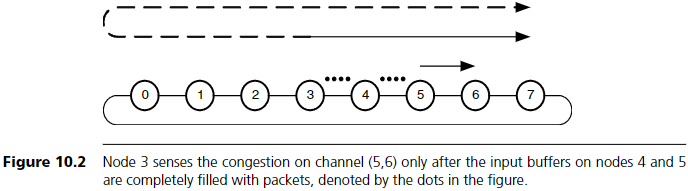
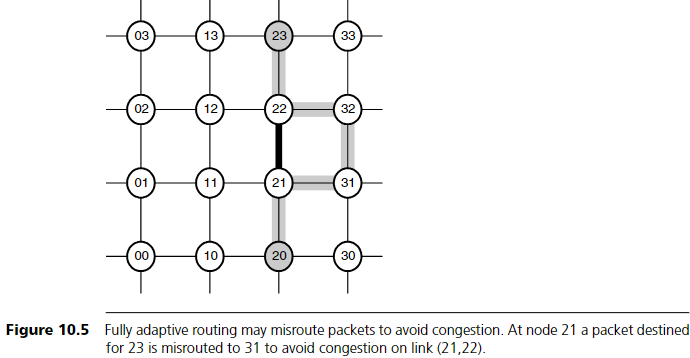
네트워크에 버퍼를 추가하면 플로우 제어의 효율성이 크게 향상된다.
버퍼는 인접 채널들의 할당을 분리(decouple)시켜주기 때문이다.
버퍼가 없으면 두 채널은 연속된 사이클 동안 패킷(또는 flit)에 동시에 할당되어야 하며, 그렇지 않으면 패킷은 폐기되거나 잘못된 경로로 전달되어야 한다.
패킷이 머무를 곳이 없기 때문이다.
버퍼를 추가하면 두 번째 채널을 기다리는 동안 패킷(flits 포함)을 저장할 수 있어, 두 번째 채널의 할당을 지연시켜도 문제가 발생하지 않는다.
버퍼가 추가되면 플로우 제어 메커니즘은 채널 대역폭뿐 아니라 버퍼까지 할당해야 하며, 이들 자원을 어떤 단위(granularity)로 할당할지도 선택해야 한다.

그림 13.1과 같이, 버퍼와 채널 대역폭은 flit 또는 packet 단위로 할당할 수 있다.
대부분의 플로우 제어 방식은 두 자원을 동일한 단위로 할당한다.
패킷 단위로 채널 대역폭과 버퍼를 모두 할당하는 경우는 packet-buffer flow control이며, 이에는 store-and-forward flow control과 cut-through flow control이 있다 (13.1절에서 설명).
채널 대역폭과 버퍼를 모두 flit 단위로 할당하면, flit-buffer flow control이 된다 (13.2절에서 설명).
버퍼를 flit 단위로 할당하면 세 가지 주요 장점이 있다.
- 라우터의 동작에 필요한 저장 공간이 줄어든다.
- 혼잡한 지점에서 발생하는 backpressure가 출발지로 더 빠르게 전달된다.
- 저장 공간을 더 효율적으로 사용할 수 있다.
그림 13.1에서 비대각선(off-diagonal) 조합은 일반적이지 않다.
예를 들어 채널을 패킷 단위로 할당하고, 버퍼를 flit 단위로 할당하는 경우는 동작하지 않는다.
전체 패킷을 전송하려면 그것을 수용할 수 있는 충분한 버퍼 공간이 필요하기 때문이다.
반대로, 버퍼를 패킷 단위로 할당하고 채널 대역폭을 flit 단위로 할당하는 조합은 가능하지만 드물다.
Exercise 13.1에서 이 방식을 더 자세히 다룬다.
13.1 Packet-Buffer Flow Control
라우팅 노드에 버퍼를 추가하면 채널 대역폭을 더 효율적으로 활용할 수 있다.
버퍼에 flit이나 packet을 저장하면, 입력 채널과 출력 채널 간의 자원 할당을 분리할 수 있다.
예를 들어 flit이 i 사이클에 입력 채널을 통해 전송되어 버퍼에 저장되었다면, 이후 j 사이클 동안 기다렸다가 i + j 사이클에 출력 채널이 할당되면 전송이 이루어진다.
버퍼가 없다면 flit은 i+1 사이클에 전송되거나 폐기되거나 잘못된 경로로 가야 한다.
버퍼를 추가하면 폐기나 misrouting으로 인한 채널 대역폭 낭비를 방지할 수 있으며, 회로 교환(circuit switching)에서의 유휴 시간도 제거할 수 있다.
따라서 buffered flow control을 통해 거의 100%에 가까운 채널 활용도를 달성할 수 있다.
버퍼와 채널 대역폭은 flit 또는 packet 단위로 할당할 수 있다.
먼저, 두 자원을 모두 packet 단위로 할당하는 store-and-forward 및 cut-through 플로우 제어 방식부터 살펴보자.
Store-and-Forward Flow Control
이 방식은 각 노드에서 패킷을 완전히 수신한 후에 다음 노드로 전달하는 구조다.
패킷을 전달하려면 두 가지 자원이 필요하다:
- 채널 반대편 노드에 packet 크기의 버퍼
- 해당 채널의 독점적인 사용
패킷이 도착하고 이 두 자원이 확보되면 다음 노드로 전달된다.
자원이 아직 준비되지 않았더라도, 채널은 유휴 상태가 아니며 현재 노드의 버퍼 한 개만 점유한다.

Figure 13.2는 5-flit 패킷이 충돌 없이 4-hop 경로를 따라 전달되는 store-and-forward 방식의 time-space diagram이다.
각 단계마다 전체 패킷이 한 채널을 지나고 나서 다음 채널로 전달된다.
이 방식의 주요 단점은 높은 지연(latency)이다.
각 홉마다 전체 패킷이 수신된 후에 다음 홉으로 이동하므로, 홉 수만큼 직렬화 지연(serialization latency)이 누적된다.
따라서 전체 지연 시간은 다음과 같다:

H: 홉 수, tr: 홉당 라우터 지연, L: 패킷 길이(flits), b: 채널 대역폭
Cut-Through Flow Control
cut-through는 store-and-forward의 높은 지연을 줄이기 위한 방식이다.
패킷의 header가 수신되자마자 필요한 자원(버퍼와 채널)을 확보하면 즉시 전송을 시작한다.
패킷 전체가 도착할 때까지 기다리지 않는다.
이 방식도 버퍼와 채널 대역폭을 패킷 단위로 할당하지만, 각 홉마다 가능한 빨리 전송을 시작한다는 점이 다르다.

Figure 13.3(a)는 충돌 없는 경우, Figure 13.3(b)는 채널 2에서 3사이클 동안 충돌이 발생하는 cut-through의 time-space diagram이다.
자원이 곧바로 사용 가능하면 header 수신 즉시 다음 홉으로 전송된다.
충돌 시에는 channel 2가 사용 가능할 때까지 기다리지만, channel 1로의 전송과 버퍼링은 계속된다.
이 방식은 패킷이 가능한 빨리 전송되므로, 전체 지연이 아래와 같이 줄어든다:

cut-through는 높은 채널 활용도와 낮은 지연을 제공하지만, 두 가지 단점이 있다.
- 버퍼를 패킷 단위로 할당하기 때문에 저장 공간의 효율성이 낮다.
특히 deadlock 회피나 블로킹 방지를 위해 다수의 독립적인 버퍼 세트가 필요한 경우 비효율적이다. - 채널을 패킷 단위로 할당하므로 충돌 지연(contention latency)이 증가한다.
예를 들어, 낮은 우선순위의 패킷이 먼저 채널을 점유하면, 높은 우선순위 패킷은 전체 패킷이 끝날 때까지 기다려야 한다.
다음 절에서는 자원을 packet이 아닌 flit 단위로 할당함으로써 버퍼를 더 효율적으로 사용하고 충돌 지연을 줄이는 방식을 다룬다.
13.2 Flit-Buffer Flow Control
13.2.1 Wormhole Flow Control
Wormhole flow control은 cut-through 방식과 유사하게 작동하지만, 자원을 packet이 아니라 flit 단위로 할당한다.
패킷의 head flit이 노드에 도착하면 다음 노드로 전달되기 전에 세 가지 자원을 확보해야 한다:
- 해당 패킷을 위한 virtual channel (채널 상태)
- 하나의 flit buffer
- 하나의 채널 대역폭(flits worth)
패킷의 body flit은 이미 head flit이 할당한 virtual channel을 공유하며, flit buffer 하나와 채널 대역폭만을 추가로 확보하면 된다.
tail flit은 body flit과 동일하게 처리되지만, 전달되면서 virtual channel을 해제한다.
Virtual channel은 채널 상에서 패킷의 flit들을 처리하기 위한 상태 정보를 담고 있다.
최소한으로, 이 상태는 현재 노드의 출력 채널과 virtual channel의 상태(idle, waiting, active)를 포함한다.
추가적으로, 현재 노드에 버퍼된 flit들의 포인터나 다음 노드의 가용 flit buffer 수를 포함할 수도 있다.

Figure 13.4는 wormhole flow control을 이용해 하나의 노드를 통과하는 4-flit 패킷의 예를 보여준다.
그림 (a)~(g)는 사이클별 전달 과정을, (h)는 이를 요약한 time-space diagram이다.
- (a): 입력 virtual channel은 idle 상태이며, head flit이 도착한다. 원하는 upper 출력 채널은 busy 상태(L 입력에 할당됨).
- (b): head flit이 버퍼에 저장되고 virtual channel은 waiting 상태로 전환된다. 첫 번째 body flit이 도착.
- (c): head와 body flit이 버퍼에 저장되며, waiting 상태는 두 사이클 지속된다. flit buffer가 없어 두 번째 body flit은 입력 채널에서 멈춤.
- (d): 출력 채널이 사용 가능해지며 virtual channel이 active 상태로 전환되고, head flit이 전송된다.
- (e), (f): 나머지 body flit들이 순차적으로 전송됨.
- (g): tail flit이 전송되며 virtual channel은 idle 상태로 되돌아간다.
cut-through flow control과 비교하면, wormhole flow control은 훨씬 적은 수의 flit buffer만 필요로 하여 버퍼 공간의 효율성이 뛰어나다.
반면, cut-through는 여러 패킷 크기만큼의 버퍼 공간이 필요하며, 이는 wormhole보다 최소 한 자릿수 이상 큰 저장 공간을 요구한다.
하지만 이러한 버퍼 절약은 throughput의 일부 손실을 대가로 한다. wormhole은 패킷 중간에서 채널이 block될 수 있기 때문이다.
13.2.2 Virtual-Channel Flow Control
Virtual-channel flow control은 하나의 물리 채널에 여러 개의 virtual channels (channel state 및 flit buffer 포함)을 할당함으로써 wormhole flow control의 blocking 문제를 해결한다.
wormhole과 유사하게, head flit은 virtual channel, downstream flit buffer, 그리고 채널 대역폭을 할당받아야 한다.
body flit은 head flit이 확보한 virtual channel을 사용하지만, 여전히 buffer와 대역폭 확보가 필요하다.
그러나 wormhole과 달리, 이들은 대역폭 사용이 보장되지 않으며, 다른 virtual channel과의 경쟁이 발생할 수 있다.
virtual channel을 사용하면 blocking된 패킷을 다른 패킷이 우회할 수 있으므로, otherwise idle 상태인 채널 대역폭을 활용할 수 있다.

Figure 13.5는 2D torus 네트워크에서 패킷 A와 B가 충돌하는 상황을 보여준다.
- (a): wormhole flow control에서는 각 물리 채널당 하나의 virtual channel만 사용된다.
패킷 B는 채널 p를 확보한 채 blocking되고, 패킷 A는 p를 할당받지 못해 channel p와 q가 비어 있음에도 진행 불가. - (b): virtual-channel flow control을 적용해 각 물리 채널당 두 개의 virtual channel을 제공하면, 패킷 A는 node 2에서 두 번째 virtual channel을 확보해 channel p와 q를 사용하며 진행 가능.
이 상황은 다음과 같이 비유할 수 있다.
패킷 B는 막힌 사거리에서 좌회전을 기다리는 차량이고, 패킷 A는 뒤따르는 차량이다.
차로가 하나뿐이라면 A는 진행할 수 없지만, 좌회전 전용 차선을 추가하면 A는 B를 피해 직진할 수 있다.
이는 virtual channel이 물리적 채널의 대역폭을 증가시키지 않음에도 불구하고, 사용률을 높일 수 있음을 보여준다.
virtual channel flow control은 channel state의 할당을 채널 대역폭의 사용으로부터 분리(decouple)시킨다.
이 분리를 통해, 대역폭이 할당되어 있지 않더라도 채널 state만 가지고 있는 패킷에 의해 채널이 유휴 상태로 머무는 일이 방지된다.
결과적으로 wormhole보다 더 높은 throughput을 제공할 수 있으며, 동일한 총 버퍼 용량이 주어진 상황에서도, cut-through보다 우수한 성능을 보인다.
이는 여러 개의 짧은 flit buffer를 가진 virtual channel이 하나의 큰 packet buffer를 사용하는 cut-through보다 자원 사용 측면에서 더 효율적이기 때문이다.

Figure 13.6에서는 두 개의 virtual channel이 하나의 물리 채널을 공유하는 상황을 보여준다.
패킷 A와 B가 입력 1번과 2번을 통해 도착하고, 둘 다 동일한 출력 채널의 virtual channel을 확보한다.
두 패킷의 flit은 출력 채널에서 번갈아가며(interleaved) 전송되며, 각각 절반씩의 flit 주기를 사용한다.
패킷들이 입력에서는 full rate로 도착하지만 출력에서는 half rate로 나가므로, flit buffer는 포화되고 입력도 half rate로 제한된다.
입력에서의 간격(gap)은 물리 채널이 유휴 상태라는 뜻은 아니며, 다른 virtual channel이 이 시간대를 사용할 수 있다.
Figure 13.6은 두 개의 virtual channel이 하나의 물리 채널에서 flit을 교차 전송(interleave)하는 과정을 보여준다.
패킷 A는 입력 1번, 패킷 B는 입력 2번으로 동시에 도착하여 동일한 출력 채널을 요청한다.
두 패킷은 해당 출력 채널에 연결된 각자의 virtual channel을 확보하지만, flit 단위로 대역폭을 경쟁하며 사용해야 한다.
공정한 대역폭 분배가 이루어지면 두 패킷의 flit이 교대로 전송된다.
도착하는 flit 아래의 숫자는 각 virtual channel의 입력 버퍼에 저장된 flit 수를 나타내며, 버퍼 용량은 3 flit이다.
입력 버퍼가 가득 차면, 새로운 flit은 이전 flit이 나갈 때까지 차단된다.
출력 링크에서는 각 패킷의 flit이 격주기(every other cycle)로만 전송 가능하다.

Figure 13.7은 병목 링크(p)의 대역폭을 두 개의 virtual channel이 공유할 때 upstream과 downstream의 대역폭이 모두 절반으로 줄어드는 상황을 보여준다.
패킷 A(회색)와 B(검정)는 병목 링크 p에서 각각 50%의 대역폭만 사용한다.
병목 이후 downstream 링크에서는 이들 패킷이 최대 50%의 대역폭만 사용할 수 있으며,
병목 이전의 upstream에서도 node 1의 virtual channel 버퍼가 가득 차면 전송이 격주기로 제한되어 upstream 대역폭 역시 절반으로 줄어든다.
다른 virtual channel을 사용하는 패킷들은 이로 인해 남는 대역폭을 활용할 수 있다.
이러한 현상은 패킷의 길이가 길어질수록 source까지 blocking 현상이 전파될 수 있음을 의미한다.
한편, downstream에서도 사용되지 않는 idle 주기는 다른 패킷이 사용할 수 있다.
공정한 대역폭 할당 방식은 competing 패킷의 flit을 교차 전송하게 만들어 평균 latency를 증가시킨다.
반면, winner-take-all 방식은 하나의 패킷이 전송을 끝내거나 차단(blocked)될 때까지 모든 대역폭을 독점한 후, 다음 패킷으로 넘어가는 방식이다(Figure 13.8).

두 방식 모두 contention latency 총량은 같지만, winner-take-all 방식에서는 하나의 패킷이 지연 없이 빠르게 전송을 완료할 수 있다.
만약 먼저 전송되던 패킷이 도중에 block되면 채널은 즉시 다른 패킷에게 양도된다.
이처럼 공정하지 않은 대역폭 중재는 virtual-channel flow control에서 throughput 손실 없이 평균 latency를 줄일 수 있다.

Figure 13.9는 virtual channel을 구현하기 위해 복제되는 상태 정보를 나타낸 block diagram이다.
이 예시는 입력 포트 2개, 출력 포트 2개, 각 물리 채널당 2개의 virtual channel을 가진 라우터를 보여준다.
각 입력 virtual channel은 다음의 정보를 포함한다:
- channel status (idle, waiting, active)
- 현재 패킷에 할당된 출력 virtual channel 식별자
- flit buffer
각 출력 virtual channel은 할당 여부와 연결된 입력 virtual channel을 기록하는 상태 레지스터 하나만 가진다.
그림에는 다음 상태가 나타나 있다:
- 입력 virtual channel 1, 2: active 상태로, 상단 출력 virtual channel 1, 2로 패킷을 전송 중
- 입력 virtual channel 3: 출력 virtual channel을 기다리는 waiting 상태
- 입력 virtual channel 4: 아직 패킷이 도착하지 않은 idle 상태
virtual-channel flow control은 buffer를 2차원(virtual channels × flits per VC) 으로 구성한다.
입력당 고정된 수의 flit buffer가 있을 경우, 이를 어떻게 나눌지 선택할 수 있다.
예를 들어 입력당 16 flit의 저장 공간이 있으면, 다음과 같은 구성이 가능하다(Figure 13.10 참조):
- 하나의 virtual channel에 16-flit buffer
- 8-flit buffer를 가진 두 개의 virtual channel
- 4-flit buffer를 가진 네 개의 virtual channel
- 2-flit buffer를 가진 여덟 개의 virtual channel
- 1-flit buffer를 가진 열여섯 개의 virtual channel

일반적으로, virtual channel에 필요한 flit 수는 round-trip credit latency를 커버할 정도면 충분하며, 그 이상으로 깊게 만드는 것은 큰 성능 향상을 제공하지 않는다.
따라서, buffer 자원을 늘릴 때는 각 virtual channel의 flit 수를 늘리기보다는 virtual channel 수를 늘리는 것이 보통 더 효과적이다.
Virtual channel은 interconnection network의 다용도 도구(Swiss-Army™ Knife)와 같다.
block된 패킷을 우회시키는 데 사용될 수 있고(성능 향상), 다음 장에서는 deadlock 회피에도 활용된다.
네트워크 자체의 deadlock뿐 아니라 상위 계층 프로토콜 간의 종속성으로 인한 deadlock에도 대응 가능하다.
또한 virtual channel을 분리하여 서로 다른 priority traffic class에 대해 차등 서비스를 제공하거나, 목적지별로 트래픽을 분리함으로써 네트워크의 non-interfering 특성을 구현할 수도 있다.
13.3 Buffer Management and Backpressure
버퍼를 사용하는 모든 flow control 방식은 downstream 노드에 버퍼의 가용 여부를 알리는 수단이 필요하다.
그래야 upstream 노드는 다음 flit(또는 store-and-forward 및 cut-through 방식의 경우는 packet)을 보낼 때 버퍼가 비어 있는지를 알 수 있다.
이러한 버퍼 관리 방식은 downstream의 flit buffer가 가득 찼을 때 upstream 노드에게 전송을 중단하라는 backpressure를 제공한다.
현재 이러한 backpressure를 제공하기 위해 일반적으로 사용되는 저수준 flow control 방식은 다음 세 가지이다:
- Credit-based
- On/off
- Ack/nack
각 방식을 차례로 살펴보자.
13.3.1 Credit-Based Flow Control
Credit-based flow control에서는 upstream 라우터가 downstream의 각 virtual channel에 존재하는 가용 flit buffer의 수를 세어 유지한다.
upstream 라우터가 flit을 전송하여 downstream buffer를 하나 사용하면, 해당 카운터를 감소시킨다.
이 카운트가 0이 되면 downstream buffer가 모두 가득 찼음을 의미하며, 새로운 flit은 buffer가 해제될 때까지 전송할 수 없다.
downstream 라우터가 flit을 전송하고 buffer를 해제하면, 해당 정보를 담은 credit을 upstream 라우터로 보내고, 이로 인해 카운터가 다시 증가한다.
Figure 13.11은 credit-based flow control의 타임라인을 보여준다.

시간 t1 직전, 채널의 downstream 끝 (node 2)의 모든 buffer는 가득 차 있다.
t1에서 node 2가 flit 하나를 전송하고, buffer 하나를 비우며 credit을 node 1로 보낸다.
credit은 t2에 도착하고, 짧은 처리 후 t3에서 flit이 전송되며, t4에 도착한다.
이어 t5에서 flit이 node 2에서 나가 buffer가 다시 비워지고, 새로운 credit이 다시 node 1로 보내진다.
t1에서 credit이 보내지고, t5에서 같은 buffer에 대한 credit이 다시 보내지기까지의 최소 시간이 credit round-trip delay (tcrt) 이다.
이는 wire delay와 양쪽 노드에서의 처리 시간을 포함하며, router의 성능에서 매우 중요한 매개변수이다.
만약 virtual channel에 단 하나의 flit buffer만 있다면, 매 flit 전송 전에 해당 buffer에 대한 credit을 기다려야 하므로, 최대 전송률은 tcrt당 1 flit이 된다.
즉, bit rate는 Lf / tcrt가 된다.
buffer 수가 F개라면, credit을 기다리기 전까지 F개의 flit을 보낼 수 있으므로, 전송률은 F flits per tcrt, 즉 F × Lf / tcrt 비트/초가 된다.
따라서, flow control이 채널 대역폭 b를 제한하지 않으려면 다음 조건이 필요하다:

Figure 13.12는 credit-based flow control의 동작을 flit 단위로 시각화한 것이다.
- (a): node 1은 node 2의 virtual channel에 대해 2개의 credit을 가지고 있다.
- (b): node 1은 head flit을 전송하고 credit 수는 1로 감소한다.
- (c): head flit이 node 2에 도착하고, 동시에 body flit이 전송되며 credit 수는 0이 된다.
- (d): node 1은 credit이 없기 때문에 flit을 더 이상 전송할 수 없다.
- (e): node 2는 head flit을 전송하여 buffer를 비우고, credit을 node 1에 보낸다.
- (f): credit이 도착하여 node 1의 credit 수가 증가하고, tail flit이 전송된다.
- (g): tail flit은 node 2로 전송되고 virtual channel이 해제된다.
- (h): tail flit이 node 2에서 전송되며, 마지막 credit이 node 1로 돌아온다.
- (i): 결과적으로 node 1은 다시 2개의 credit을 갖게 된다.
단점: 이 방식은 flit당 하나의 credit이 필요하므로, upstream으로의 신호량이 많아질 수 있으며, 특히 flit이 작을 경우 신호 오버헤드가 커진다.

13.3.2 On/Off Flow Control
On/off flow control은 경우에 따라 upstream 신호량을 크게 줄일 수 있다.
이 방식에서는 upstream 상태가 단일 제어 비트로 표현된다:
- on일 때: 전송 허용
- off 때: 전송 금지
이 상태가 바뀔 때만 신호가 전송된다.
예를 들어, control bit가 on인 상태에서 가용 buffer 수가 Foff 이하로 떨어지면 off 신호가 전송된다.
반대로 control bit가 off인 상태에서 가용 buffer 수가 Fon 이상으로 회복되면 on 신호가 전송된다.

Figure 13.13은 on/off flow control의 타임라인을 보여준다.
- t1: node 1이 flit을 전송하며, node 2의 가용 buffer 수가 Foff 미만이 된다. 이에 따라 node 2는 off 신호를 전송한다.
- off 신호가 도착하기 전까지, node 1은 계속 flit을 전송한다. 이 flit들은 off 신호가 전송되던 시점에 비어 있었던 Foff 개의 buffer에 저장된다.
- t6: node 2의 가용 buffer 수가 Fon 이상으로 증가하자 on 신호를 node 1로 보낸다.
- on 신호가 전송된 t6부터 node 1의 다음 flit이 도착하는 t9 사이 동안, node 2는 F − Fon개의 buffer에 저장된 flit을 전송한다.
Figure 13.13에서, flit이 t1에서 전송되며 node 2의 가용 버퍼 수가 Foff 미만으로 떨어지고, t2에서 off 신호가 전송된다.
이 신호는 t3에 node 1에 도착하며, 짧은 처리 시간 후 t4에서 flit 전송을 중단하게 한다.
t1과 t4 사이의 시간인 trt 동안 추가로 flit이 전송된다. 이 추가 flit이 buffer overflow를 일으키지 않도록 하려면 다음 조건을 만족해야 한다:
Foff ≥ trt × b / Lf (식 13.2)
그 후 node 2는 flit들을 전송하며 buffer를 해제하고, 가용 버퍼 수가 Fon을 초과하면 t6에서 on 신호를 전송한다.
이 on 신호는 t7에서 node 1에 도달하고, node 1은 t8에서 flit 전송을 재개한다.
이 on 신호로 인해 트리거된 첫 번째 flit은 t9에 도착한다.
이전과 마찬가지로, t6에서 t9 사이 동안 node 2가 전송할 flit이 부족해지지 않으려면 다음 조건이 필요하다:
F − Fon ≥ trt × b / Lf (식 13.3)
정리하면, on/off flow control이 제대로 동작하려면 최소한 다음 조건을 만족해야 한다:
F ≥ 2 × trt × b / Lf
즉, 동작 자체를 위해서는 식 13.2가, full speed를 위해서는 식 13.3까지 만족해야 하며, 결과적으로 충분한 buffer 수가 확보되어야 upstream 신호량을 최소화할 수 있다.
13.3.3 Ack/Nack Flow Control
Ack/nack flow control은 credit-based 및 on/off 방식과 달리, buffer가 비워지는 순간부터 flit이 도착하는 시점까지의 지연을 최소한 0으로 줄일 수 있다.
평균적으로 buffer가 비워져 있는 시간은 trt / 2가 된다. 하지만 net 성능 향상은 없다.
flit 전송 후 ack을 기다리는 동안 buffer를 점유하므로 buffer 효율은 credit 방식보다 낮다.
또한, buffer가 없을 경우 flit을 폐기해야 하므로 bandwidth 효율도 떨어진다.
이 방식에서는 upstream 노드가 buffer 가용 상태를 유지하지 않는다.
대신, flit이 준비되면 낙관적으로(optimistically) downstream으로 전송한다.
- buffer가 있을 경우 → flit 수신 및 ack 전송
- buffer가 없을 경우 → flit 폐기 및 nack 전송
upstream 노드는 각 flit을 ack가 도착할 때까지 보관한다.
nack이 도착하면 해당 flit을 재전송한다.
여러 개의 flit이 동시에 전송되는 시스템에서는 flit과 ack/nack 간의 대응을 순서(ordering)로 유지한다.
하지만 nack이 발생하면 flit이 순서대로 도착하지 않을 수 있으므로, downstream 노드는 재전송된 flit이 도착할 때까지 이후 flit들을 임시 보관해야 한다.

Figure 13.14는 ack/nack flow control의 타임라인이다:
- t1: node 1이 flit 1을 보냄 → node 2는 buffer가 없어 flit 1을 폐기하고 nack 전송
- t2: flit 2가 전송됨
- t3: node 1이 nack을 수신하지만 flit 3을 이미 전송 중
- t4: flit 3 전송 완료 후 flit 1 재전송
- t5: flit 1 수신 → node 2는 순서를 유지하기 위해 flit 2와 3을 보관한 뒤 flit 1 수신 후 전송함
이 방식은 buffer와 bandwidth 사용 측면에서 매우 비효율적이기 때문에, 실제로는 거의 사용되지 않는다.
소규모 buffer 시스템에는 credit 방식, 대규모 buffer 시스템에는 on/off 방식이 보통 사용된다.
13.4 Flit-Reservation Flow Control
기존 wormhole 네트워크는 패킷 지연(latency)을 줄이는 데 효과적이지만, 이상적인 router 동작과 실제 pipeline 하드웨어 구현 간에는 차이가 있다.
Pipeline 구조에서는 flit 전송 단계가 여러 단계로 나뉘므로 hop 시간이 증가하고, 이로 인해 buffer 사용률도 영향을 받는다.

Figure 13.15는 credit-based wormhole flow control에서의 buffer 사용 예시이다:
- flit이 현재 노드에서 다음 노드로 전송됨
- 해당 buffer는 다음 hop으로 전송되기 전까지 점유됨
- 이후 credit이 반대 방향으로 전송되고, wire propagation 시간 Tw,credit 소요됨
- credit이 도착하면 pipeline delay 후 buffer 재사용 가능
- 다음 flit은 credit을 받은 후 flit pipeline을 거쳐 다시 전송됨
- flit은 다음 채널을 통해 Tw,data 시간 동안 전송되며 buffer에 저장됨
🧩 주요 타임라인 해석
1. Tw,data
- flit이 전송되어 다음 node에 도달하는 데 걸리는 wire propagation delay
- physical channel을 통해 flit이 전달되며, 이 기간 동안 buffer는 다음 node에 점유됨
2. Credit sent → Tw,credit → Credit received
- 다음 node에서 flit이 전송되고 나면, 해당 buffer가 비워짐
- 이 정보는 credit 신호로 원래 node로 전달됨
- 이 credit이 도달하는 데 걸리는 시간 = Tw,credit
3. Credit pipeline delay
- credit을 받아도 바로 사용할 수 있는 게 아니라, 라우터 내부 처리 지연 발생
- 이후 buffer는 다음 flit을 위해 다시 할당 가능
4. Flit pipeline delay
- credit을 받은 다음 flit도 바로 채널에 나갈 수 있는 게 아님
- flit pipeline을 통과해야 채널에 도달 가능
이러한 일련의 과정에서 buffer가 실제로 사용되는 시간은 전체의 일부에 불과하다.
남은 시간은 turnaround time이며, buffer가 실제로 활용되지 않는 시간이다.
turnaround time이 클수록 network throughput은 줄어든다.
Flit-reservation flow control은 turnaround time을 0으로 줄이고 flit pipeline 지연을 숨김으로써 throughput을 향상시킬 수 있다.
Flit-reservation 방식에서는 router의 제어 네트워크와 데이터 네트워크를 분리하여 pipeline 구현의 overhead를 숨긴다.
Control flit은 data flit보다 앞서 전송되며, 네트워크 자원을 미리 예약한다.
data flit이 도착할 때에는 이미 virtual channel 등의 자원이 예약되어 있어 지연 없이 전송이 가능하다.
이는 credit의 전달을 간소화하며, buffer의 turnaround time을 제거할 수 있다.
단, 혼잡 상태에서는 사전 예약이 불가능하므로, 이때는 일반 wormhole처럼 data flit이 자원이 예약될 때까지 대기한다.

Figure 13.16은 flit-reservation packet 구조를 보여준다:
- Control head flit에는 VC, type, routing 정보와 함께 td0라는 data offset 필드가 있다.
- 예: control flit이 t=3에 도착하고 td0=2이면, data flit은 t=5에 도착할 것으로 router는 예측 가능하다.
- 이를 통해 router는 data flit 도착 전에 자원을 예약할 수 있다.
- data flit에는 별도의 제어 필드가 필요 없다.
데이터 flit이 여러 개인 경우, 추가적인 control body flit이 head 뒤에 따라오며 각각의 data flit에 대응하는 offset 필드를 포함한다.
13.4.1 A Flit-Reservation Router
Figure 13.17은 flit-reservation router의 전체 구조를 보여준다.

그림에서는 간단히 하기 위해 단일 입력과 단일 출력만 표시되어 있으며, 입력과 출력 구조는 점선으로 분리되어 있다.
control flit이 라우터에 도착하면 routing logic으로 전달된다.
control head flit이 도착하면, 이 flit의 출력 virtual channel(다음 홉)이 계산되어 해당 입력 virtual channel과 연결된다.
이후 도착하는 control body flit들도 같은 출력 채널로 표시된다.
control flit이 출력 포트에 도달하면 output scheduler로 전달된다.
output scheduler는 control flit에 포함된 data offset 정보를 참조하여, 각 data flit의 buffer 공간을 다음 홉 라우터에서 예약한다.
다음 홉 라우터의 buffer 상태는 output reservation table에 저장되며, credit을 통해 지속적으로 업데이트된다.
모든 data flit의 예약이 완료되면 control flit은 다음 홉으로 전달된다.
control flit과 해당 data flit들을 라우터 내부에서 연결해주는 역할은 input reservation table이 담당한다.
control flit이 routing logic을 통과하면서 목적지 정보가 input reservation table에 기록된다.
각 data offset 값도 여기에 저장되며, output scheduler에서 예약이 완료되면 해당 정보가 다시 input scheduler에 전달된다.
input scheduler는 어떤 사이클에 buffer가 비워질지를 알고 있으므로, 그에 맞춰 flit을 전송할 수 있다.
13.4.2 Output Scheduling
output scheduler는 각 data flit의 미래 전송 시점을 결정한다.
data flit이 전송되기 위해서는 두 가지 조건을 충족해야 한다:
- 물리적 출력 채널 예약
- 다음 라우터에 충분한 buffer 공간 확보
이를 위해 output scheduler는 output reservation table을 관리하며, 앞으로 몇 사이클에 걸쳐 채널 사용 상태와 buffer 가용성을 추적한다.

Figure 13.18(a)는 output reservation table의 예시 상태다.
예를 들어, control flit이 t=0에 도착했고 data offset(td0)은 9라고 하자.
이는 data flit이 cycle 9에 도착함을 의미한다. 해당 정보는 output scheduler와 input reservation table로 전달된다.
output scheduler는 가능한 전송 시점을 찾는다:
- cycle 10은 채널이 이미 사용 중이므로 제외
- cycle 11은 buffer가 부족하므로 제외
- cycle 12가 최초의 유효한 전송 시점 → 예약 확정
따라서 output reservation table은 cycle 12의 채널 상태를 busy로 표시하고, 이후 cycle부터 buffer 수를 감소시킨다(Figure 13.18(b)).
추후 credit이 도착하면 buffer 수는 다시 복원된다.
control flit이 예약을 마치고 다음 홉으로 이동할 때, data flit의 상대적 전송 시간이 변경될 수 있다.
따라서 data offset(td0) 값을 업데이트해야 한다.
예를 들어 control flit이 다음 router에 t=2에 도착하고, data flit의 전송 시점이 cycle 12라면:
td0 = 12 − 2 = 10
13.4.3 Input Scheduling
input scheduler와 input reservation table은 flit-reservation 라우터 내에서 data flit의 흐름을 관리한다.
control flit이 도착하면, 해당 data offset 정보를 통해 routing logic이 data flit의 도착 시간과 목적지 포트를 input reservation table에 기록한다(Figure 13.19 참조).

output scheduler가 data flit의 전송 시점을 결정하면, 이 정보는 input scheduler로 전달되고, input reservation table이 갱신된다.
또한 해당 정보는 credit 형태로 이전 노드에 전송되어 buffer 재사용 가능 시점을 알린다.
앞서 예시한 cycle 9에 도착하는 data flit은 cycle 10 초에 latching되어 기록된다.
cycle 12에 전송될 예정이므로 이 departure 시간도 table에 기록되며, 해당 포트 방향(East 등)도 함께 저장된다.
buffer 자체는 data flit이 도착하기 한 사이클 전에서야 실제로 할당되며, 이때 buffer in / buffer out 필드가 완성된다.
13.5 참고 문헌
- Cut-through flow control은 Kermani와 Kleinrock이 도입
- Wormhole flow control은 Dally와 Seitz에 의해 제안되어 Torus Routing Chip에서 처음 구현됨
- Virtual-channel flow control은 Dally가 refinement하여 제안
- 실제 적용 예시: Cray T3D, T3E, SGI Spider, IBM SP 네트워크
- Flit-reservation flow control은 Peh와 Dally가 개발함
13.6 연습문제
13.1 패킷 기반 buffer 할당 + flit 기반 채널 대역폭 할당의 장단점을 분석하고, cut-through와 다른 시간-공간 순서를 갖는 예제를 작성하라.
13.2 credit-based flow control의 overhead를 계산하라.
(조건: 패킷 길이 L, flit 크기 Lf, virtual channel 수 V)
13.3 입력 간 공유되는 buffer pool이 있는 라우터에서의 flow control 설계를 설명하라.
공정성을 위한 static + dynamic 할당 방식, signaling overhead 여부 포함.
13.4 입력 buffer pool이 single-ported인 flit-reservation router의 구조 수정 방안을 설명하고, 필요한 상태 정보가 있는지 기술하라.
13.5 flit-reservation에서의 동기화 문제: plesiochronous 시스템에서 발생할 수 있는 주기 삽입에 의한 제어/data misalignment 문제를 간단한 방법으로 해결하라.
'System-on-Chip Design > NoC' 카테고리의 다른 글
| Quality of Service (1) | 2025.06.05 |
|---|---|
| Deadlock and Livelock (2) | 2025.06.05 |
| Flow Control Basics (2) | 2025.06.02 |
| Routing Mechanics (2) | 2025.06.02 |
| Adaptive Routing (1) | 2025.06.02 |