므로, 현재는 거의 사용되지 않는다.
3.1.3 Cuts와 Bisections

1. Cut (컷)
Cut은 네트워크를 두 부분으로 나누는 것입니다.
- 네트워크의 모든 노드를 두 그룹으로 나눈다고 생각해보세요:
예를 들어 N1과 N2. - 그리고 두 그룹(N1과 N2)을 연결하는 channel들을 모읍니다.
- 이 연결선들의 집합을 Cut이라고 부릅니다.
즉, Cut = 한 쪽에서 다른 쪽으로 가는 channel들의 집합입니다.
예시
- C와 D 사이에 연결된 선이 있다고 하면, C는 N1에, D는 N2에 있으니 이 선은 Cut에 해당합니다.
- Cut의 개수는 이렇게 두 그룹을 나눴을 때 두 그룹을 연결하는 channel의 수입니다.
2. Bisection (바이섹션)
Bisection은 특별한 종류의 Cut입니다.
- 네트워크의 모든 노드를 거의 반으로 나누는 Cut입니다.
- 그리고 그 반으로 나눈 구역 사이의 channel 수(또는 bandwidth)가 가장 적게 되도록 나눕니다.
즉, Bisection은 네트워크를 거의 반반으로 나누면서, 그 사이를 연결하는 channel 수가 가장 적은 Cut입니다.
왜 중요할까?
- 병목 구간(bottleneck)을 찾을 수 있기 때문입니다.
- 네트워크를 반으로 잘랐을 때, 이 중간 연결(channel) 수가 적으면, 많은 트래픽이 이 작은 연결을 통과해야 하므로 성능이 떨어질 수 있습니다.
3.1.4 Paths



3.1.5 대칭성 (Symmetry)
Topology의 대칭성은 부하 분산과 라우팅에 중요한 역할을 하며, 후속 절들에서 자세히 설명된다. 네트워크가 vertex-symmetric하다는 것은, 임의의 node a를 다른 node b로 mapping하는 automorphism이 존재한다는 뜻이다. 즉, 모든 node의 관점에서 네트워크 구조가 동일하게 보인다는 의미다. 이는 routing을 단순화할 수 있는데, 모든 node가 동일한 네트워크 지도를 공유하므로 동일한 방식으로 목적지로 라우팅할 수 있다.
Edge-symmetric 네트워크는 임의의 channel a를 다른 channel b로 mapping하는 automorphism이 존재한다. Edge symmetry는 모든 channel이 동일하게 취급되므로 channel 간 부하 분산을 개선하는 데 도움이 된다.
🔷 1. Vertex-symmetric (정점 대칭)
"모든 노드가 같은 역할을 하도록 생겼다."
- 네트워크의 어느 노드에서 보더라도 구조가 똑같이 생겼다는 뜻이에요.
- 즉, 한 노드에서 연결된 방향, 수, 거리 등이 다른 노드와 똑같이 생겼다면 vertex-symmetric입니다.
- 쉽게 말해, 노드 입장에서 네트워크가 전부 똑같이 보인다는 뜻이에요.
📌 예:
- 링 (Ring) topology
- Mesh나 Torus도 경우에 따라 vertex-symmetric이 될 수 있어요.
🔷 2. Edge-symmetric (간선 대칭)
"모든 채널이 동일한 역할을 한다."
- **모든 channel (link)**이 구조적으로 같은 위치, 역할을 한다는 뜻이에요.
- 즉, 채널마다 부하가 균등하게 나뉘어질 수 있는 구조라는 의미예요.
- 네트워크 입장에서 어느 channel이든 특별 대우가 없는, "채널 평등"인 셈이에요.
📌 예:
- Torus
- 링
- 어떤 경우엔 vertex-symmetric이 아니어도 edge-symmetric일 수 있어요.
🔷 핵심 차이점 요약
| 기준 대상 | 노드 (vertex) | 채널 (edge) |
| 의미 | 모든 노드가 같은 구조/위치 | 모든 채널이 같은 역할/위치 |
| 목적 | 라우팅 단순화 (모든 노드가 동일하게 동작) | 부하 균등화 (채널에 traffic 분산 쉬움) |
| 예시 | 링, Hypercube 등 | 링, Torus 등 |
| 동등한 것? | vertex-symmetric → edge-symmetric일 수 있음 | 반대는 항상 참이 아님 |
🔷 비유로 쉽게 이해하기
- vertex-symmetric: 모든 사람이 같은 위치, 같은 복장, 같은 키를 가진 군대 → "사람 입장에서 전부 똑같다"
- edge-symmetric: 그 사람들이 가진 총이 전부 똑같고 같은 위치에서 조준함 → "총(채널) 입장에서 전부 똑같다"
3.2 Traffic Patterns
Topology 성능 지표를 도입하기 전에, interconnection network에서 메시지의 공간 분포를 이해하는 것이 유용하다. 이러한 메시지 분포는 traffic matrix λ로 나타내며, λs,d는 node s에서 node d로 전송되는 traffic의 비율을 나타낸다.

Table 3.1은 interconnection network 평가에 사용되는 일반적인 정적 traffic pattern을 나열한다. 이들 중 일부는 실제 애플리케이션에서 나타나는 통신 패턴에 기반하고 있다. 예를 들어, matrix transpose 또는 corner-turn 연산은 transpose pattern을 유도하고, FFT나 sorting 응용은 shuffle pattern, 유체역학 시뮬레이션은 neighbor pattern을 나타낸다.
- Random traffic: source가 모든 destination에 동일 확률로 전송. 가장 일반적으로 사용됨. traffic을 균등하게 분산시켜 부하를 고르게 하므로, load balance가 좋지 않은 topology나 routing 알고리즘도 이 패턴 하에서는 성능이 좋아 보일 수 있다.
- Permutation traffic: 각 source가 하나의 destination에만 전송하며, d = π(s)로 표현된다. traffic matrix λ는 permutation matrix가 되며, 각 행과 열에 단 하나의 값만 존재한다. 특정 source-destination 쌍에 load가 집중되므로, topology와 routing 알고리즘의 부하 분산 능력을 테스트하는 데 적합하다.
Bit permutation은 source 주소의 bit들을 permutation 및 보완하여 destination 주소를 생성하는 방식이다. 예를 들어 source 주소가 {s3, s2, s1, s0}라면:
- bit-reverse: {s0, s1, s2, s3}
- bit-complement: {¬s3, ¬s2, ¬s1, ¬s0}
- shuffle: {s2, s1, s0, s3}
Digit permutation은 radix-k 표현의 digit 단위로 주소를 변형하는 permutation이다. 이 방식은 terminal 주소가 k진수의 n-digit 표현인 경우 (예: k-ary n-cube, k-ary n-fly)에서 사용된다. 예시:
- Tornado pattern: torus topology를 가장 불리하게 만드는 pattern
- Neighbor pattern: locality를 얼마나 잘 활용하는지 측정
3.3 성능 (Performance)
Topology는 비용과 성능을 기준으로 선택된다. 이 절에서는 성능을 결정짓는 세 가지 주요 지표 — throughput, latency, path diversity — 를 설명한다. 3.4절에서는 이 성능 지표들을 네트워크 구현 비용과 연결하여 다시 다룬다.
3.3.1 Throughput과 최대 channel 부하
네트워크가 얼마나 많은 데이터를 처리할 수 있는지, 그리고 가장 부하가 많이 걸리는 채널이 어디인지를 분석하는 내용이다.
Throughput은 네트워크가 input port당 받아들일 수 있는 데이터 속도 (bit/sec)를 말한다. throughput은 routing 및 flow control에 크게 의존하며 topology만으로 결정되지 않는다. 하지만 routing이 부하를 완벽히 분산하고, flow control이 병목 channel에서 idle cycle이 전혀 없다고 가정하면, topology의 이론적 최대 throughput을 계산할 수 있다.
이 절에서는 모든 channel bandwidth가 동일하게 b일 때의 throughput 및 부하 공식만을 다룬다 (Ex.3.5에서는 이 제한을 해제한다).
네트워크의 어떤 channel이 포화(saturated) 상태에 도달할 때가 최대 throughput이다. 포화된 channel이 없다면, 더 많은 traffic을 수용할 수 있으므로 최대 throughput이 아님. 따라서 throughput을 계산하려면 channel load를 고려해야 한다.
channel c의 load γc는, 해당 channel이 감당해야 하는 bandwidth가 input port bandwidth에 비해 얼마나 되는지를 나타내며, 다음과 같이 정의된다. 이는 모든 input이 1 unit의 traffic을 주입할 때 channel c를 통해 지나야 하는 traffic 양으로 해석할 수 있다. 단위가 없고, 일반적으로는 uniform traffic 하에서 계산한다.







✅ 핵심 목적
“네트워크가 얼마나 빠르게 데이터를 흘릴 수 있을까?”
→ 이걸 **throughput (처리량)**이라고 하고,
→ **그걸 방해하는 가장 붐비는 통로(channel)**를 bottleneck이라 해요.
🔷 1. Throughput이란?
- Throughput은 각 input port가 초당 얼마나 많은 데이터를 네트워크로 보낼 수 있는지를 의미해요.
- 예를 들어, 모든 노드가 1 Gbit/s로 데이터를 보낸다면, 네트워크는 그 속도를 견뎌야 해요.
🔷 2. 왜 "최대 channel 부하"가 중요할까?
- 네트워크는 여러 channel (통로)로 이루어져 있어요.
- 그런데 일부 channel은 다른 것보다 더 많은 traffic을 받게 돼요.
- 이때 가장 바쁜 channel의 부하를 γmax라고 해요.
📌 이 γmax가 너무 크면 → 그 channel이 병목(bottleneck)이 돼요.
→ 그럼 전체 네트워크 throughput이 그만큼 줄어들어요.
🔷 3. 이상적인 Throughput 계산 공식
책에서 소개하는 공식:
- b: 각 channel의 bandwidth (예: 1 Gbit/s)
- γmax: 가장 많이 사용되는 channel의 부하 비율 (무차원값, 단위 없음)
🧠 이 공식이 말하는 것:
"최대 부하 channel이 완전히 포화될 때까지 input에서 데이터를 넣을 수 있다."
🔷 4. 예를 들어 볼게요
- 8-node ring이 있고,
- 각 channel은 1 Gbit/s,
- 모든 노드가 동일하게 데이터를 주고받을 때,
- 가장 많이 사용되는 channel이 1 Gbit/s까지 도달하는 순간이 throughput의 한계예요.
🔷 5. γmax는 어떻게 구하나?
책에서는 몇 가지 방식으로 γmax를 추정하거나 계산하는 방법도 알려줘요:
- bisection-based 하한:γB=N2BCγ_B = \frac{N}{2BC}(N = 노드 수, BC = channel bisection 수)
- 전체 채널에 균등 부하 분산하는 상한 공식 (Equation 3.6):γc=1N∑x,y∑P∈Rxy1∣Rxy∣(c가 포함된 경로에 대해서만)γ_{c} = \frac{1}{N} \sum_{x,y} \sum_{P ∈ R_{xy}} \frac{1}{|R_{xy}|} \quad \text{(c가 포함된 경로에 대해서만)}
✅ 정리하자면
| Throughput | input에서 보낼 수 있는 데이터의 초당 양 |
| γc | 특정 channel c의 부하 (얼마나 많은 traffic이 지나가는지) |
| γmax | 모든 channel 중 가장 부하가 높은 것 |
| λideal | γmax가 포화될 때의 최대 input 처리율 |
💡 요약 한 줄
3.3.1에서는 "네트워크에서 가장 바쁜 통로가 얼마나 빠르게 꽉 차느냐"를 기준으로 전체 데이터 처리 능력(throughput)을 계산하는 방법을 설명하고 있어요.
3.3.2 지연 (Latency)


이 세 항목은 topology와 물리적 패키징(mapping)에 의해 결정된다:
- Hmin: topology만의 특성
- Dmin: topology 및 패키징 둘 다의 영향을 받음
- b: topology의 node degree와 패키징 제한에 따라 결정
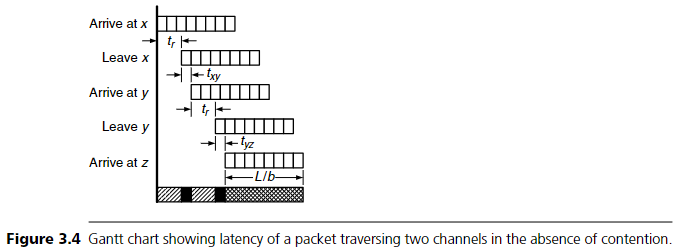
Figure 3.4는 node x에서 z까지 2-hop 경로를 따라 packet이 전달되는 과정을 Gantt 차트로 보여준다:
- node x에 도착
- tr 만큼 지연 후 channel x→y로 전송
- txy 시간 동안 전파
- y에서 다시 tr 지연 후 y→z로 전송
- tyz 전파 시간
- 마지막으로 tail이 도착할 때까지 L/b 시간 직렬화 지연
이 과정을 통해 Equation 3.11의 세 지연 요소가 시각적으로 설명된다.
Figure 3.4의 Gantt 차트에서 latency의 구성 요소가 요약된다. 단일 해치 부분은 routing 지연, 연한 회색 부분은 link latency, 이중 해치 부분은 serialization latency에 해당한다.
예를 들어, 64-node 네트워크에서 평균 hop 수 Havg가 4이고, channel 너비가 16비트인 경우를 생각해 보자. 각 channel c는 1GHz에서 동작하며, 해당 channel을 통과하는 데 tc = 5ns가 걸린다. 단일 router의 지연이 tr = 8ns (2ns clock × 4)일 때, 전체 routing 지연은 8 × 4 = 32ns (16 clocks)이다. wire 지연은 5ns씩 4개로 총 Tw = 20ns (10 clocks)다. packet 길이가 L = 64바이트이고, channel bandwidth가 2GB/s이면 serialization 지연은 64 / 2 = 32ns (16 clocks)이다. 따라서 전체 T₀는 32 + 20 + 32 = 84ns가 된다.
3.3.3 경로 다양성 (Path Diversity)
대부분의 노드 쌍에 대해 minimal path가 여러 개인 네트워크, 즉 |Rxy| > 1인 경우는 |Rxy| = 1인 단일 경로 네트워크보다 더 견고하다. 이러한 path diversity는 채널 간 부하를 분산하고, 고장난 채널이나 노드에도 견딜 수 있도록 하여 네트워크의 신뢰성을 높여준다.
지금까지는 각 노드가 다른 모든 노드로 균등하게 메시지를 보내는 random traffic에 대해 주로 다루었다. 많은 네트워크에서 random traffic은 이상적인 부하이며, 이는 채널 부하를 균등하게 분산시켜주기 때문이다. 그러나 permutation traffic처럼 각 노드가 정확히 하나의 다른 노드로만 메시지를 보낼 때는 상황이 더 까다롭다. 이 경우 path diversity가 부족하면 일부 permutation은 특정 채널에 traffic을 집중시켜 throughput을 심각하게 떨어뜨릴 수 있다.
예를 들어, bit-rotation traffic을 두 가지 topology에서 전송한다고 가정하자:
- 2-ary 4-fly (unit bandwidth)
- 4-ary 2-cube (half-unit bandwidth)
두 네트워크 모두 random traffic에서는 γmax = 1이다. bit-rotation (BR) traffic에서 주소가 {b3, b2, b1, b0}인 노드는 {b2, b1, b0, b3}로 packet을 보낸다. 이는 다음과 같은 shuffle permutation과 같다:
{0, 2, 4, 6, 8, 10, 12, 14, 1, 3, 5, 7, 9, 11, 13, 15}
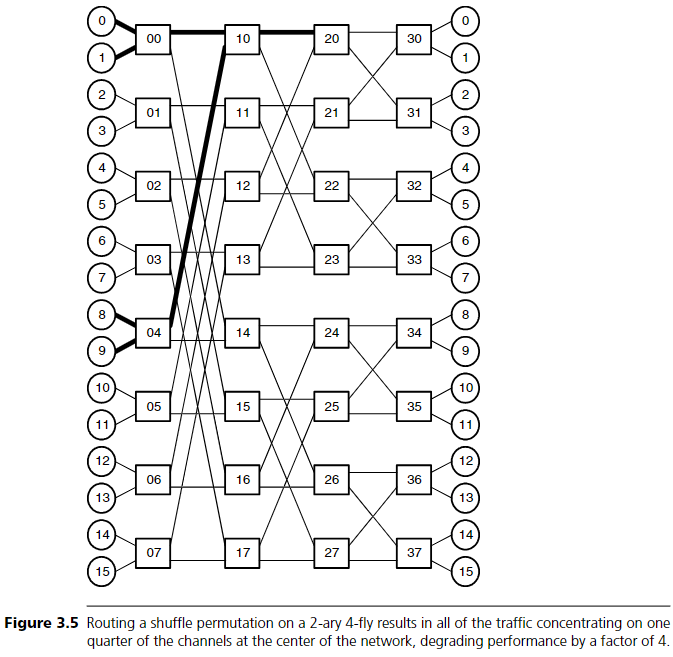
즉, node 0은 자기 자신에게, node 1은 node 2로, 이런 식이다. Figure 3.5에서처럼, 이 permutation이 2-ary 4-fly에 적용되면 모든 traffic이 네트워크 중앙의 몇 개 채널에 집중된다. 예를 들어:
- node 0, 1, 8, 9 → channel (10, 20)
- node 2, 3, 10, 11 → channel (11, 23)
- node 4, 5, 12, 13 → channel (16, 24)
- node 6, 7, 14, 15 → channel (17, 27)
이 경우 γmax,BR = 4가 되고, throughput은 전체 용량의 25%로 떨어진다.
반면 Figure 3.6에서와 같이, 같은 permutation을 4-ary 2-cube에 적용하면 다음과 같은 결과가 나온다:
- 2개 경로는 채널을 사용하지 않음
- 4개 경로는 채널 1개 사용
- 4개 경로는 채널 2개 사용 (예: H(5,10) = 2, |R5,10| = 2)
- 4개 경로는 채널 3개 사용 (경로 수: 3개)
- 4개 경로는 채널 4개 사용 (경로 수: 24개)
minimal routing만을 사용할 경우, 1-hop 경로가 병목이 된다. 대체 minimal route가 없기 때문이다. 이 경우 γmax,BR = 1이며, uniform traffic에서 γmax = 0.5이므로 throughput은 전체 용량의 50%다.
그러나, 1-hop 경로의 절반을 non-minimal routing으로 우회시키면 부하가 균등해진다. 예를 들어, node 1 → 2 traffic의 절반은 (1,2)로 가고, 나머지 절반은 (1,0)-(0,3)-(3,2) 경로를 사용한다. 이 경우 throughput은 용량의 89%까지 증가하며, 11%의 감소는 non-minimal 경로에서의 hop 수 증가 때문이라 볼 수 있다.
이 예시는 non-minimal routing이 부하 분산에 필수적일 수 있음을 보여준다. 비록 전체적으로 더 많은 경로를 사용하더라도, 네트워크 전체의 성능은 오히려 향상될 수 있다. 그러나 non-minimal routing은 deadlock 방지 등 구현 복잡성을 높이는 단점도 있다 (Chapter 14에서 다룸).
path diversity의 또 다른 중요한 장점은 고장 허용 능력이다. 예를 들어 Figure 3.5의 butterfly network에서 switch 07→17 link가 고장 나면, source 14에서 destination 15로 가는 경로는 존재하지 않는다. 시스템이 커질수록 고장 가능성도 커지므로, 대규모 네트워크는 하나 이상의 노드 또는 link 고장에도 견딜 수 있어야 한다.
한 네트워크의 고장 허용 능력은 edge-disjoint 또는 node-disjoint 경로 수로 측정된다:
- edge-disjoint paths: 공통 link 없이 구성된 경로 집합. 하나의 link 고장이 해당 경로 중 최대 하나에만 영향을 준다.
- 모든 노드 쌍 간 최소 edge-disjoint path 수가 j개라면, j개 미만의 link 고장에는 연결이 보장된다.
- node-disjoint paths: 출발지와 목적지를 제외하고, 공통 노드 없이 구성된 경로 집합. 하나의 노드 고장은 하나의 경로에만 영향을 미친다.
- node-disjoint는 edge-disjoint도 만족하므로, j개 node-disjoint 경로가 있다면 j개 이하의 link 및 node 고장을 견딜 수 있다.
운이 나쁘면, 특정 노드의 이웃 노드, 모든 입력 link, 출력 link가 동시에 고장날 수 있다. 이 경우 해당 노드는 다른 노드로부터 도달도, 전송도 불가능해지며, 이와 같은 고장 수는 다음과 같다:
minx[min{∣CIx∣, ∣COx∣}]\min_x \left[ \min \left\{ |CI_x|,\ |CO_x| \right\} \right]
3.4 패키징 비용 (Packaging Cost)
네트워크를 구축할 때, topology의 node들은 물리적 시스템의 packaging 모듈, 칩, 보드, 섀시 등에 매핑된다. topology와 packaging 기술, node 배치는 channel bandwidth 제약을 결정하며, 이 제약 없이는 topology를 평가하거나 비교할 수 없다.
이 절에서는 channel width w가 노드당 핀 수와 전체 global wiring 양에 의해 제한되는 2단계 packaging 계층 모델을 통해 간단한 비용 모델을 정립한다. 또한 bandwidth의 또 다른 구성 요소인 주파수 f가 packaging 선택에 어떻게 영향을 받는지도 다룬다.
첫 번째 계층: router 간 local wiring
- local wiring은 global wiring보다 저렴하고 풍부하므로, topology는 공간적 locality를 활용해 노드 간 거리를 가깝게 유지해야 한다.
- 예: 4×4 배열로 16개의 노드를 하나의 PC 보드에 배치하면, 전체 pin 중 75%가 로컬 연결로 사용 가능하며, 단지 32개 채널만 module 경계를 넘게 된다 (Figure 3.7 참조).
이러한 로컬 배치를 결정한 후, channel width의 주된 제약은 노드당 사용 가능한 핀 수가 된다. 노드당 최대 핀 수를 Wn이라 하면, degree가 δ인 node에서 channel width w는 다음을 만족해야 한다:
w≤Wnδ(3.12)w ≤ \frac{W_n}{δ} \quad (3.12)
두 번째 계층: global wiring (예: 백플레인)
- 여러 보드를 연결하는 wiring 구조로 구성되며, global signal은 보드 → 커넥터 → 백플레인 → 커넥터 → 다른 보드 순으로 이동한다.
- 이때 사용 가능한 전체 global wires 수 Ws가 각 channel width의 제약이 된다.
- 예: 백플레인을 사용할 경우, 배선 밀도가 제한 요소다.
- through-hole vias 공간 고려 시, 일반 PC 보드는 신호층당 1 wire/mm 또는 differential signal 기준 0.5 signal/mm 수준
- 중간 비용 보드는 x, y 방향 각각 4층 → 총 8층 → 방향당 2 signal/mm 가능
Figure 3.7은 4×4 배열의 노드를 하나의 PC 보드에 패키징한 예를 보여준다. 이 구성에서는 전체 노드 핀 중 약 4분의 3이 local wiring으로 연결되어 있다.
bisection은 네트워크를 거의 절반으로 나누면서, 가능한 적은 수의 wire를 절단하는 방식이다. 따라서 bisection으로 나뉜 두 노드 집합은 패키징 시 local group으로 나누기에 좋은 기준이 된다. 이 모델은 일부 네트워크에서는 두 개 이상의 local group으로 나눠야 하는 제약이 있긴 하지만, 대부분의 경우 좋은 근사치를 제공한다.
minimum bisection을 활용하면, 사용 가능한 global wiring에 따라 channel width는 다음 제약을 받는다:
w≤WsBC(3.13)w ≤ \frac{W_s}{BC} \quad (3.13)
여기서는 2단계 packaging 계층을 중심으로 설명했지만, 더 큰 시스템에서 필요한 추가 packaging 계층에도 Equation 3.13을 적용할 수 있다.
Equation 3.12와 3.13을 결합하면 channel width에 대한 전체 제약은 다음과 같다:
w≤min(Wnδ, WsBC)(3.14)w ≤ \min \left( \frac{W_n}{δ},\ \frac{W_s}{BC} \right) \quad (3.14)
- 첫 번째 항 (Wn/δ)은 degree가 낮은 네트워크 (예: ring)에서 지배적이다. → 이 경우 핀 수 제한형
- 두 번째 항 (Ws/BC)은 degree가 높은 네트워크 (예: binary n-cube)에서 지배적이다. → 이 경우 bisection 제한형
channel width가 아닌 bandwidth 관점에서 제약을 다시 정리할 수도 있다:
- 노드당 최대 bandwidth: Bn=fWnB_n = f W_n
- 시스템 bisection 최대 bandwidth: Bs=fWsB_s = f W_s
이를 이용하면 channel당 최대 bandwidth b는 다음과 같이 표현된다:
b≤min(Bnδ, BsBC)b ≤ \min \left( \frac{B_n}{δ},\ \frac{B_s}{BC} \right)
패키징 계층에서 고려해야 할 또 다른 중요한 요소는 배선 길이다.
채널 길이는 짧을수록 좋다. 일정 길이 이상이 되면, 신호 주파수가 길이의 제곱에 반비례하여 급격히 감소하기 때문이다:
f=min(f0, f0(lwlc)−2)f = \min \left( f_0,\ f_0 \left( \frac{l_w}{l_c} \right)^{-2} \right)
여기서 lc는 주어진 신호율 f₀에서 허용 가능한 감쇠를 기준으로 한 임계 길이(critical length)다.
Table 3.2는 신호율 2GHz에서 다양한 배선 종류에 대한 임계 길이 lc를 나타낸다 (1dB 감쇠 한도 기준):
| 5 mil stripguide | 0.10 m |
| 30 AWG pair | 0.56 m |
| 24 AWG pair | 1.11 m |
| RG59U coax | 10.00 m |
대부분의 네트워크는 stripguide, fine wire cable 등을 사용한다. 이들은 약 1m 내외의 짧은 거리까지만 지원 가능하며, 이를 넘으면 데이터 속도가 급격히 떨어진다.
Repeater를 삽입하면 긴 채널에서도 고속 동작이 가능하지만, repeater 하나의 비용은 switch 하나와 비슷하다. 따라서 repeater 대신 switch를 삽입하여 channel을 분할하는 것이 더 효율적이다.
즉, 긴 channel이 필요한 topology는 고속 전기식 네트워크에 적합하지 않다.
대안으로 광 신호(optical signaling)를 사용할 수 있다. 광섬유는 전기 배선보다 감쇠와 신호 왜곡이 적어 훨씬 긴 거리(수십~수백 km)를 커버할 수 있다. 단점은 비용이다. 2003년 기준 동일 bandwidth에서 광 채널은 전기 채널보다 10배 이상 비쌌다.
Topology 비교 예시: Figure 3.9는 두 가지 6-node topology의 예를 보여준다.
- (a) 6-node ring: δ = 4, BC = 4
- (b) Cayley graph: δ = 6, BC = 10
패키징 조건:
- Wn = 140핀 / 노드
- Ws = 200 신호 / backplane
패키징 제약을 만족하기 위한 channel width w를 각각 계산:
- Ring:
w≤min(1404, 2004)=min(35,50)=35(3.15)w ≤ \min \left( \frac{140}{4},\ \frac{200}{4} \right) = \min (35, 50) = 35 \quad (3.15)
- Cayley graph:
w≤min(1406, 20010)=min(23.3,20)=20(3.16)w ≤ \min \left( \frac{140}{6},\ \frac{200}{10} \right) = \min (23.3, 20) = 20 \quad (3.16)
신호 주파수 f = 1GHz 기준으로, channel bandwidth는 다음과 같다:
- Ring: 35 Gbit/s
- Cayley graph: 20 Gbit/s
메시지 길이 L = 1024비트, router delay tr = 20ns일 때, 각 topology의 이상적 throughput과 무부하 지연은 Table 3.3에 비교되어 있다.
| b | 35 Gbit/s | 20 Gbit/s |
| Havg | 3/2 | 7/6 |
| γmax | 3/4 | 7/18 |
| λideal | ~46.7 Gbit/s | ~51.4 Gbit/s |
| Th (head 지연) | 30 ns | ~23.3 ns |
| Ts (직렬 지연) | ~29.3 ns | ~51.2 ns |
| T0 (총 지연) | ~69.3 ns | ~74.5 ns |
→ Cayley graph는 higher throughput, Ring은 낮은 지연 시간을 가진다.
왜 이런 결과가 나올까?
- Ring은 pin 수에 의해 channel width가 제한됨 (35)
- Cayley는 bisection 제약으로 제한됨 (20)
따라서:
- Cayley는 bisection 활용이 더 효율적이라 throughput이 높음
- 하지만 channel이 좁아져서 serialization 지연이 커지고, 평균 hop 수 감소 효과를 상쇄함
결론: 단순히 topology만 보면 Cayley가 더 나아 보이지만, 실제 latency는 packaging 제약에 의해 Ring이 더 낮다.
✅ 요약 판단
| 핀 수 제약 (Wₙ) | ✔️ 적용 가능 | SoC 설계 시, 각 IP나 tile에 연결 가능한 signal 수, 루터 포트 수는 실제 제약이 있음 |
| global wiring 제약 (Wₛ, backplane) | ❌ 무시 가능 | NoC에서는 chip 내부 배선만 존재 → backplane 개념은 없음 |
| channel 길이 vs 주파수 (f ∝ 1/l²) | ⚠️ 부분 적용 | SoC 배선에서도 거리별 RC delay와 signal integrity 문제가 있으므로 신호 품질 고려는 필요 |
| 2단계 패키징 (보드, 섀시, 랙) | ❌ 완전 무시 | NoC는 단일 실리콘 다이 내부에서 routing함. 해당 내용은 적용되지 않음 |
| bisection bandwidth | ✔️ 중요 | NoC 성능 평가에서 bisection bandwidth는 global throughput 지표로 여전히 매우 유효함 |
🔍 NoC에 의미 있는 부분만 요약
1. 채널 수 vs node degree (Wₙ/δ)
- NoC에서도 한 라우터에 몇 개의 입출력 포트를 가질 수 있느냐는 매우 중요한 설계 제약입니다.
- 예: 5-port (N/S/E/W/Local) mesh 라우터 구조 등
- NoC에서는 이것이 cell 면적, 전력, 배선 자원과 직결되므로 Wₙ/δ 제약은 유효합니다.
2. bisection bandwidth
- NoC에서도 mesh, torus, ring 등 다양한 topology의 bisection bandwidth는 network의 bottleneck을 결정합니다.
- 따라서 Chapter 3.4 후반부에서 설명한 "bisection bandwidth가 throughput에 미치는 영향"은 그대로 적용할 수 있습니다.
3. 배선 길이에 따른 주파수 저하 (f ∝ 1/l²)
- chip 내부 배선에서도 long wire delay, insertion buffer, repeater, clock skew, crosstalk 등과 관련된 문제가 있습니다.
- 따라서 완전히 무시할 수는 없지만, NoC 설계자는 H-tree, buffered link 등으로 해결할 수 있습니다.
- → 실제 설계 시 wire pipelining, serialization, 또는 CDN 기술 등을 통해 보완합니다.
✅ 결론
Chapter 3.4 "Packaging Cost"의 전부를 NoC에 적용할 필요는 없지만,
핀 수 제약(Wₙ/δ), bisection bandwidth, 배선 길이와 delay의 관계는
NoC 설계 시에도 반드시 고려할 요소입니다.
3.5 사례 연구: SGI Origin 2000
Figure 3.10은 SGI Origin 서버를 보여준다. 왼쪽은 16-프로세서가 들어간 캐비닛이며, 오른쪽은 8-프로세서 데스크사이드 모델이다.
이 시스템의 네트워크를 살펴보면, interconnection network를 packaging 계층에 매핑하는 데 필요한 여러 문제를 이해할 수 있다. 또한, 소수의 노드에서 수백 개의 노드까지 확장 가능한 시스템을 고정된 구성 요소로 구축할 때 발생하는 이슈들도 알 수 있다.
Origin 2000 네트워크는 SGI의 SPIDER routing chip에 기반한다. 이 칩은 양방향 네트워크 채널 6개를 제공하며, 각 채널은 20비트 폭이고 400 MHz에서 동작한다. 따라서 channel bandwidth는 6.4 Gbit/s가 되고, 하나의 node는 총 6개 채널을 가지므로 노드당 38.4 Gbit/s의 bandwidth를 가진다. 이 모든 채널은 backplane을 통해 구동될 수 있으며, 이 중 3개 채널은 최대 5미터 길이의 케이블을 직접 구동할 수 있다.
Figure 3.11은 Origin 2000 네트워크 topology가 노드 수에 따라 어떻게 변화하는지를 보여준다. 모든 구성에서 각 terminal router는 2개의 processing node(총 4개 프로세서)에 연결된다. 이 terminal 연결은 router의 6개 채널 중 2개를 사용하며, 나머지 4개는 다른 router들과 연결된다.
- 최대 16개 router (32개 노드, 64개 프로세서)로 구성된 시스템은 binary n-cube로 구성되며, 각 router는 최대 4차원 이웃 router에 연결된다 (Figure 3.11(a) 참조).
- 만약 4차원 전체를 사용하지 않는 경우(예: 8-router 시스템), 남은 채널은 머신 전체에 걸쳐 연결되어 네트워크 지름을 줄인다.
주석: 이와 같은 terminal에 여러 processor를 연결하는 방식은 concentration이라 하며, 이는 Section 7.1.1에서 다룬다.
Figure 3.12는 router 수가 16개를 초과하는 시스템에 대해 hierarchical topology를 사용하는 방식을 보여준다.
- 큰 시스템은 8-router (16-node, 32-processor)로 구성된 local subnetwork를 사용하며, 이 subnetwork는 binary 3-cube로 구성된다. 각 node는 채널 하나를 남겨둔다.
- 8개의 router-only global subnetwork가 local subnetwork들 간을 연결한다.
- router가 2ⁿ개인 시스템에서, 각 global network는 m = n − 3 차원의 binary cube로 구성된다.
예시:
- 최대 규모인 256-router (512-node, 1024-processor) 시스템은 32-node binary 5-cube 8개를 global subnetwork로 사용한다.
- local subnetwork j에 있는 router i의 남은 채널은 global subnetwork i의 router j에 연결된다.
특수한 경우:
- 32-node 시스템(n = 5)에서는 각 4포트 global subnetwork가 하나의 router chip으로 구현된다.
- 이 구조는 결과적으로 Clos network 구조이며 (Section 6.3 참조), 각 switch는 binary n-cube로 구성된다.
Figure 3.13은 Origin 2000 시스템의 packaging 구조를 보여준다.
- 각 노드(2프로세서)는 16인치 × 11인치 회로 보드 하나에 패키징된다.
- 각 router chip도 별도의 보드에 패키징된다.
- 노드 보드 4개(= 8프로세서)와 router 보드 2개가 하나의 chassis에 들어가며, 이들은 midplane으로 연결된다.
- chassis 내의 남은 공간은 I/O 서브시스템에 사용된다.
- chassis 2개(= router 4개)가 1개의 캐비닛에 들어간다.
- 시스템은 최대 64개 캐비닛(256 routers)까지 구성될 수 있으며, 대형 시스템의 경우 router 전용 캐비닛이 global subnetwork를 위해 추가된다.
router board의 6개 채널 중:
- 2개: midplane의 노드 보드 2개에 연결
- 1개: midplane 상의 다른 router에 연결
- 3개: back-panel connector를 통해 다른 chassis로 연결됨
- 1개: 동일 캐비닛 내 다른 chassis에 연결
- 1개: local subnet 내 두 번째 캐비닛에 연결
- 1개: global subnetwork 또는 4-cabinet 시스템의 두 번째 캐비닛 쌍에 연결
Table 3.4는 이 hierarchical topology가 shared-memory multiprocessor 시스템의 요구사항을 어떻게 충족하는지를 보여준다. 이 시스템은 모든 router가 6포트라는 제약 하에서 구성된다.
- Equation 3.11에 따라, zero-load latency는 hop 수와 거리(지름)에 비례해 증가한다.
- Equation 3.10의 serialization latency는 채널 너비(20비트)로 고정된다.
Origin 2000은 시스템 크기에 따라 지름(diameter)이 로그 증가하도록 구성된 topology를 사용하여 latency를 낮춘다.
degree-4 binary n-cube 이상의 구조가 필요한 경우, hierarchical network 구조로 확장함으로써 로그 증가 특성을 유지할 수 있다.
또한 이 topology는 shared-memory multiprocessor에 필요한 bandwidth 조건도 만족한다.
- 모든 구성에서 bisection은 총 N개의 채널을 절단한다 (방향당 N/2개, 총 N개).
- 작은 시스템: binary n-cube에서 router 수 2ⁿ개 → bisection을 통과하는 채널 수 = 2ⁿ개 (방향당 2ⁿ⁻¹)
- 큰 시스템: 각 노드는 global subnetwork에 채널 1개를 가지고 있으며, 각 global subnetwork는 그 입력 대역폭만큼의 bisection bandwidth를 가진다.
Table 3.4 Origin 2000 네트워크의 노드 수에 따른 구성 및 성능:
| 4 | binary 1-cube | 1 | 3 | 2 |
| 8 | binary 2-cube | 2 | 4 | 4 |
| 16 | binary 3-cube | 4 | 5 | 8 |
| 32 | binary 4-cube | 8 | 6 | 16 |
| 64 | 4개의 3-cube × 8개의 4포트 스위치 | 16 | 7 | 32 |
| 128 | 8개의 3-cube × 8개의 3-cube | 32 | 9 | 64 |
| 256 | 16개의 3-cube × 8개의 4-cube | 64 | 10 | 128 |
| 512 | 32개의 3-cube × 8개의 5-cube | 128 | 11 | 256 |
3.6 참고 문헌 노트
이 책의 다음 장에서는 가장 널리 사용되는 두 가지 interconnection network에 중점을 두지만, 주목할 만한 다른 topology들도 존재한다.
- Cube-connected cycles는 hypercube와 동일한 hop 수(diameter)를 유지하면서도 node degree는 고정시킨다【153】.
- Fat tree는 모든 topology를 다항 로그 시간(polylogarithmic time) 안에 모방할 수 있는 보편적(universal) topology로 입증되었다【113】. 예: CM-5 시스템의 네트워크는 4-ary fat tree를 사용【114】.
- Cayley graphs는 cube-connected cycles을 포함하는 topology 집합으로, 간단한 routing과 동일한 크기의 hypercube보다 낮은 degree를 제공한다【7】.
3.7 연습문제
3.1 Tornado traffic in the ring
8-node ring에서 각 노드는 ring을 따라 3 hop 떨어진 노드로 트래픽을 보낸다 (즉, node i는 (i+3 mod 8)로 전송). 각 channel의 bandwidth는 1 Gbit/s이고, 각 input은 512 Mbit/s를 전송한다.
- minimal routing을 사용할 경우 channel load, 이상적 throughput, speedup은?
- non-minimal routing을 허용하고, 거리 기반 확률 분포 (3-hop 경로 5/8, 5-hop 경로 3/8)를 적용했을 때 재계산하라.
3.2 최악의 channel load 하한
최악의 트래픽 조건에서, bisection channel이 가장 높은 부하를 가진다고 가정할 때, 최대 channel load의 하한을 도출하라 (모든 channel의 bandwidth는 b로 동일).
3.3 channel load 상한의 한계
Equation 3.6이 타이트하지 않은 topology를 찾아라. 해당 topology가 부하를 최적으로 분산하기 위해 non-minimal routing이 필요한가? 이유를 설명하라.
3.4 대칭 topology의 channel load 상한의 타당성
edge-symmetric topology에 대해, Equation 3.5 및 3.6의 최대 channel load 상한이 실제 최적 부하와 동일함을 증명하라.
3.5 비대칭 bandwidth에서의 throughput
channel bandwidth가 동일하지 않을 때의 이상적 throughput 식을 도출하라. 필요하다면 γc와 γmax의 정의를 수정하라.
3.6 serialization latency가 topology 선택에 미치는 영향
64개의 processor node를 최소 latency로 연결해야 한다. 각 router는 processor와 동일한 chip에 위치하며 (direct network), processor chip당 네트워크용 pin은 128개다. 각 pin bandwidth는 2 Gbit/s, 평균 packet 길이는 512bit, router의 hop latency는 15ns이다. (wire latency Tw는 0으로 가정)
- (a) fully connected topology의 경우, average router latency Trmin, serialization latency Ts, zero-load latency T₀는?
- (b) ring topology의 경우 (Hmin = 16), latency들을 다시 계산하라.
3.7 non-random 트래픽에서의 latency
Section 1.3.1에서 torus와 ring의 latency는 random traffic 가정 하에 분석되었다. 이 결과로 ring이 더 낮은 latency를 가지는 것으로 나타났다. torus가 더 낮은 latency를 가지는 트래픽 패턴이 존재하는가? 존재하지 않는다면 그 이유는? (torus의 node (i,j)는 ring의 node 4i + j로 매핑된다고 가정)
3.8 Origin 2000에서의 latency
각 Origin 2000 rack은 19인치 너비, 72인치 높이이다. rack 내부 케이블은 48인치, rack 간 케이블은 플로어 아래로 라우팅되며, 케이블의 전파 속도는 2×10⁸ m/s이다. 메시지는 512비트 길이(32비트 word 16개).
- node 수가 16개 및 512개인 Origin 2000에 대해 wire delay Tw를 포함한 평균 zero-load latency를 계산하라 (uniform traffic 가정).
3.9 partially random wiring의 diameter 개선
random topology는 low diameter 등 좋은 특성을 가지나, 포장 및 routing 정규성 측면에서 비실용적일 수 있다.
Figure 3.14(a)의 mesh 네트워크에서, 좌우는 서로 다른 cabinet에 포장되어 있고, coaxial cable로 대응 node가 연결되어 있다.
- (a) 이 mesh network의 diameter는?
- (b) 케이블 연결을 무작위로 섞으면 diameter는 어떻게 변화하는가? (Figure 3.14(b) 참조). 모든 permutation 중 최소/최대 diameter는? 최소 diameter를 실현하는 permutation은?
3.10 fat tree 네트워크 성능
Figure 3.15는 16-node, radix-2 fat tree를 보여준다.
- (a) 모든 channel bandwidth가 terminal node의 injection/ejection rate와 같다면, 네트워크의 capacity는?
- (b) 다음과 같은 random routing을 사용할 경우: 패킷은 source에서 “위쪽”으로 올라가면서 두 개의 up 채널 중 임의 선택, 이후 “아래쪽” 경로로 destination까지 라우팅. 어떤 트래픽 패턴에서든 최대 channel load는 얼마까지 가능한가?
3.11 cube-connected cycles topology의 성능과 패키징
Figure 3.16은 3차 order cube-connected cycles이다.
- (a) channel bisection BC는?
- (b) minimal routing을 사용할 경우, 최대 hop 수 Hmax와 평균 hop 수 Hmin은?
- (c) 다음 제약 하에 이 topology를 패키징하라: Wn = 128 signals/node, Ws = 180 signals/backplane. packet 길이 L = 200bit, 주파수 f = 800 MHz, wire 길이는 무시. channel width w의 최대값은? pin 제한인가 bisection 제한인가? zero-load latency를 75ns로 맞추기 위한 router latency tr 값은?
3.12 성능의 물리적 한계
단순한 가정을 통해, 패키징된 네트워크의 diameter와 노드 간 거리의 실현 가능한 하한을 계산할 수 있다.
- (a) radix k switch를 사용할 경우, N-node 네트워크의 최소 diameter는?
- (b) 노드가 부피 V를 가질 때, 3차원에서 노드 간 최대 거리를 최소화하는 packaging 형태는? 많은 수의 노드를 가정할 때 이 거리는 얼마인가?
'System-on-Chip Design > NoC' 카테고리의 다른 글
| Torus Networks (2) | 2025.06.02 |
|---|---|
| Butterfly Networks (1) | 2025.06.02 |
| A Simple Interconnection Network (2) | 2025.06.01 |
| Introduction to Interconnection Networks (6) | 2025.06.01 |
| Run-time Deadlock Detection (5) | 2025.06.01 |