
adaptive routing 알고리즘은 일반적으로 queue 점유율과 같은 네트워크 상태 정보를 이용하여, 패킷을 전달할 때 여러 가능한 경로 중 하나를 선택한다. 네트워크 상태에 따라 라우팅이 결정되므로, adaptive routing 알고리즘은 flow control 메커니즘과 밀접하게 연결된다. 이는 routing 알고리즘과 flow control이 대부분 독립적인 deterministic 및 oblivious routing과는 대조적이다.
이론적으로 좋은 adaptive routing 알고리즘은, 네트워크 상태 정보를 활용하지 못하는 oblivious routing보다 더 나은 성능을 보여야 한다. 그러나 실제로 많은 adaptive routing 알고리즘은 최악의 경우 성능이 나쁜 경우가 많다. 이는 대부분의 실용적인 adaptive routing 알고리즘이 local 정보를 사용하기 때문이다. 이러한 알고리즘은 local queue length와 같은 지역적인 네트워크 상태만을 참고하여 라우팅 결정을 내리기 때문에, 지역적인 부하 균형은 맞춰도 전체적으로는 부하가 불균형하게 되는 경우가 생긴다.
adaptive routing의 지역성은 트래픽 패턴 변화에 늦게 반응하는 문제도 일으킨다. 혼잡 지점보다 앞선 라우팅 지점의 queue가 가득 차야만 혼잡을 감지할 수 있기 때문이다. 따라서 adaptive routing에는 backpressure가 강하게 전달되는 flow control 방식(예: shallow queue 사용)이 바람직하다. 그래야 멀리 있는 혼잡에도 더 빨리 적응할 수 있다.
10.1 Adaptive Routing 기본
adaptive routing에 관련된 다양한 이슈는 간단한 8-node ring을 통해 설명할 수 있다. Figure 10.1에서는 노드 5가 노드 6으로 패킷을 지속적으로 전송하며, (5,6) 채널의 모든 대역폭을 사용 중이다.

동시에 노드 3은 노드 7로 패킷을 보내고자 한다. 이때 노드 3은 그림의 실선 화살표로 표시된 시계방향 경로와 점선 화살표로 표시된 반시계 방향 경로 중 선택할 수 있다.
전체 네트워크 상태를 실시간으로 알고 있는 독자는, 노드 3이 (5,6) 채널의 혼잡을 피하기 위해 반시계 방향을 선택해야 한다는 것을 쉽게 알 수 있다. 하지만 노드 3의 라우터는 (5,6) 채널에서 발생하는 혼잡을 알 수 없다. 이 혼잡은 노드 5의 queue에는 영향을 주지만, 다른 트래픽이 없다면 노드 3의 queue에는 영향을 주지 않는다.
adaptive routing 알고리즘이 네트워크 상태를 어떻게 감지하는지가 핵심이다. 이 질문은 공간과 시간이라는 관점으로 나눠볼 수 있다: 알고리즘이 local 정보를 사용하는가, global 정보를 사용하는가? 현재 정보를 사용하는가, 과거 정보를 사용하는가? 이 질문들은 이진적인 답이 있는 것이 아니라, local과 global 정보, 현재성과 과거성 사이에는 연속적인 스펙트럼이 존재한다.
거의 모든 adaptive router는 flit 기반 혹은 packet 기반 flow control을 사용하며(Chapter 12 참고), 현재 노드의 flit 혹은 packet queue 상태를 통해 local link의 혼잡을 추정한다. 다른 위치의 link 상태에 대한 직접적인 정보는 없다. 따라서 Figure 10.1의 상황처럼 노드 3이 단독 패킷을 노드 7로 보낼 경우, 해당 queue는 (5,6) 채널의 혼잡을 반영하지 않으며, 결국 노드 3은 어느 경로를 선택하든 무작위로 결정할 수밖에 없다.
라우터는 backpressure를 통해 네트워크 다른 위치의 혼잡을 간접적으로 감지할 수 있다. 한 노드의 queue가 가득 차면, 이전 노드로부터의 전송이 중단되며, 이로 인해 그 이전 노드의 queue도 차게 된다. 이 backpressure는 트래픽의 흐름과 반대 방향으로 네트워크를 따라 전파된다. 하지만 backpressure는 혼잡 지점으로 들어오는 트래픽이 있어야만 전파된다. 트래픽이 없다면 backpressure도 없고, 따라서 원거리 혼잡에 대한 정보도 없다.
예를 들어 Figure 10.1의 경우, 노드 4와 5의 입력 queue가 완전히 가득 차야만 노드 3이 (5,6) 채널의 혼잡을 감지할 수 있다.
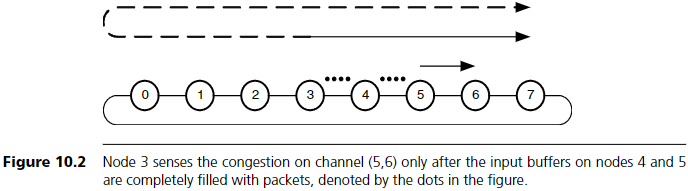
Figure 10.2는 채널 위의 점들이 해당 채널 목적지 노드의 입력 버퍼에 있는 패킷 수를 나타내는 그림이다.
이 예는 adaptive routing이 stiff flow control과 함께 사용할 때 성능이 더 나은 이유를 보여준다. 예를 들어 각 입력 queue가 F = 4개의 패킷만 저장할 수 있다면, 노드 3은 8개의 패킷만 보낸 뒤 혼잡을 감지하고 반대 방향으로 라우팅을 전환한다. 네트워크는 비교적 빠르게 부하가 균형을 이루게 되며, 첫 8개의 패킷만 높은 지연을 겪게 된다. 반면 입력 queue가 F = 64개의 패킷을 저장할 수 있다면, 노드 3이 혼잡을 감지하는 데 16배 더 오래 걸리고, 16배 더 많은 패킷이 혼잡 경로로 인해 높은 지연을 겪는다.
부하 불균형이 경미할 경우, 혼잡 정보가 출발 노드까지 도달하는 데 더 오랜 시간이 걸린다. 예를 들어 어떤 채널이 10%만 초과 부하되었다면, 입력 버퍼 앞에 있는 버퍼가 한 칸 밀리기 위해서는 혼잡 경로로 10개의 패킷이 먼저 지나가야 한다. 이 경우, 출발 노드가 혼잡을 감지하는 데 매우 오랜 시간이 걸리며, 수많은 패킷이 비효율적으로 라우팅될 수 있다.
Figure 10.1의 예는 adaptive routing에서 정보의 현재성(currency) 문제도 보여준다. 예를 들어 노드 3이 (5,6) 채널의 혼잡을 감지하는 시점에, 노드 5→6의 트래픽이 종료되고 대신 노드 1→0의 트래픽이 시작되면, 노드 3은 실시간이 아닌 과거 정보를 바탕으로 (1,0) 채널로 잘못 라우팅할 수 있다. 이 경우 혼잡 채널의 소스 노드까지의 hop 수가 H = 2이고, 입력 버퍼 크기가 F일 때, 노드 3이 (5,6) 채널의 상태를 감지한 시점은 HF 패킷 이전의 상태인 것이다.
ring보다 복잡한 topology에서는 각 단계에서 adaptive routing 결정을 내리게 된다. 그러나 혼잡 정보의 지역성 때문에 여전히 비효율적인 전역 라우팅 경로가 발생할 수 있다.

Figure 10.3은 지역적으로는 좋은 선택이 전체적으로는 나쁜 경로가 되는 사례를 보여준다. 이 경우 패킷은 s = 00에서 d = 23으로 가며, 회색으로 표시된 경로를 따라 이동한다. 초기 hop은 노드 01로 북쪽 방향이고, 여기서 북쪽 link는 약간 혼잡해 보이므로 패킷은 동쪽으로 이동하여 노드 11로 간다. 이후 북쪽의 모든 경로가 매우 혼잡하여 결국 두 개의 매우 혼잡한 link를 지나가야 한다.
노드 01에서 (01,11) 채널을 선택하고 약간 혼잡한 (01,02) 채널을 피하려는 결정은, 이후 경로에서 더 심한 혼잡을 야기할 수 있다.
다른 모든 minimal routing 알고리즘과 마찬가지로, minimal adaptive routing 알고리즘은 source-destination 쌍이 minimal path 다양성(|R<sub>sd</sub>| = 1)을 갖지 않는 경우, 혼잡을 피할 수 없다.

이 상황은 Figure 10.4에서 20에서 23으로 가는 경로에 나타난다. 각 hop에서 단 하나의 productive 방향(+y)만 존재하므로, 패킷은 혼잡한 (21,22) 채널을 피할 수 없다. 아래에서는 non-minimal adaptive routing이 이러한 병목을 어떻게 피하는지 설명한다.
이번 섹션에서 예시로 든 모든 네트워크는 torus였지만, minimal adaptive routing은 어떤 topology에도 적용될 수 있다. 예를 들어, Figure 9.2에 있는 folded Clos에서는 s와 d의 공통 조상 노드까지는 오른쪽으로 adaptive하게 라우팅하고, 그 이후에는 d까지 왼쪽으로 deterministic하게 라우팅하면 된다. 이 경우, 오른쪽으로 가는 구간에서는 모든 출력이 productive하지만, 왼쪽으로 가는 구간에서는 하나의 출력만 productive하다. 이는 실제로 Thinking Machines CM-5의 data network에서 사용된 방식이다 (10.6절 참고).
10.3 Fully Adaptive Routing
non-minimal 또는 fully adaptive routing에서는 패킷이 목적지까지의 최단 경로를 따라가야 한다는 제약이 사라진다. 패킷은 혼잡하거나 고장난 채널을 피하기 위해 일시적으로 목적지로부터 멀어지는 경로로도 전달될 수 있다.
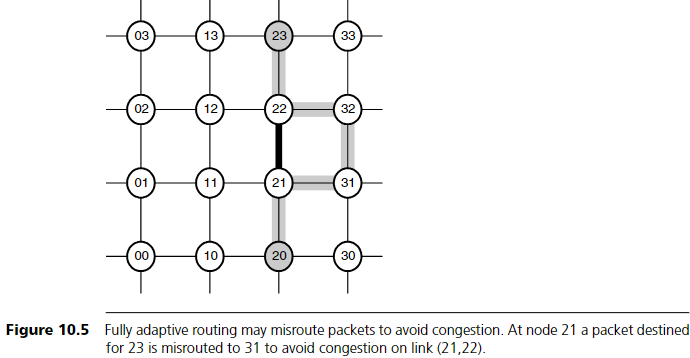
예를 들어, Figure 10.5는 앞의 Figure 10.4에서 20에서 23으로 가는 경로에서 (21,22) 채널의 혼잡을 피하기 위해, 노드 21에서 패킷을 노드 31로 우회시키는 예를 보여준다. 이처럼 목적지로부터 멀어지는 방향의 채널을 따라가는 것을 misrouting이라 한다.
일반적인 fully adaptive routing 알고리즘은 productive output에 우선순위를 둔다. 즉, 혼잡이 없으면 목적지 쪽으로 보내지만, 경로 다양성을 높이기 위해 unproductive output도 허용한다. 한 가지 가능한 알고리즘은 다음과 같다:
- 주어진 패킷에 대해, queue 길이가 임계치보다 짧은 productive output이 있으면, 그중 가장 queue가 짧은 채널로 보낸다.
- 그렇지 않으면, productive 여부와 무관하게 가장 queue가 짧은 채널로 보낸다.
일부 알고리즘은 패킷이 방금 지나온 노드로 되돌아가는 채널을 선택하지 않도록(U-turn 방지) 제한을 두기도 한다. 채널을 오갔다가 되돌아가는 것은 비효율적이라는 가정 때문이다.
fully adaptive routing은 혼잡 회피를 위한 경로 다양성을 제공하지만, livelock이 발생할 수 있다 (14.5절 참고). livelock은 패킷이 네트워크 내에서 무한히 돌아다니다가 목적지에 도달하지 못하는 현상이다. 패킷이 절반 이상을 unproductive 경로로 misrouting하면 livelock이 발생할 수 있다.

Figure 10.6은 이러한 livelock 예시를 보여준다. 노드 00에서 03으로 가는 패킷이 노드 02에서 혼잡을 만나 12로 misrouting되며, 그 후 11로 또 misrouting된다. 이로 인해 11 → 02 → 11을 반복하는 순환이 시작된다.
livelock을 피하기 위해서는, fully adaptive routing 알고리즘이 시간 내에 진전이 보장되도록 어떤 메커니즘을 포함해야 한다. 예를 들어,
- misrouting을 M번까지만 허용한 후 minimal adaptive routing으로 되돌아가도록 하면, 목적지까지 H hops 떨어져 있는 패킷은 최대 H + 2M hops 내에 도달할 수 있다.
- 다른 방식은, H'개의 productive hop마다 한 번의 misrouting을 허용하는 것이다. 이 방식은 H' − 1 거리 단축을 위해 H' + 1 hops를 사용하므로, 전체적으로 패킷은 최대 H × (H'+1)/(H'−1) hops 안에 도달한다.
- chaotic routing(Exercise 10.3)은 전달 hop 수에 상한을 두지 않고, 확률적으로 결국 도달할 것이라는 전제를 사용한다.
fully adaptive routing은 livelock 외에도 deadlock 가능성도 높인다. 이에 대한 논의는 14장에서 다룬다.
10.4 Load-Balanced Adaptive Routing
adaptive routing 알고리즘은 일반적으로 local 정보만 기반으로 라우팅 결정을 내리기 때문에, 네트워크 전체의 부하 균형을 맞추기 어렵다. 이를 해결하기 위한 한 가지 접근은 hybrid routing 알고리즘을 사용하는 것이다.
이 방식은 다음과 같이 구성된다:
- 먼저 9.3절에서 설명한 방법으로, oblivious하게 라우팅할 사분면(quadrant)을 선택한다.
- 이후에는 backtracking 없이 해당 quadrant 내에서 adaptive routing을 사용하여 패킷을 목적지까지 보낸다.
oblivious하게 quadrant를 선택하는 단계는 global load balancing을 수행하고, adaptive routing 단계는 local load balancing을 수행한다.
이 hybrid 방식은 전체 부하 균형이 뛰어나고, 결과적으로 worst-case 성능이 매우 좋다. 다만, local 트래픽 패턴에서는 pure adaptive routing(minimal 또는 fully adaptive)에 비해 성능이 낮을 수 있다. 그 이유는 이 방식도 oblivious routing처럼 일부 패킷을 네트워크를 돌아가게 만들기 때문이다.
비록 이 알고리즘은 minimal하지 않고, 일부 패킷은 멀리 돌아가지만, 패킷은 항상 목적지를 향해 전진하며 livelock은 발생하지 않는다. 일단 라우팅 quadrant가 결정되면, 목적지까지 필요한 hop 수 H가 결정되고, 정확히 H hops 만에 도달하게 된다.
10.5 Search-Based Routing
지금까지 살펴본 라우팅 전략은 모두 greedy하고 conservative한 방식이었다.
- greedy: 한 번 채널을 선택하면 뒤로 물러나지 않는다 (backtrack 없음).
- conservative: 패킷을 하나의 경로로만 보낸다 (여러 경로에 동시에 전송하지 않음).
greedy하지 않은 라우팅 방식의 한 예로, 라우팅 문제를 검색(search) 문제로 보는 방식이 있다. 이 방식은 패킷이 최적 경로를 탐색하게 만든다. 이 때,
- 경로가 막히거나 혼잡하면 backtracking하거나,
- 혹은 여러 경로에 header를 broadcast하고, 그 중 최적의 경로로 data를 전송한다.
이러한 search-based 라우팅 알고리즘은 느리고 리소스를 많이 소모하므로 실제 라우팅에는 거의 사용되지 않는다. 하지만 오프라인에서 라우팅 테이블 생성을 위해 경로를 찾을 때는 유용하다.
10.6 사례 연구: Thinking Machines CM-5의 Adaptive Routing

Figure 10.7은 Thinking Machines의 Connection Machine CM-5 사진을 보여준다. CM-5는 Thinking Machines가 제작한 마지막 connection machine이며, 유일한 MIMD(Multiple Instruction, Multiple Data) 구조의 제품이었다. 초기 CM-1과 CM-2는 bit-serial, SIMD(Single Instruction, Multiple Data) 구조의 병렬 컴퓨터였다.
CM-5는 최대 16K개의 processing node로 구성되어 있으며, 각 노드는 32MHz SPARC 프로세서와 4-way vector unit을 포함한다. 이 시스템은 다음의 세 가지 별도 interconnection network를 포함하고 있었다:
- Data network
- Control network
- Diagnostic network
CM-5는 다양한 관점에서 흥미로운 시스템이며, 영화 『쥬라기 공원』에도 잠깐 등장했다. 그러나 여기서는 data network에 초점을 맞춘다.

Figure 10.8에 나타나듯이, CM-5의 data network는 folded Clos topology를 사용하며, processor와는 duplex connection을 갖는다. switch의 첫 두 단계에는 2:1 concentration이 적용된다. 그림의 각 채널은 양방향에서 20MB/s(40MHz에서 4비트 폭)를 지원한다.
Figure 10.7: CM-5는 최대 16K개의 processing node를 포함하며, 각 노드는 32MHz SPARC 프로세서와 벡터 부동소수점 연산 유닛을 포함한다. 이 노드들은 folded Clos(fat tree) 네트워크로 연결되어 있다.
각 방향에 대해 differential signaling을 사용하며, 각 switch는 1μm CMOS standard-cell 기술로 구현된 단일 칩의 8×8 byte-wide router이다.
Figure 10.8에서 첫 번째 및 두 번째 네트워크 레벨 간의 채널은 backplane을 통해 구현되고, 상위 레벨 채널은 9피트 또는 26피트 길이의 케이블로 구성된다.
각 processing node는 두 개의 독립된 switch에 하나씩 연결되어 있어, 노드당 총 인터페이스 대역폭은 40MB/s이다. 이 duplex 연결 덕분에 네트워크는 단일 고장 지점(single-point fault)에 대해 내성이 있다. 즉, 노드에 연결된 router 하나가 고장나더라도 다른 채널을 통해 계속 메시지를 송수신할 수 있다. 각 프로세서는 memory-mapped interface를 통해 네트워크에 메시지를 주입하며, 메시지는 최대 5개의 32비트 word 데이터를 포함할 수 있다. (후속 버전에서는 최대 18 word까지 허용)
4개의 processing element로 이루어진 그룹에 연결된 두 개의 level-1 switch는 논리적으로 하나의 노드처럼 동작하며, 각각 4개의 다른 level-2 switch에 연결된다. 이와 유사하게, 도식의 4개의 level-2 switch는 각각 8개의 다른 level-3 switch에 연결된다(그중 2개만 그림에 나타남). 이 topology는 level i에 있는 switch가 오직 downstream(왼쪽)으로 메시지를 전송함으로써 4^i 개의 노드에 접근할 수 있도록 구성되어 있다.
CM-5의 메시지 라우팅은 9.2.1절에서 설명한 방식과 유사하되, upstream 라우팅이 oblivious가 아니라 adaptive하다는 점이 다르다. 노드 s에서 노드 d로 가는 메시지는 두 단계로 라우팅된다:
- 메시지는 upstream 방향(오른쪽)으로 공통 조상 switch까지 라우팅되며, 이 단계는 idle한 upstream 링크 중 무작위로 선택되어 adaptive하게 수행된다.
- 공통 조상에 도달하면, 메시지는 목적지 d까지의 고유 경로를 따라 downstream(왼쪽)으로 deterministic하게 라우팅된다. 이때 destination-tag routing을 사용한다.

Figure 10.9는 CM-5 메시지의 형식을 보여준다. 메시지는 4비트 단위의 flit으로 구성되며, 송신 노드가 credit을 가진 동안에는 매 cycle마다 하나의 flit이 4-bit 데이터 채널을 통해 전송된다. 메시지의 첫 번째 flit은 height flit으로, 해당 메시지가 공통 조상에 도달하기 위해 얼마나 upstream(오른쪽)으로 이동해야 하는지를 나타내는 height h 값을 포함한다.
이후에 오는 ⌈h/2⌉ 개의 route flit은 downstream 경로를 구성하며, 각각의 route flit은 두 개의 2-bit route field를 포함한다. 각 field는 downstream 라우팅의 한 단계를 나타낸다. 그 외의 flit은 payload와 관련된 데이터이며 라우팅과는 무관하다.
upstream 라우팅 단계는 메시지 헤더의 height 필드 h로 제어된다. 메시지가 각 router에 들어올 때, h는 해당 router의 레벨 l과 비교된다.
- l < h인 경우, upstream 라우팅은 계속되며, idle한 upstream 링크 중 무작위로 선택된다.
- 모든 링크가 busy이면, 메시지는 block 상태로 남아 idle 링크가 생길 때까지 대기한다.
- l = h인 router에 도달하면, s와 d의 공통 조상에 도달한 것이며 downstream 라우팅 단계가 시작된다.
downstream 단계에서는 각 hop마다 route flit의 route field 하나가 사용되며, 동시에 height h가 감소한다. 이를 통해 다음의 두 가지 효과가 있다:
- head flit 다음에는 항상 ⌈h/2⌉ 개의 route flit이 유지된다.
- h의 최하위 비트(LSB)를 통해 어떤 route field를 사용할지 결정한다.
- h가 짝수일 경우, r의 왼쪽 field를 사용해 downstream 포트를 선택하고, h는 1 감소한다.
- h가 홀수일 경우, r의 오른쪽 field를 사용하고, h를 감소시키며, 이 route flit은 discard된다.
- 다음 hop에서는 h가 다시 짝수이며, 새로운 route flit의 왼쪽 field가 사용된다.
h가 0이 되면 목적지에 도달한 것이고, 모든 라우팅 관련 flit은 소진된 상태가 된다.
CM-5의 upstream 라우팅의 adaptive 특성은 flit-level blocking flow control(13.2절 참고)에 의해 조절된다. channel의 흐름을 제어하기 위해, CM-5는 on/off flow control의 변형을 사용한다 (13.3절 참고). 작동 방식은 다음과 같다:
- 입력 포트 버퍼에 공간이 있으면, 수신 라우터는 송신 라우터에 token을 보낸다.
- 송신자는 이 token을 즉시 사용하여 flit을 보낼 수 있지만, token을 저장(credit처럼 bank)할 수는 없다. flit이 없으면 token은 무효화된다.
- 버퍼가 가득 차면 token이 보내지지 않고, 트래픽이 차단된다.
- CM-5의 각 출력 포트에는 하나의 5-word 메시지를 저장할 수 있는 버퍼가 있다 (후속 버전에서는 18-word).
upstream 라우팅 단계에서, 패킷은 idle 상태의 upstream 포트에 무작위로 할당된다.
- 출력 버퍼가 비어 있으면 포트는 idle로 간주되며, 새로운 메시지를 할당받을 수 있다.
- idle 포트가 없다면, 패킷은 현 위치에서 block되며 입력 버퍼를 점유하게 되고, 결과적으로 하위 노드의 패킷들도 차단될 수 있다.
router는 출력 버퍼가 전체 메시지를 수용할 수 있을 때만 메시지를 해당 포트에 할당하므로, 메시지가 router의 crossbar를 지나는 도중에는 block되지 않는다.
10.7 참고 문헌
adaptive routing의 발전은 deadlock과 livelock을 방지하기 위한 flow control 메커니즘과 밀접하게 연관되어 있다. 초기 adaptive routing 알고리즘에는 Linder와 Harden [118], Chien [36], Aoki와 Dally [48], 그리고 Allen 외 [8]의 연구가 포함된다. Duato의 프로토콜 [61]은 Cray T3E [162]에서 사용된 알고리즘을 포함하는 adaptive routing 알고리즘 계열을 가능하게 했다. Chaos routing (Exercise 10.3)은 Konstantinidou와 Snyder [104]에 의해 소개되었고, Bolding [26]에 의해 확장되었다. CM-5에서 사용된 fat tree에서의 minimal adaptive routing은 Leiserson [114]에 의해 설명되었다. Boppana와 Chalasani [27]는 여러 라우팅 방법을 비교하고, 실제 adaptive 알고리즘이 특정 측면에서는 deterministic 알고리즘보다 못할 수 있음을 보여주었다.
10.8 연습문제
10.1 4×4 mesh에서 minimal adaptive routing의 이점: minimal adaptive routing (10.2절)이 minimal oblivious routing (9.2절)보다 우수한 permutation traffic pattern을 찾고, steady state에서 두 알고리즘의 γ<sub>max</sub>를 계산하라. (backpressure 정보가 네트워크 전체에 전파될 만큼 충분한 시간이 경과했다고 가정)
10.2 minimal과 load-balanced adaptive routing 비교: load-balanced adaptive routing (10.4절)이 minimal adaptive routing보다 나은 permutation traffic pattern 하나, 반대로 minimal이 더 나은 pattern 하나를 찾아라.
10.3 chaotic routing의 livelock 없음 증명: chaotic routing은 deflection routing 방식이다. 여러 패킷이 동일한 채널을 두고 경합할 경우, router는 임의로 하나의 패킷에 해당 채널을 할당하고, 나머지는 사용 가능한 다른 출력 포트(비생산적일 수도 있음)로 misrouting된다. 모든 입력 포트를 어떤 출력 포트에든 할당할 수 있으므로, 항상 전송은 가능하다. T cycle 동안 목적지에 도달하지 못할 확률이 T가 커질수록 0에 가까워짐을 보임으로써, livelock이 확률적으로 발생하지 않음을 설명하라.
10.4 fat tree에서 adaptive와 oblivious routing 비교: 8×8 crossbar switch로 구성된 256-node folded Clos (fat tree) 네트워크에서 dropping flow control을 사용할 때, 어떤 알고리즘이 dropping 확률이 더 낮은가? 트래픽 패턴이 바뀔 때, 두 dropping 확률은 어떻게 변하는가?
10.5 CM-5에서의 최악의 트래픽 패턴: CM-5 네트워크에 대해, randomized oblivious routing (9.2.1절)의 최악의 트래픽 패턴을 찾고, 이 패턴에 대해 adaptive와 oblivious routing의 throughput을 비교하라.
10.6 시뮬레이션: 8-ary 2-cube 네트워크에서 adaptive routing의 buffer 깊이와 응답 시간의 tradeoff를 분석하라. 두 traffic permutation을 T cycle마다 번갈아가며 적용하고, 시간에 따른 평균 패킷 지연을 그래프로 나타내라. 노드당 버퍼 크기가 이 그래프의 모양에 어떤 영향을 주는지 분석하라.
'System-on-Chip Design > NoC' 카테고리의 다른 글
| Flow Control Basics (2) | 2025.06.02 |
|---|---|
| Routing Mechanics (2) | 2025.06.02 |
| Oblivious Routing (3) | 2025.06.02 |
| Routing Basics (1) | 2025.06.02 |
| Slicing and Dicing (1) | 2025.06.02 |