디지털 시스템은 현대 사회에 만연해 있다. 디지털 컴퓨터는 물리 시스템의 시뮬레이션, 대규모 데이터베이스 관리, 문서 작성 등 다양한 작업에 사용된다. 디지털 통신 시스템은 전화 통화, 비디오 신호, 인터넷 데이터를 전달한다. 오디오와 비디오 엔터테인먼트 역시 점점 디지털 형태로 전달되고 처리된다. 마지막으로, 자동차부터 가전제품까지 거의 모든 제품이 디지털 방식으로 제어된다.
디지털 시스템은 세 가지 기본 구성 요소로 이루어진다: logic, memory, communication.
Logic은 데이터를 변형하거나 조합한다. 예를 들어 산술 연산을 하거나 결정을 내리는 기능이다.
Memory는 데이터를 나중에 사용할 수 있도록 저장하며, 시간적으로 이동시킨다.
Communication은 데이터를 한 위치에서 다른 위치로 이동시킨다.
이 책은 디지털 시스템의 communication 구성 요소를 다룬다. 특히, 디지털 시스템의 서브시스템 간 데이터 전송에 사용되는 interconnection network를 다룬다.
오늘날 대부분의 디지털 시스템에서 성능의 병목은 logic이나 memory가 아니라 communication 또는 interconnection에서 발생한다. 고급 시스템에서는 전력의 대부분이 배선을 구동하는 데 사용되며, 클럭 주기의 대부분은 gate delay가 아니라 wire delay에 소모된다. 기술이 발전함에 따라 메모리와 프로세서는 더 작고, 빠르고, 저렴해지지만 빛의 속도는 변하지 않는다. 시스템 구성 요소 간 interconnection을 결정짓는 핀 밀도와 배선 밀도는 구성 요소 자체보다 느리게 스케일링되고 있다. 또한 구성 요소 간 통신 빈도는 최신 프로세서의 클럭 속도에 비해 현저히 뒤처지고 있다. 이러한 요인이 결합되어 interconnection은 향후 디지털 시스템의 성공을 좌우하는 핵심 요소가 되었다.
설계자들이 제한된 interconnection bandwidth를 보다 효율적으로 활용하려고 노력하면서, interconnection network는 현대 디지털 시스템의 시스템 수준 통신 문제를 해결하는 거의 범용적인 솔루션으로 자리 잡고 있다. 이들은 원래 다중 컴퓨터(multicomputer)의 까다로운 통신 요구 사항을 해결하기 위해 개발되었지만, 현재는 버스를 대체하는 시스템 수준 표준 interconnection으로 자리잡고 있다. 또한 특수 목적 시스템에서의 전용 배선 역시, routing wires보다 routing packets이 더 빠르고 경제적이라는 사실이 알려지면서 interconnection network로 대체되고 있다.
1.1 Interconnection Networks에 대한 세 가지 질문
본격적으로 들어가기 전에, interconnection network에 대한 몇 가지 기본적인 질문을 살펴본다:
Interconnection network란 무엇인가?
어디에서 사용되는가?
왜 중요한가?
Interconnection network란 무엇인가?
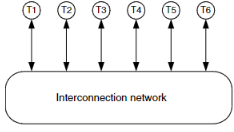
그림 1.1에서 볼 수 있듯, interconnection network는 단말들 사이의 데이터를 전송하는 programmable system이다. 그림에서는 T1부터 T6까지 여섯 개의 단말이 네트워크에 연결되어 있다. 예를 들어, T3이 T5로 데이터를 전송하려고 하면, 네트워크에 메시지를 보내고 네트워크가 그 메시지를 T5로 전달한다. 이 네트워크는 특정 시점마다 다른 연결을 수행하는 programmable한 특성을 갖는다. 예를 들어, 한 클럭 주기에는 T3에서 T5로 메시지를 전송하고, 다음 클럭 주기에는 동일한 자원을 사용해 T3에서 T1로 메시지를 전송할 수 있다. 이 네트워크는 여러 구성 요소 — buffers, channels, switches, controls — 로 이루어진 system이다.
이러한 정의를 만족하는 네트워크는 다양한 스케일에서 등장한다.
On-chip network는 단일 프로세서 내의 메모리 어레이, 레지스터, 연산 유닛 사이의 데이터를 전달한다.
Board-level, System-level 네트워크는 프로세서와 메모리, 또는 입력 포트와 출력 포트를 연결한다.
Local-area network (LAN), Wide-area network (WAN)는 서로 떨어진 시스템을 하나의 기업 또는 전 세계적으로 연결한다.
이 책에서는 chip-level에서 system-level까지의 작은 스케일만을 다룬다. 더 큰 스케일의 네트워크는 이미 우수한 참고서들이 존재하기 때문이다. 시스템 수준 이하에서는 채널 길이가 짧고 데이터 전송 속도가 매우 높기 때문에, 대규모 네트워크와는 근본적으로 다른 해결책이 요구된다.
그림 1.1: Interconnection network의 기능적 개요. T1~T6의 단말이 양방향 채널로 네트워크에 연결되어 있다. 각 채널의 양 끝에 있는 화살표는 데이터가 양방향으로 이동할 수 있음을 나타낸다.
Interconnection network는 어디에서 사용되는가? 서로 연결해야 할 두 개 이상의 구성 요소가 있는 거의 모든 디지털 시스템에서 사용된다. 가장 일반적인 응용처는 컴퓨터 시스템과 통신 스위치이다.
컴퓨터 시스템에서는 프로세서와 메모리, I/O 장치와 I/O 컨트롤러를 연결한다.
통신 스위치 및 네트워크 라우터에서는 입력 포트를 출력 포트에 연결한다.
제어 시스템에서는 센서와 액추에이터를 프로세서에 연결한다.
즉, 시스템의 두 구성 요소 간에 비트를 전송하는 곳이라면 어디든 interconnection network가 존재할 가능성이 높다.
1980년대 후반까지만 해도 이러한 많은 응용은 매우 단순한 interconnection인 multi-drop bus로 구현되었다. 만약 이 책이 그 시기에 쓰였다면, 아마도 버스 설계에 관한 책이 되었을 것이다. 현재도 버스는 많은 응용에서 중요하므로, 이 책의 Chapter 22에서 별도로 다룬다.
하지만 오늘날의 고성능 시스템에서는 point-to-point interconnection network가 대부분의 연결을 담당한다. 또한 전통적으로 버스를 사용해왔던 시스템들도 매년 네트워크 방식으로 전환되고 있다. 이러한 전환은 비균등한 성능 스케일링에 기인한다. 프로세서 성능과 함께 interconnection 성능 요구도 매년 약 50%씩 증가하는 반면, 배선(wire)은 더 빨라지지 않는다. 빛의 속도나 24 게이지 구리선의 감쇠 특성은 반도체 기술이 개선되어도 나아지지 않는다. 결과적으로 버스는 요구되는 bandwidth를 따라가지 못하고 있으며, 병렬성과 더 높은 속도를 제공하는 point-to-point interconnection network가 이를 대체하고 있다.
Interconnection network가 중요한 이유는 무엇인가? 이는 많은 시스템에서 성능의 제한 요소이기 때문이다.
프로세서와 메모리 사이의 interconnection network는 memory latency와 memory bandwidth를 결정하며, 이는 시스템 성능의 핵심 요소이다.
통신 스위치에서의 interconnection network (이 문맥에서는 fabric이라 부르기도 함)는 용량(capacity) — 즉 데이터 전송률과 포트 수 — 을 결정한다.
Interconnection 요구는 배선의 물리적 한계를 훨씬 앞질러 성장하고 있기 때문에, 대부분의 시스템에서 interconnection은 치명적인 병목 요소가 되었다.
또한 interconnection network는 전용 배선(dedicated wiring)에 비해 매력적인 대안이다. 이는 낮은 duty factor를 가지는 여러 신호들이 제한된 배선 자원을 공유할 수 있게 하기 때문이다. 예를 들어, Figure 1.1에서 각 단말이 100 클럭마다 다른 모든 단말에 1워드씩 통신한다고 하자. 모든 단말쌍 사이에 전용 채널을 제공하면 30개의 단방향 채널이 필요하며, 이 채널들은 99%의 시간 동안 유휴 상태일 것이다. 대신 여섯 개의 단말을 ring network로 연결하면 6개의 채널만 필요하다 (T1→T2, T2→T3, ..., T6→T1). 이 경우 채널 수는 5배 줄고, duty factor는 1%에서 12.5%로 증가한다.
1.2 Interconnection Networks의 용도
Interconnection network 설계에 요구되는 조건을 이해하려면, 디지털 시스템에서 이것이 어떻게 사용되는지를 살펴보는 것이 유용하다. 이 섹션에서는 세 가지 일반적인 용도를 살펴보며, 각각의 응용이 네트워크 설계에 어떤 요구를 가하는지 살펴본다. 특히 다음과 같은 네트워크 파라미터를 응용에 따라 분석한다:
단말의 수
각 단말의 최대 대역폭 (peak bandwidth)
각 단말의 평균 대역폭 (average bandwidth)
요구되는 지연 시간 (latency)
메시지 크기 혹은 메시지 크기의 분포
예상되는 트래픽 패턴
요구되는 Quality of Service
요구되는 신뢰도 및 가용성
단말 수 (또는 포트 수)는 네트워크에 연결해야 할 구성 요소의 수에 해당한다. 하지만 단말 수만 아는 것으로는 부족하고, 각 단말이 네트워크와 어떻게 상호작용하는지도 알아야 한다.
각 단말은 네트워크에서 일정량의 대역폭을 요구하며, 이는 보통 bit/s로 표현된다. 특별한 언급이 없으면 단말의 입출력 대역폭은 대칭(symmetric)하다고 가정한다.
Peak bandwidth는 단기간에 단말이 요구할 수 있는 최대 데이터율이고,
Average bandwidth는 장기적으로 요구되는 평균 데이터율이다.
다음 섹션에서 processor-memory interconnect 설계를 통해 보여주듯, peak와 average bandwidth 모두를 아는 것이 네트워크의 구현 비용을 최소화하는 데 중요하다.
또한 네트워크가 메시지를 수신하고 전달하는 속도 외에도, 개별 메시지를 전달하는 데 걸리는 시간, 즉 메시지 지연 시간(latency) 역시 명시되어야 한다. 이상적인 네트워크는 고대역폭과 저지연을 모두 지원하지만, 이 두 가지 특성 사이에는 종종 트레이드오프가 존재한다. 예를 들어, 고대역폭을 지원하는 네트워크는 네트워크 자원을 계속 바쁘게 유지하므로, resource contention이 자주 발생한다. 즉, 여러 메시지가 동시에 동일한 공유 자원을 사용하려 하면, 하나를 제외한 나머지는 해당 자원이 사용 가능해질 때까지 기다려야 하므로 latency가 증가한다. 반대로, 대역폭 요구를 줄이면 자원 사용률이 낮아지므로 latency도 감소할 수 있다.
Message size, 즉 메시지의 비트 길이도 중요한 설계 고려 요소이다. 메시지가 작을 경우, 네트워크 오버헤드가 성능에 더 큰 영향을 미치게 된다. 반면 메시지가 크면 오버헤드를 메시지 길이에 걸쳐 분산시켜 감쇠시킬 수 있다. 많은 시스템에서는 여러 가지 가능한 메시지 크기가 존재한다.
각 단말에서 보낸 메시지가 가능한 목적지 단말 전체에 어떻게 분포되는가를 트래픽 패턴(traffic pattern)이라 한다. 예를 들어, 각 단말이 모든 다른 단말에 동일한 확률로 메시지를 보내는 경우를 무작위 트래픽 패턴(random traffic pattern)이라 한다. 반대로 단말들이 주로 가까운 단말에만 메시지를 보내는 경향이 있다면, underlying network는 이러한 공간적 지역성(spatial locality)을 활용하여 비용을 줄일 수 있다. 그러나 어떤 네트워크에서는 임의의 트래픽 패턴에서도 사양이 유지되는 것이 중요하다.
일부 네트워크에서는 QoS (Quality of Service) 요구사항도 있다. 대략적으로 QoS란 특정 서비스 정책 하에서 자원을 공정하게 분배하는 것이다. 예를 들어, 여러 메시지가 동일한 네트워크 자원을 놓고 경쟁할 때, 이를 해결하는 방식은 여러 가지다. 메시지가 해당 자원을 기다린 시간에 따라 선착순(First-Come, First-Served) 방식으로 처리할 수도 있고, 네트워크 내에서 가장 오래 있었던 메시지에 우선순위(priority)를 줄 수도 있다. 어떤 자원 할당 정책을 선택할지는 네트워크에서 요구하는 서비스에 따라 달라진다.
마지막으로, 신뢰도(reliability)와 가용성(availability)도 interconnection network의 설계에 영향을 준다.
신뢰도란 메시지를 올바르게 전달하는 네트워크의 능력을 말한다. 대부분의 경우 메시지는 100% 전달되어야 하며 손실이 없어야 한다. 이를 실현하기 위해 에러 검출 및 수정 하드웨어, 상위 소프트웨어 프로토콜, 또는 이들의 조합을 사용할 수 있다.
일부 경우, 이후에 설명할 packet switching fabric에서는 극소수의 메시지가 손실되는 것을 허용할 수도 있다.
네트워크의 가용성은 전체 시간 중 네트워크가 정상적으로 작동한 비율을 의미한다. 인터넷 라우터의 경우, 일반적으로 99.999% (5 nines) 가용성이 요구되며, 이는 연간 총 다운타임이 5분 미만임을 의미한다. 그러나 네트워크를 구성하는 부품은 종종 분당 여러 번 고장나기도 하므로, 이러한 수준의 가용성을 달성하려면 네트워크는 장애를 감지하고 신속하게 복구하면서도 동작을 지속해야 한다.
1.2.1 Processor-Memory Interconnect
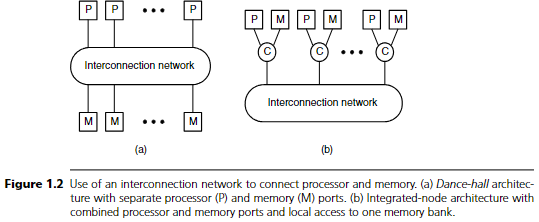
그림 1.2는 processor와 memory를 연결하기 위한 interconnection network의 두 가지 구조를 보여준다.
(a) Dance-hall 구조는 P개의 프로세서와 M개의 메모리 뱅크를 interconnection network로 연결한다.
(b) Integrated-node 구조는 processor와 memory를 하나의 노드에 통합하고, 이 로컬 메모리에는 switch C를 통해 직접 접근할 수 있게 한다.
Dance-hall이라는 이름은 구식 댄스홀처럼, 프로세서들이 네트워크 한쪽에 줄지어 서고, 메모리들이 반대쪽에 줄지어 서는 배치를 닮았기 때문이다.
Table 1.1은 이 두 구성에서 네트워크에 요구되는 파라미터를 요약한 것이다.
ParameterValue
Processor ports
1–2,048
Memory ports
0–4,096
Peak bandwidth
8 Gbytes/s
Average bandwidth
400 Mbytes/s
Message latency
100 ns
Message size
64 또는 576 bits
Traffic patterns
arbitrary (임의)
Quality of service
없음
Reliability
메시지 손실 없음
Availability
0.999 ~ 0.99999
예를 들어 Cray T3E와 같이 최대 구성 시 2,176개의 processor ports를 가진 경우도 있으며, 단일 프로세서 시스템에서는 1개의 포트만 필요하다. 64~128개의 프로세서를 가진 구성은 고급 서버에서 흔하며, 이 수는 시간이 갈수록 증가하는 추세다.
Integrated-node 구성에서는 각 processor port가 memory port 역할도 한다.
반면 dance-hall 구성에서는 memory port 수가 processor port보다 훨씬 많다. 예: 어떤 벡터 프로세서는 32개의 processor port가 4,096개의 memory bank에 접근한다. 이는 memory bandwidth를 극대화하고 bank conflict(동일한 bank에 여러 프로세서가 동시에 접근하는 경우)를 줄이기 위한 것이다.
현대의 마이크로프로세서는 초당 약 10억 개의 명령어를 실행하며, 각 명령어는 memory에서 64비트 word 두 개를 요구할 수 있다 (하나는 명령어 자체, 다른 하나는 데이터). 이 중 하나가 캐시에 없으면 일반적으로 8-word block을 memory에서 가져온다. 만약 매 cycle마다 2 word를 memory에서 가져와야 한다면 16GB/s의 bandwidth가 필요하다.
다행히도:
모든 명령어가 메모리 참조를 하는 것은 아니며 (약 1/3),
cache hit ratio가 높아서 실제 memory 접근 수는 줄어든다.
따라서 평균 bandwidth는 훨씬 낮아져 보통 400MB/s 수준이 된다. 하지만 burst traffic을 처리하기 위해서는 8GB/s의 peak bandwidth가 여전히 필요하다. 만약 peak bandwidth를 너무 제한하면 갑작스러운 요청이 발생했을 때 네트워크 포트가 막혀 serialization이 발생하고, 이는 지연(latency)을 증가시킨다. 이 현상은 막힌 싱크대가 천천히 물을 빼내는 것에 비유할 수 있다.
또한, memory latency는 processor 성능에 민감한 영향을 미친다. Table 1.1에서는 기본 메모리 시스템의 latency를 100ns로 보고 있는데, 네트워크가 추가로 100ns를 더한다면 실효 메모리 지연이 2배가 된다.
캐시에 없는 load/store 명령어는 read-request 또는 write-request packet으로 변환되어 네트워크를 통해 해당 memory bank로 전송된다.
Read-request packet: 읽을 memory address 포함
Write-request packet: 주소 + 데이터 word 또는 캐시라인 포함
memory bank는 요청을 수행한 후, 응답 packet을 다시 보낸다 (read-reply 또는 write-reply).
이 시점에서, message와 packet을 구분하기 시작한다.
Message는 processor 또는 memory와 네트워크 간의 전송 단위이고,
Packet은 그 message가 네트워크 내부에서 분할되거나 고정 길이로 변환된 형태이다.
Processor-memory interconnect에서는 message와 packet이 1:1 대응한다고 가정할 수 있다.
그림 1.3: 두 개의 packet format
Read-request / Write-reply: 64비트 헤더 + 주소
Read-reply / Write-request: 위의 64비트 정보 + 512비트 데이터 (캐시라인) = 576비트
이러한 interconnect는 QoS를 요구하지 않는다. 그 이유는 시스템이 자체 조절(self-throttling) 메커니즘을 갖기 때문이다. 네트워크 혼잡이 발생하면 요청 지연이 늘어나고, processor는 응답을 기다리며 유휴 상태가 된다. 이로 인해 새로운 요청이 줄어들고 혼잡이 완화된다. 이런 안정화 특성 덕분에 QoS는 필요하지 않다.
하지만 신뢰성(reliability)은 필수이다.
memory request/reply packet이 절대 손실되면 안 된다.
손실되면 해당 memory operation이 무한히 대기 상태가 되어, 최소한 사용자 프로그램이 crash되고, 심하면 시스템 전체가 다운될 수 있다.
신뢰성을 갖추기 위해, 일부 시스템은 acknowledgment 기반 재전송 프로토콜을 쓸 수 있다 (자세한 내용은 Chapter 21 참조). 하지만 이는 latency를 증가시켜 processor-memory interconnect에는 적합하지 않다.
이러한 시스템은 보통 가용성 99.9% ~ 99.999% 수준을 요구한다.
1.2.2 I/O Interconnect
그림 1.4: 일반적인 I/O 네트워크는 여러 개의 host adapter(HA)를 더 많은 수의 I/O 디바이스(예: 디스크 드라이브)에 연결한다.
I/O 네트워크는 granularity와 timing 면에서 processor-memory 네트워크와 다르다. 특히 latency에 대한 관용성 증가는 네트워크 설계를 완전히 다른 방향으로 이끈다.
디스크 작업은 일반적으로 4Kbyte 이상의 sector 단위로 수행된다. 디스크의 회전 지연(rotational latency)과 헤드 이동 시간 때문에, 섹터 하나를 접근하는 데 걸리는 latency는 수 밀리초에 달할 수 있다. 디스크 읽기 작업은 host adapter에서 디스크 주소(device, sector)와 메모리 블록 주소를 지정한 control packet을 전송하면서 시작된다. 디스크는 이 요청을 수신하고 헤드를 해당 섹터로 이동시킨 뒤, 해당 sector를 읽고, 지정된 메모리 블록으로의 response packet을 host adapter에 보낸다.
표 1.2 I/O interconnection network의 파라미터
ParameterValue
Device ports
1–4,096
Host ports
1–64
Peak bandwidth
200 Mbytes/s
Average bandwidth
1 Mbytes/s (devices)
64 Mbytes/s (hosts)
Message latency
10 μs
Message size
32 bytes 또는 4 Kbytes
Traffic patterns
arbitrary
Reliability
no message loss (소량은 허용)a
Availability
0.999 ~ 0.99999
a) 일부 메시지 손실은 허용된다. 실패한 메모리 접근보다 실패한 I/O 작업의 복구가 더 유연하게 처리되기 때문이다.
디스크 포트의 peak-to-average bandwidth ratio는 매우 크다. 디스크가 연속된 sector를 전송할 때는 200MB/s의 속도로 데이터를 읽을 수 있지만, 실제로는 각 sector 간에 헤드 이동 시간이 평균 5ms 이상 걸려서, 평균 데이터 속도는 1MB/s 이하로 낮아진다. Host 포트는 64개의 디스크 포트 트래픽을 집계하므로 이보다는 안정적인 대역폭을 가진다.
이처럼 peak과 average bandwidth 차이가 큰 경우, 모든 디바이스의 최대 대역폭을 동시에 지원하는 네트워크를 설계하면 비용이 매우 높아진다. 반대로 평균 대역폭만 지원하도록 설계하면, processor-memory 예시처럼 serialization latency 문제가 생긴다. 따라서 여러 디바이스의 요청을 집계 포트(aggregate port)로 concentration하는 방식이 효과적이다. 이로 인해 평균 bandwidth 수요는 커지지만, 실제로 동시에 최고 대역폭을 요구하는 디바이스는 극소수에 불과하므로 과도한 serialization 없이 저비용 구현이 가능하다.
메시지의 payload는 이중 분포(bimodal)를 가지며, 두 가지 크기 간의 차이가 크다.
짧은 32바이트 메시지: read 요청, write 완료 ack, 디스크 제어용
긴 메시지 (예: 4Kbyte, 실제는 8Kbyte 포함됨): read-reply, write-request 등
디스크 작업은 본질적으로 latency가 크고, 전송 단위가 크기 때문에, 이 네트워크는 latency에 민감하지 않다. 예를 들어, latency가 10μs로 증가해도 성능 저하는 무시할 수 있는 수준이다. 이러한 관용성 덕분에 processor-memory에 비해 효율적인 네트워크를 훨씬 쉽게 구축할 수 있다.
한편, 클러스터 기반 병렬 컴퓨터에서 사용하는 inter-processor 통신 네트워크는 bandwidth와 granularity 면에서 I/O 네트워크와 유사하므로 따로 다루지 않는다. 이러한 네트워크는 system-area network (SAN)라고 불리며, I/O 네트워크와의 주요 차이는 latency에 더 민감하다는 점이다 (보통 몇 마이크로초 이하 요구).
한편, 디스크 스토리지를 기업의 핵심 데이터를 저장하는 데 사용하는 경우, 매우 높은 가용성이 요구된다. 스토리지 네트워크가 멈추면 곧 비즈니스 전체가 중단되기 때문이다. 이 때문에 0.99999 (five nines) 수준 — 연간 다운타임 5분 이하 — 이 일반적이다.
1.2.3 Packet Switching Fabric
Packet switching fabric은 통신 네트워크 스위치 및 라우터에서 버스와 크로스바를 대체하는 역할을 한다. 이 경우 interconnection network는 보다 큰 네트워크(IP 기반의 LAN 또는 WAN)의 라우터 내부 요소로 동작한다.
그림 1.5: 스위칭 패브릭으로 interconnection network를 사용하는 네트워크 라우터. 여러 line card 간의 패킷 전송을 담당한다.
대규모 네트워크 채널 (보통 2.5Gbps 또는 10Gbps 광섬유)을 종료하는 여러 line card들이 있고, 각 라인카드는:
패킷을 받아서 목적지를 파악하고,
QoS 정책 준수 여부를 검사하고,
패킷의 특정 필드를 재작성하고,
통계 정보를 업데이트한 후,
해당 패킷을 fabric으로 전달한다.
fabric은 이 패킷을 출발지 line card에서 목적지 line card로 전송하는 역할을 수행한다. 목적지 line card는 해당 패킷을 큐에 저장하고, 이후 출력 채널로 송신하도록 스케줄링한다.
표 1.3 Packet switching fabric의 파라미터
ParameterValue
Ports
4–512
Peak Bandwidth
10 Gbits/s
Average Bandwidth
7 Gbits/s
Message Latency
10 μs
Packet Payload Size
40–64 Kbytes
Traffic Patterns
arbitrary
Reliability
10⁻¹⁵ 이하의 손실률
Quality of Service
필요함
Availability
0.999 ~ 0.99999
라우터에서 사용하는 프로토콜에 따라 패킷 크기가 달라지지만, 예를 들어 IP의 경우 40바이트~64Kbytes까지 다양하며, 일반적으로는 40, 100, 1,500바이트 패킷이 많다. 이처럼 다른 예시들과 마찬가지로, 이 네트워크도 짧은 제어 메시지와 큰 데이터 전송 간의 분리가 있다.
스위칭 패브릭은 processor-memory나 I/O 네트워크처럼 self-throttling 하지 않다. 각 line card는 네트워크 혼잡과 무관하게 계속 패킷을 전송하며, 동시에 일부 패킷 클래스에는 보장된 bandwidth를 제공해야 한다. 이를 위해 fabric은 non-interfering해야 한다. 즉:
a로 가는 트래픽이 많더라도,
b로 가는 트래픽의 bandwidth를 침해하지 않아야 한다.
이는 a와 b 간 트래픽이 자원을 공유하더라도 마찬가지다.
이런 비간섭성 요구는 fabric 구현에 특별한 제약 조건을 부과한다.
흥미로운 점은, 일부 경우 극히 낮은 확률의 패킷 손실은 허용 가능하다는 것이다. 예를 들어:
입력 광섬유에서의 비트 오류 (10⁻¹² ~ 10⁻¹⁵ 확률),
line card 큐 오버플로우 등, 이미 다른 이유로 인해 패킷이 손실될 수 있기 때문에, 내부 네트워크 bit error와 같은 매우 드문 상황에서는 패킷을 드롭해도 무방하다. 단, 이 손실률은 다른 원인보다 훨씬 낮아야 한다.
이는 processor-memory interconnect와는 대조된다. 이 경우 패킷 1개라도 손실되면 시스템 전체가 정지될 수 있기 때문이다.
1.3 Network Basics
특정 응용 분야(앞에서 설명한 바와 같은)의 성능 사양을 충족시키기 위해, 네트워크 설계자는 topology, routing, flow control을 구현함에 있어 기술적 제약 내에서 작업해야 한다. 앞에서 언급했듯, interconnection network의 효율성의 핵심은 통신 자원이 공유된다는 점이다. 각 terminal 쌍마다 전용 채널을 만드는 대신, interconnection network는 공유 채널로 연결된 공유 router node 집합으로 구현된다. 이 노드들의 연결 패턴이 곧 topology를 정의한다.
메시지는 출발 terminal에서 목적지 terminal까지 여러 shared channel과 node를 거쳐 전달된다. 좋은 topology는 패키징 기술의 특성 — 예: 칩의 핀 수, 캐비닛 간 연결 가능한 케이블 수 — 을 잘 활용하여 network bandwidth를 극대화할 수 있어야 한다.
Toplogy가 정해지면, 메시지가 목적지에 도달하기까지의 가능한 경로(노드와 채널의 시퀀스)는 여러 가지가 될 수 있다. Routing은 메시지가 어떤 경로를 실제로 따를지를 결정한다. 좋은 경로 선택은 경로 길이(보통 노드 수나 채널 수로 측정)를 최소화하고, 동시에 공유 자원에 걸리는 부하(load)를 고르게 분산시켜야 한다.
경로가 길수록 latency가 늘어나고,
자원 중 어떤 것은 과하게 사용되고, 다른 것은 유휴 상태인 load imbalance가 발생하면 network의 총 bandwidth는 줄어든다.
Flow control은 시간 흐름에 따라 어떤 메시지가 어떤 network 자원을 사용할지를 결정한다. 자원 사용률이 증가할수록 flow control의 중요성은 커진다. 좋은 flow control은 최소 지연으로 packet을 전달하면서, 높은 부하 상태에서도 자원을 놀리지 않는다.
1.3.1 Topology
Interconnection networks는 router node들과 channel들로 구성되며, topology는 이들의 배치 방식을 의미한다. Topology는 도로 지도에 비유할 수 있다. Channel은 자동차가 다니는 도로처럼 packet을 한 router node에서 다른 router node로 운반한다. 예를 들어 Figure 1.6에 나온 network는 16개의 노드로 구성되며, 각 노드는 4개의 이웃과 양방향 연결(총 8개의 채널)되어 있다. 이 네트워크는 torus topology이다. 각 노드는 terminal과 직접 연결된 direct network 구성이다.
좋은 topology는 사용 가능한 패키징 기술의 특성을 활용하여 최소 비용으로 응용의 bandwidth와 latency 요구를 충족시킨다. Topology는 시스템 중간(bisection)을 가로지르는 bisection bandwidth를 최대한 활용해야 한다.
Figure 1.6: 4×4 torus (또는 4-ary 2-cube) topology. 각 노드는 4개의 이웃과 각각 송수신 채널로 연결되어 총 8개의 채널을 가진다.
Figure 1.7은 Figure 1.6의 네트워크를 실제로 어떻게 패키징할 수 있는지를 보여준다.
4개의 노드를 하나의 printed circuit board (PCB)에 배치하고,
4개의 보드를 backplane 보드로 연결한다 (PC에서 PCI 카드가 motherboard에 꽂히듯).
이 시스템에서 bisection bandwidth는 backplane을 통해 전달될 수 있는 최대 bandwidth이다.
backplane이 256개의 신호선(signal)을 가진다고 가정하고,
각 signal이 1Gbps 속도로 동작한다면, 전체 bisection bandwidth는 256Gbps이다.
Figure 1.7: 16-node torus topology의 패키징. 4개의 PCB가 backplane을 통해 연결된다. backplane의 너비를 가로지르는 256개 신호선이 이 시스템의 bisection bandwidth를 결정한다.
다시 Figure 1.6을 보면, 중간을 가로지르는 unidirectional channel이 총 16개이다. (그림상의 선 하나는 양방향 채널 2개를 의미함) 따라서 bisection bandwidth를 포화시키려면 각 채널은 256/16 = 16 signals를 가져야 한다. 한편, 각 노드는 단일 IC 칩에 패키징되며, 칩은 최대 128개의 핀만 사용할 수 있다. 이 topology는 노드당 8개 채널이므로, 각 채널당 할당 가능한 핀 수는 128/8 = 16 signals이다. → 핀 제한과 포화 조건이 일치하는 이상적인 구성이다.
반면, Figure 1.8과 같이 16-node ring topology를 고려해보자.
노드당 4개 채널만 존재하므로 핀 제한은 128/4 = 32 signals/channel이 된다.
bisection을 통과하는 채널은 4개이므로 이상적인 설계는 채널당 256/4 = 64 signals/channel이지만,
핀 제한으로 인해 실제 채널 폭은 32 signal로 제한된다. → 결국, ring topology는 torus topology의 절반 bandwidth만 제공한다.
Figure 1.8: 동일한 기술 제약 조건 하에서 ring topology는 torus보다 낮은 throughput을 가지지만 latency는 더 낮을 수 있다.
그러나 bandwidth만이 topology 선택의 기준은 아니다. 다른 응용에서 필요한 bandwidth가 16Gbps 수준으로 낮지만 latency가 중요하다면, 4096-bit의 긴 packet을 사용하고 있다면, → 작은 hop 수와 낮은 serialization latency의 균형을 맞추는 topology가 필요하다.
Hop count: 메시지가 목적지까지 평균적으로 거치는 노드/채널 수
Node degree를 높이면 hop count는 줄지만,
채널 수가 늘어나면 채널 폭은 좁아지고, 긴 패킷은 serialization latency가 커진다.
예를 들어,
random traffic을 가정하면, torus의 평균 거리 = 2 hops, ring = 4 hops
→ ring의 총 latency: 80 + 128 = 208ns → torus의 총 latency: 40 + 256 = 296ns
결론: 긴 패킷에서는 오히려 ring topology가 latency 면에서 우수할 수 있다.
요약: 모든 응용에 적합한 최적의 topology는 없다. 제약 조건과 요구사항에 따라 적절한 topology가 달라진다.
1.3.2 Routing
Routing은 source terminal node에서 destination terminal node까지의 경로를 결정한다. 경로는 channel들의 순서 집합 P = {c₁, c₂, ..., cₖ} 로 정의되며,
cᵢ의 출력 노드 = cᵢ₊₁의 입력 노드
c₁의 입력 = source
cₖ의 출력 = destination
어떤 네트워크에서는 source→destination 경로가 유일할 수도 있지만, Figure 1.6의 torus network처럼 경로가 여러 개 존재할 수도 있다. 이럴 경우, 좋은 routing 알고리즘은 어떤 traffic pattern에서도 채널 간 부하를 고르게 분산해야 한다.
topology는 roadmap,
routing은 네트워크 교차로에서 방향을 정하는 운전자의 turning decision이다.
부하 균형을 위해, 일부 경로에 트래픽이 몰리지 않도록 해야 한다.
Figure 1.9(a): node 01에서 node 22로 가는 dimension-order routing → x방향으로 먼저 이동 후, y방향으로 이동 (01 → 21 → 22). → 최소 경로 (min-hop). 이 경우 가능한 최소 경로가 총 6개 존재한다.
Dimension-order routing은 간단하고 minimal하지만, 일부 traffic pattern에서는 심각한 load imbalance를 유발할 수 있다. 예를 들어, Figure 1.9(a)에서 node 11에서 node 20으로 가는 또 다른 dimension-order 경로를 추가한다고 하자. 이 경로 역시 node 11에서 node 21로 가는 채널을 사용하므로, 해당 채널의 부하(load)가 2배가 된다.
Channel load는 terminal node들이 해당 채널을 통해 보내려고 하는 평균 bandwidth를 의미한다. 이 load를 terminal이 네트워크에 주입할 수 있는 최대 rate로 정규화하면, 해당 채널의 load는 2가 된다. 더 나은 routing 알고리즘을 사용하면 이 값을 1로 줄일 수 있다. Dimension-order routing은 특정 채널에 불필요한 중복 부하를 발생시키므로, 이 traffic pattern 하에서 네트워크의 전체 bandwidth는 최대의 절반에 불과하다.
일반적으로 deterministic routing algorithm — 즉 source-destination 쌍마다 고정된 단일 경로를 선택하는 알고리즘 — 은 이러한 load imbalance로 인해 낮은 bandwidth를 보이는 경향이 있다. Routing 알고리즘 설계와 관련된 이와 같은 이슈는 Chapters 8–10에서 더 자세히 다룬다.
1.3.3 Flow Control
Flow control은 packet이 경로를 따라 진행함에 따라 자원의 할당을 관리한다. 대부분의 interconnection network에서 핵심 자원은 channel과 buffer이다. Channel은 노드 간에 packet을 운반하는 역할을 하며, Buffer는 각 노드 내에 구현된 저장 공간(레지스터나 메모리 등)으로, packet이 다음 자원을 기다리는 동안 임시로 저장된다.
이전의 아날로지를 이어서 보면:
Topology는 지도,
Routing은 교차로에서의 steering 결정,
Flow control은 신호등이다. → 즉, 차(=packet)가 다음 도로(channel)로 진행해도 되는지, 혹은 다른 차를 위해 parking lot(buffer)으로 비켜야 하는지를 결정한다.
Figure 1.9: (a) Dimension-order routing: x 방향 → y 방향 (b) Non-minimal route: 최소 경로보다 더 많은 hop을 거친다
Topology와 Routing의 잠재적 성능을 실현하려면, Flow control 전략은 자원 충돌(resource conflict)을 피해야 한다. 예: 어떤 packet이 비어 있는 채널을 사용할 수 있음에도, 혼잡한 채널 때문에 막힌 다른 packet이 점유 중인 buffer를 기다리느라 진행하지 못하는 상황은 피해야 한다. → 이 상황은, 좌회전 하려는 차 때문에 직진하려는 차가 막히는 것과 같다. → 해결책은 도로에 좌회전 전용 차선을 추가하는 것처럼, 자원 의존을 분리해주는 것이다.
좋은 flow control은 공정하고(fair), deadlock을 피해야 한다.
공정하지 않으면 어떤 packet은 무한정 대기할 수 있으며,
Deadlock은 여러 packet이 서로 자원을 기다리며 순환적으로 막혀 있는 상태를 의미한다. → 도로에서의 gridlock에 해당한다.
Flow control 방식은 종종 시간-공간 다이어그램(time-space diagram)으로 표현된다.
Figure 1.10: Flow control 비교
(a) Store-and-forward: 각 채널마다 packet 전체(5 flits)가 전달되어야 다음 채널로 진행 가능
(b) Cut-through: 각 flit이 도착하는 대로 다음 채널로 바로 진행, pipelining
수평축: 시간(cycle)
수직축: 공간(channel ID)
Flit (flow control digit): flow control 수준에서 가장 작은 단위 → flit을 고정된 크기로 정하면 router 설계가 간단해지고, 길이가 일정하지 않은 packet도 처리할 수 있다.
→ Flow control 방식은 latency에 큰 영향을 미친다.
Flow control의 자세한 내용은 Chapters 12–13, 관련 문제들 (deadlock, livelock, tree saturation, QoS 등)은 Chapters 14–15에서 다룬다.
1.3.4 Router Architecture
Figure 1.11: router의 block diagram
입력 채널마다 buffer
crossbar switch
allocator
Figure 1.6에 나온 16개의 노드 중 하나의 내부를 단순화하여 나타낸 그림이다.
각 입력 채널에는 buffer가 연결되어 있고,
buffer에 들어온 flit은 경로 상 다음 노드(router)의 buffer 공간이 확보되면 → crossbar switch에 대한 접근 권한을 요청한다.
Crossbar switch는 어느 입력 buffer든지 어느 출력 채널로든 연결할 수 있으나,
입력 하나는 출력 하나에만, 출력 하나도 입력 하나에만 연결 가능하다.
Allocator는 crossbar와 공유 자원에 대한 요청을 처리한다. → flit이 다음 router로 진행하려면,
다음 노드의 buffer 공간 확보
다음 채널의 bandwidth 확보
crossbar 통과 권한 확보
Router architecture는 Chapters 16–21에서 상세히 다룬다.
1.3.5 Performance of Interconnection Networks
Interconnection network의 성능은 보통 latency vs. offered traffic curve로 설명된다.
Figure 1.12: offered traffic(수평축)에 따른 평균 latency(수직축)
Latency: packet의 첫 비트가 source terminal에 도착한 시점부터, 마지막 비트가 destination terminal에 도착한 시점까지 걸린 시간
Offered traffic: 각 source terminal이 생성하는 평균 트래픽 (bits/s)
이 곡선을 정확히 얻기 위해선 트래픽 패턴 (예: random traffic)도 명시해야 한다. → 이 곡선은 정확하긴 하나, 폐쇄형 수식이 없으며 discrete-event simulation으로 계산된다.
설계 초기 단계에서는 topology, routing, flow control 관점에서 점진적으로 성능을 이해하는 방식이 유용하다.
Zero-load latency는 네트워크에서 경쟁 없이 packet이 전달될 때의 최소 평균 지연 시간이다.
구성 요소: serialization latency + hop latency
예:
topology = torus (Figure 1.6)
L = 512 bits,
channel bandwidth = b = 16 Gbps
routing: minimal, random traffic → serialization latency = L/b = 32ns → 평균 hop 수 = Hₘᵢₙ = 2 → router latency tᵣ = 10ns → hop latency = 2 × 10 = 20ns → 최소 latency = 32 + 20 = 52ns
Routing 알고리즘이 실제로 사용하는 hop 수 Hₐᵥg를 고려하면, 이보다 큰 latency가 된다 (Hₐᵥg ≥ Hₘᵢₙ). 또한 flow control이 추가로 성능을 저하시킬 수 있다.
앞서 설명한 Figure 1.12에서, 실제 zero-load latency T₀는 topology, routing, flow control에 의해 결정되는 제약을 모두 포함한다. 이러한 점진적으로 정밀해지는 latency의 상한들은 Figure 1.12에서 수평 비대칭선(horizontal asymptote)으로 표시된다.
비슷한 방식으로 throughput(처리율)에 대해서도 상한을 설정할 수 있다.
Source는 일정량의 traffic을 network에 제공하지만,
Throughput, 또는 accepted traffic은 destination terminal에 성공적으로 전달된 데이터율(bits/s)이다.
예를 들어, random traffic을 가정하면 전체 traffic의 절반이 network의 bisection을 통과해야 한다.
bisection은 16개 채널, 총 bandwidth B_c = 256 Gbps
node당 traffic 한계 = 2B_c / N = 32 Gbps (N=16)
이는 traffic이 bisection을 균등하게 분산시킨다는 이상적인 가정 하에서만 성립한다.
→ 실제 routing 알고리즘 R의 효과를 고려한 throughput Θ_R은 불균형이 존재하면 이보다 낮을 수 있다 (Θ_R ≤ 2B_c / N) → Flow control이 자원 의존성 때문에 채널을 유휴 상태로 만든다면, 실제 saturation throughput λ_s는 Θ_R보다도 훨씬 낮을 수 있다.
이러한 throughput의 3단계 상한은 Figure 1.12에서 수직 비대칭선(vertical asymptote)으로 표시된다.
이렇게 topology → routing → flow control로 점진적으로 성능을 분석하는 방식은 각 설계 요소가 성능에 어떻게 영향을 미치는지 불필요한 복잡성 없이 확인할 수 있게 해준다. 예: topology 선택이 latency에 미치는 영향은, routing과 flow control을 따로 고려하지 않고도 파악 가능하다.
반면, 성능 분석을 한 번에 모두 고려하려 하면 개별 설계 선택이 끼치는 영향이 흐려진다.
이러한 성능 모델링의 점진적 접근법을 수립한 후, 전체적인 관점에서의 성능 분석은 Chapters 23–25에서 다룬다. 이들 챕터에서는:
성능 측정에서의 미묘한 문제
queueing theory 및 probability theory 기반의 분석 기법
simulation을 통한 성능 측정 방법
예시 측정 결과들을 설명한다.
1.4 History
Interconnection network는 수십 년에 걸쳐 발전해 온 풍부한 역사를 가지고 있다. 발전 경로는 크게 세 가지 병렬적 흐름으로 진행되었다:
Telephone switching networks
Inter-processor communication
Processor-memory interconnect
Telephone switching networks
전화가 등장한 이래로 존재해온 시스템이다. 초기 telephone network는 전기기계식 crossbar 또는 step-by-step switch로 구축되었으며, 1980년대까지도 많은 지역 전화 교환기는 여전히 electro-mechanical relay로 구성되어 있었다. 반면, 장거리 통화용(toll) switch는 이미 전자식, 디지털화가 완료되었다.
주요 발전 사례:
1953년: Clos network (non-blocking multistage)
1962년: Beneš network → 현재도 많은 대형 telephone switch는 Clos 또는 Clos 기반 네트워크로 구현된다.
Inter-processor interconnection networks
초기의 processor 간 연결은 2D 배열 내 이웃한 processor의 레지스터를 직접 연결하는 방식이었다. 예: 1962년 Solomon machine [172] — 이들 초기 네트워크는 routing 기능이 없었기 때문에, 이웃이 아닌 processor와 통신하려면 중간 processor가 명시적으로 relay해야 했다. → 이는 성능 저하와 프로그래밍 복잡성 증가로 이어졌다.
1980년대 중반부터는 processor 개입 없이 메시지를 forwarding할 수 있는 router chip이 등장했다. 예: torus routing chip [56]
Topology 측면에서는 시간 흐름에 따라 다양한 유행이 있었다:
초기 (Solomon, Illiac, MPP 등): 2D mesh 또는 torus → 물리적 규칙성 때문
1970년대 후반부터: binary n-cube (hypercube) → low diameter → 대표 기기: Ametek S14, Cosmic Cube, nCUBE, Intel iPSC 시리즈
하지만 1980년대 중반 이후 실제 패키징 제약 하에서는 low-dimensional network가 hypercube보다 우수하다는 사실이 밝혀졌고, → 다시 대부분의 시스템이 2D 또는 3D mesh/torus로 회귀하였다.
대표 기기:
J-machine [138]
Cray T3D, T3E
Intel DELTA
Alpha 21364
최근에는 message 길이에 비해 router chip의 핀 대역폭(pin bandwidth)이 높아지면서, node degree가 높은 topology인 butterfly, Clos network 사용이 다시 증가하고 있다.
Processor-memory interconnect
1960년대 말부터 등장. → 병렬 프로세서 시스템에서 어떤 processor든지 어떤 memory bank에 접근할 수 있도록 하기 위해 alignment network를 도입함.
소형 시스템: crossbar 사용
대형 시스템: butterfly topology, dance-hall 구성
이러한 방식은 1980년대에도 많은 shared-memory parallel processor에서 활용되었다.
세 흐름의 통합
1990년대 초 이후, processor-memory와 inter-processor network 설계의 차이는 거의 사라졌다. → 동일한 router chip이 양쪽에 사용되고 있음 → telephone에서 사용되던 Clos 및 Beneš network도 fat-tree topology 형태로 multiprocessor network에 적용되고 있다 [113]
이 역사에서는 주로 topology에 초점을 맞췄지만, routing과 flow control도 동시에 발전해왔다.
초기 routing chip: deterministic routing, circuit-switching 또는 store-and-forward packet switching 사용
이후: adaptive routing, deadlock avoidance, virtual-channel flow control 등장
1.5 Organization of this Book
다음 장에서는 먼저 하나의 완전한 interconnection network를 topology부터 logic gate 수준까지 설명한다. → 전체적인 구조를 먼저 보여주고, 이후에 세부로 들어가는 방식이다.