이 토폴로지 섹션의 마지막 장에서는 토폴로지를 패키징하는 실용적인 방법 몇 가지를 간단히 살펴본다. 먼저 concentrator와 distributor를 살펴본다.
Concentrator는 여러 terminal node의 트래픽을 하나의 network channel로 결합한다. 단일 terminal의 트래픽이 network channel을 완전히 활용하기에 부족할 때 사용된다. 또한 bursty한 특성을 지닌 다수의 terminal 트래픽을 결합할 때에도 효과적이다. peak 대비 평균 트래픽의 비율이 클수록 concentrator를 사용하면 serialization latency가 줄고 더 비용 효율적인 네트워크가 된다.
Distributor는 concentrator의 반대 개념이다. 단일 node로부터 나오는 트래픽을 여러 network channel에 packet 단위로 분산시킨다. 단일 channel로는 처리하기 어려운 많은 양의 트래픽을 가진 node를 연결할 때 사용된다. serialization latency는 증가하고 부하 균형은 감소하지만, 어쨌든 연결이 필요한 node에 유용하게 사용될 수 있다.
하나의 network node를 여러 개의 chip이나 module에 분할하는 방법은 세 가지가 있다: bit slicing, dimension slicing, channel slicing.
- Bit slicing에서는 w-bit 너비의 node를 k개의 w/k-bit 너비의 slice로 나누어 각 slice를 개별 module에 배치한다. 각 slice는 router datapath의 w/k-bit 부분을 포함한다. 제어 정보는 모든 slice에 분산되어야 하므로 제어 정보 분산을 위한 추가 핀이 필요하고, 그만큼 latency도 증가한다.
- Dimension slicing에서는 한 dimension에 해당하는 channel 전체가 각 slice에 포함되도록 node를 나눈다. 이 방식에서는 하나의 slice에 들어온 트래픽이 다른 slice로 나가야 할 때를 대비해 추가적인 데이터 channel이 필요하다.
- Channel slicing에서는 w-bit 너비의 node를 w/k-bit channel을 가진 k개의 독립적인 node로 분할한다. bit slicing과 달리, 이들 sub-node 사이에는 연결이 없다. 전혀 별개의 네트워크를 형성한다. 이 경우 terminal마다 distributor를 사용하여 트래픽을 여러 network slice로 분산한다.
7.1 Concentrators and Distributors
7.1.1 Concentrators
일부 애플리케이션에서는 여러 (예: M개) network terminal에서 나오는 트래픽을 하나의 channel로 결합하는 것이 바람직하다. 이 경우 M개의 terminal은 하나의 큰 terminal처럼 보인다. 이 결합을 수행하는 장치를 concentrator라 부른다. 예를 들어 M=4일 때, concentrator는 terminal 측에서 M개의 양방향 channel을 받아서 network 측의 하나의 양방향 channel로 결합한다. 포트 수를 줄이는 효과 외에도 총 bandwidth도 감소시킬 수 있다.
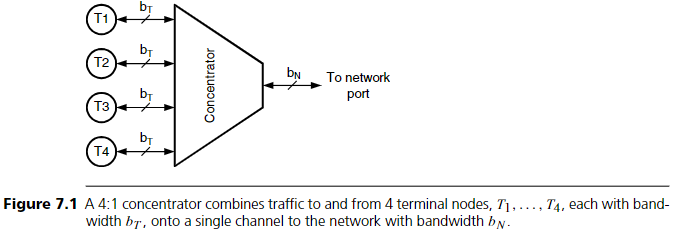
Concentration factor는 terminal 측 bandwidth 대비 network 측 bandwidth의 비율로 정의되며 다음과 같다:
kC = MbT / bN
여기서 bT는 terminal channel bandwidth, bN은 network 측 channel bandwidth이다.
예를 들어 8-node ring이 8개의 terminal을 직접 연결할 수 있다. 하지만 terminal과 network 사이에 2:1 concentrator를 배치하면 동일한 8개의 terminal을 4-node ring으로 연결할 수 있다.
Concentrator는 특히 bursty한 트래픽 특성을 가진 terminal들을 묶을 때 자주 사용된다. network 측 channel의 bandwidth를 공유함으로써 bursty source들의 부하를 완화하고 channel bandwidth를 효율적으로 사용할 수 있다.

예시로, 512-node multicomputer에서 각 node가 평균 100 Mbit/s 트래픽을 발생시키는 경우를 보자. 하지만 캐시 미스가 발생하면 128ns 동안 순간적으로 1 Gbit/s의 트래픽이 발생한다 (128bit 데이터 전송). 이 경우 serialization latency가 메모리 접근 시간을 증가시키는 것을 방지하려면, 각 processor에서 1 Gbit/s의 channel을 network으로 연결해야 한다.
이 경우 8-ary 3-cube를 1 Gbit/s channel로 구성하면 total pin bandwidth는 3Tbit/s가 된다. 평균 bandwidth만 처리할 수 있도록 network를 구성하고 worst-case 트래픽을 가정하면 200 Mbit/s channel이 필요하고, 이 경우 serialization latency는 128ns에서 640ns로 5배 증가한다.
더 효율적인 방법은 8개 node를 8:1 concentrator로 묶고, 64-node 4-ary 3-cube network를 구성하는 것이다. concentrator에서 network node로 2 Gbit/s channel을 연결하여 병목을 방지한다. 이 경우 각 concentrated node는 평균 800 Mbit/s를 제공한다. 최대 8 Gbit/s 트래픽이 발생할 수도 있지만, 실제로는 동시에 두 개 이상의 node가 전송하는 경우는 매우 드물다 (동시에 8개 node가 전송할 확률은 10⁻⁸). 따라서 평균적인 상황에서는 network diameter와 serialization latency가 줄어드는 이점이 더 크다.
network를 1 Gbit/s channel로 구성하면 total pin bandwidth는 384 Gbit/s로 감소하며 (기존 대비 8배 감소), 평균 bandwidth 기준으로 구성하면 800 Mbit/s channel로 충분하고, 이 경우 latency는 160ns로 4배 줄어든다.
또한 concentrator는 packaging 관점에서도 유리하다. 예를 들어 4개의 terminal이 하나의 module (예: chip)에 함께 배치되는 경우, 이들 terminal의 트래픽을 concentrator로 결합해 module 전체를 하나의 network terminal로 간주할 수 있다.
7.1.2 Distributors
Distributor는 concentrator의 반대이다. 예를 들어 1:4 distributor는 하나의 고속 channel에서 받은 트래픽을 여러 개의 저속 channel로 분산한다.
겉보기에는 distributor가 concentrator를 반대로 사용한 것처럼 보이지만, 기능은 다르다. concentrator를 통해 reverse 방향으로 이동하는 packet은 특정 terminal로 도달해야 한다. 반면 distributor는 packet을 어떤 network channel로 보낼지 자유롭게 정할 수 있다. 분산 방식은 random, round-robin, 또는 load balancing일 수 있다. 경우에 따라, 같은 class에 속한 packet은 항상 동일한 channel로 보내서 순서를 유지할 수도 있다.
Distributor는 다양한 상황에서 사용된다. 예를 들어 고속 processor나 고속 line card와 같은 고 bandwidth module을 저속의 network에 연결할 때, 여러 network port를 통해 분산시켜 사용된다. 또는 fault tolerance를 위해 distributor를 사용하는 경우도 있다. 전체 트래픽을 두 개의 half-speed channel로 분산시키면, 한 channel이 고장나더라도 network 성능은 절반으로 줄어드는 정도로 gracefully degrade된다.

Distributors는 channel의 bandwidth가 router가 처리하기에 너무 높은 경우에도 사용된다. 예를 들어, 클럭 주파수가 500MHz (2ns 주기)이고, packet이 8바이트이며 router가 4 클럭마다 1개 packet만 처리할 수 있다고 하자. 이 경우 해당 router가 처리할 수 있는 최대 bandwidth는 8바이트/8ns, 즉 1GByte/s이다. 만약 4GByte/s port를 network에 연결하고자 한다면, 1:4 distributor를 사용하여 이 트래픽을 router가 감당할 수 있는 낮은 bandwidth channel로 나눠야 한다. 이렇게 낮은 bandwidth channel로 나눈 후에는 여러 포트를 가진 단일 network에 삽입하거나, 병렬 network에 삽입할 수 있다. (이것은 channel slicing이라 불리며, Section 7.2.3에서 설명한다.)
하지만 network에 distributor를 추가하면 성능에 두 가지 측면에서 악영향을 미친다.
첫째, serialization latency가 증가한다. packet의 serialization latency는 병목이 되는 링크에서 L/b로 주어지며, 여기서 b는 bandwidth이다. 따라서 terminal 링크의 bandwidth가 bT, network channel의 bandwidth가 bN일 때 distributor는 latency를 bT/bN만큼 증가시킨다. serialization latency에 비례하는 queueing delay도 그만큼 늘어난다.
둘째, distributor는 load balance를 감소시킨다. distributor의 출력 채널 간 부하 분산은 완벽하지 않으며, 병렬 network에 분산된 경우 어느 시점에서는 하나의 링크가 과부하되고 다른 링크는 유휴 상태일 수 있다. 일반적으로 성능 관점에서는 자원을 공유하는 것이 더 낫다. 즉, distribution은 성능을 저해하지만, 구현 용이성이나 fault tolerance 측면에서는 도움이 된다.
7.2 Slicing and Dicing
가끔 network node가 하나의 module (chip 또는 board)에 모두 담기지 않는 경우가 있다. 이는 대부분 핀 수 제한 때문이지만, 면적 (특히 memory) 문제일 수도 있다. 이런 경우 router를 여러 개 chip에 나눠야 하며, 이를 slicing이라 한다. slicing에는 세 가지 방법이 있다: bit slicing, dimension slicing, channel slicing.
7.2.1 Bit Slicing
가장 단순한 slicing 방법은 bit slicing이다. 각 channel이 w비트일 때, node를 m개의 chip으로 나누려면 각 chip에 w/m비트씩 배치하면 된다. 예를 들어, Figure 7.4에서는 w=8비트인 2D node를 두 개의 4비트 module로 나눈다. 각 방향에 대한 channel은 4비트씩 분할되고, 몇 개의 제어선 (ctl)은 두 router bit slice 간 정보를 전달하는 데 사용된다.

Bit slicing의 어려움은 control 분산과 fault recovery에 있다. 하나의 flit은 반은 node[0:3], 나머지 반은 node[4:7]로 도착하지만, flit 전체는 하나의 단위로 스위칭되어야 한다. 이를 위해 두 slice는 완전하고 동일한 control 정보를 가져야 한다.
가장 큰 문제는 header 정보의 분산이다. 경로, 목적지, virtual channel 등을 포함하는 header bit를 두 slice로 모두 전달해야 한다. 이 경우 control 채널을 통해 모든 header bit가 전달되어야 하며, 이는 pin overhead와 latency overhead를 야기한다. 작은 flit에서는 header 비트가 전체 flit의 25% 이상을 차지할 수 있다. header 전송은 일반적으로 두 개의 클럭을 latency로 추가한다.
Pin bandwidth overhead를 줄이기 위해, control은 한 slice에서만 수행하고 결정된 control 신호만 다른 slice에 전달할 수도 있다. 그러나 이 방법도 latency는 줄일 수 없다.
또한, CRC와 같은 오류 검출 기능을 모든 slice에서 나눠 수행해야 하므로 slice 간 중간 결과를 교환해야 한다. transient fault로 인해 두 slice 간 control state가 불일치할 경우, robust한 sliced router는 state를 항상 동기화하고 복구할 수 있어야 한다.
이런 복잡성에도 불구하고, flit이 큰 router에서는 overhead를 감당할 수 있어 bit slicing이 효과적이다. 특히 flit-reservation flow control 같은 방식에서는 control이 data보다 먼저 pipeline으로 전달되므로 유리하다.
7.2.2 Dimension Slicing
Bit slicing에서의 control 및 error 처리 복잡성을 피하기 위해, flit 전체를 한 slice에 유지하는 slicing 방법이 dimension slicing이다. router의 port 단위로 slicing을 하며, 각 port는 하나의 slice에 완전하게 포함된다. 이로 인해 degree가 d인 network node는 degree가 (d/m + p)인 m개의 node로 나뉘며, p는 slice 간 통신을 위한 포트 수이다.

예를 들어, Figure 7.5는 w=8-bit의 2D router를 두 개의 1D router로 나눈 것이다. 하나는 north-south 트래픽, 다른 하나는 east-west 트래픽을 담당한다. 더 세분화가 필요하면, 각 방향별로 별도의 1D unidirectional router로 나눌 수 있다.
이 두 router 간의 channel은 방향 전환 트래픽을 모두 수용할 수 있는 bandwidth를 가져야 한다. 방향 전환량은 routing algorithm에 따라 크게 달라진다. 예를 들어 dimension-ordered routing은 방향 전환을 피하므로 필요한 bandwidth가 적다.
7.2.3 Channel Slicing
앞선 두 방식은 partition 간 통신이 필요하다. bit slicing은 control 정보를, dimension slicing은 데이터 경로를 교환해야 한다. 반면, channel slicing은 이 모든 통신을 제거하고 network 전체를 완전히 독립적인 두 개의 네트워크로 나눈다. 유일한 연결은 terminal에서 distributor를 통해 트래픽을 나누고 목적지에서 다시 결합하는 부분뿐이다.

Figure 7.6은 channel slicing을 보여준다. w=8bit의 2D network node는 w=4bit의 두 개의 node로 완전히 분리된다. 두 network 간에는 어떠한 연결도 없으며, terminal 링크 (그림에는 표시되지 않음)만 연결된다.
7.3 Slicing Multistage Networks
Multistage network에서 slicing을 적용하면 **serialization latency (Ts)**와 head latency (Th) 간의 trade-off를 조절할 수 있다. 이는 네트워크 전체 latency를 두 구성 요소의 균형을 맞춰 최적화하는 방식이다. 이 기법은 5.2.2절에서 torus의 차원을 조정하여 Ts와 Th의 균형을 맞추는 것과 유사하다.
Multistage network에 channel slicing을 적용하면 routing component 수와 총 pin 수를 줄여서 전체 비용을 낮출 수 있다.
예를 들어, N = kⁿ개의 노드를 갖는 k-ary n-fly 구조에서, channel 너비가 w일 경우, 이를 x개의 xk-ary n′-fly 네트워크로 분할할 수 있으며, 각 네트워크의 channel 너비는 w/x가 된다.
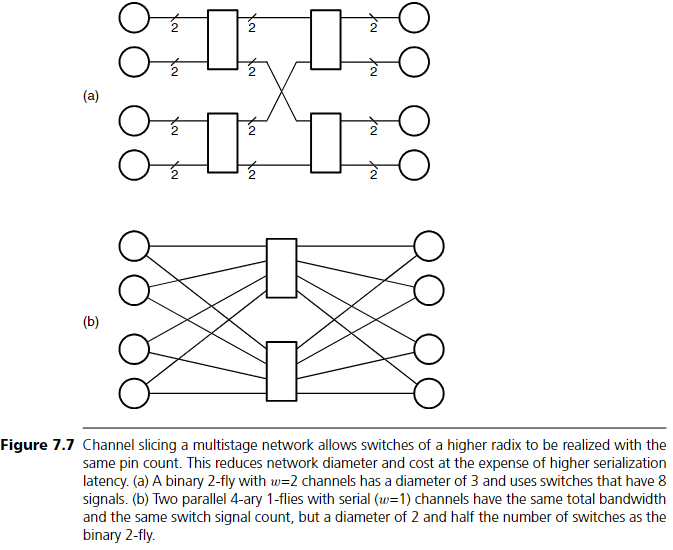
Figure 7.7에서는 2비트 channel을 갖는 binary 2-fly network를, 직렬 전송(1비트 channel)의 4-ary 1-fly 두 개로 대체하여 비용과 diameter를 줄이는 예시를 보여준다. 두 방식 모두 같은 bandwidth를 제공하며, switch당 동일한 pin 수(8개 signal)를 사용한다. 그러나 channel-sliced 구조는 diameter가 작고 필요한 switch 수도 절반이다.
Slicing을 적용하면 network의 diameter는 기존 n+1에서 n′+1로 줄어들며,
n′ = n / (1 + logₖx)
가 된다.
따라서 latency는 다음과 같이 주어진다:
- Serialization latency: Ts = xL / b
- Head latency: Th = tᵣ × (n / (1 + logₖx))
(여기서 tᵣ은 wire delay, L은 message 길이, b는 bandwidth)
예제: N = 4096 노드, binary 12-fly, w = 32, b = 1 Gbit/s, tᵣ = 20ns, L = 256 bit
slicing factor x를 1부터 32까지 늘리며 latency 변화를 보면 다음과 같다:
| 1 | 2 | 12 | 32 | 8 ns | 240 ns | 248 ns |
| 2 | 4 | 6 | 16 | 16 ns | 120 ns | 136 ns |
| 4 | 8 | 4 | 8 | 32 ns | 80 ns | 112 ns |
| 8 | 16 | 3 | 4 | 64 ns | 60 ns | 124 ns |
| 16 | 32 | 3 | 2 | 128 ns | 60 ns | 188 ns |
| 32 | 64 | 2 | 1 | 256 ns | 40 ns | 296 ns |

Figure 7.8에서는 slicing factor(x)에 따른 전체 latency T와 Ts, Th의 변화를 그래프로 보여준다.
x = 4일 때 Ts와 Th가 균형을 이루며 최소 latency (112 ns)를 얻는다.
x가 더 커지면 Ts의 증가 폭이 Th의 감소 폭보다 커져 전체 latency가 다시 증가하게 된다.
극단적인 경우인 x = 32에서는 직렬 전송만으로 구성된 2-stage, radix-64 네트워크가 되어 Ts = 256ns로 가장 크며, pin 비용은 가장 작다.
이러한 channel slicing 기법은 butterfly network에 설명했지만, Clos network와 Batcher network 같은 다른 multistage network에도 적용 가능하다 (Exercise 7.5 참고). 또한 bit slicing으로도 multistage network를 나눌 수 있다 (Exercise 7.6 참고).
7.4 사례 연구: Tiny Tera에서의 Bit Slicing
Tiny Tera는 Stanford University에서 설계되고 Abrizio에서 상용화된 고속 packet switch이다. 이름처럼, 전체 aggregate bandwidth는 1Tbit/s이다. Figure 7.9는 Tiny Tera의 고수준 구조를 보여준다.

- 32×32, 8비트-wide crossbar를 중심으로 구성된다.
- 각 port card는 crossbar와 외부 네트워크 간의 input/output buffering을 제공한다.
- 중앙 scheduler는 crossbar 구성(config)을 계산하고 각 port card에 전달한다.
Scheduler가 계산한 구성 정보는 각 packet에 붙어서 crossbar로 전달된다.
Crossbar 구현의 어려움은 pin 수에서 나타난다.
- 각 포트는 송수신 16 Gbit/s를 다루며, 이는 16개 signal, 즉 32개 pin을 필요로 한다.
- 포트가 32개이므로 총 1024개의 고속 핀이 필요하다.
(power/ground pin, 전력 소모까지 고려하면 이보다 훨씬 부담됨)
그래서 Tiny Tera의 설계자는 bit slicing을 선택했다.

Figure 7.10에 보이듯이,
- crossbar는 8개의 32×32 1비트-wide crossbar로 나뉘어 구성되었다.
- 이렇게 하면 chip당 128개 고속 pin으로 핀 수를 줄일 수 있고, 전력 소모도 각 chip에 분산된다.
- input/output queue도 bit 단위로 slicing 되어 여러 개의 SRAM에 나뉘어 저장된다.
(그림에는 생략)
이러한 sliced 설계는 패키징 이슈를 줄일 뿐 아니라 유연성도 향상시킨다.
예를 들어, 필요한 경우 crossbar slice를 더 추가할 수 있다.
Figure 7.10 설명
Tiny Tera crossbar의 bit slicing 구현. 8비트 인터페이스는 8개의 slice로 분할되며, crossbar chip당 128개의 데이터 핀만 필요하다. 각 slice는 1비트 폭의 32×32 crossbar로 구성된다.
이러한 구조는 속도를 부분적으로 향상시키거나, 신뢰성을 높이기 위해 crossbar slice를 추가할 수 있다. 만약 단일 crossbar chip을 사용했다면, 속도 향상이나 redundancy 확보를 위해서는 전체 crossbar를 또 하나 추가해야 했을 것이다.
7.5 참고 문헌 노트
Slicing, concentration, distribution은 오래전부터 사용되어 왔다. 전화망에서는 대부분의 전화기가 사용되지 않고 있다는 점을 고려해 concentration이 오래전부터 활용되었다.
- J-Machine router는 dimension slicing이 적용되었으며, 세 개의 slice가 단일 chip에 탑재되었다 (5.5절 참고).
- Cray T3D는 각 slice를 개별 ECL gate array에 배치하는 유사한 구조를 사용했다.
- MARS accelerator와 Tiny Tera (7.4절 참조)는 bit sliced crossbar를 사용했다.
- Avici TSR는 6개의 4비트 slice로 구성된 bit sliced 3D torus를 사용했다.
7.6 연습문제
7.1 Torus에서의 concentration
4096개의 노드를 연결해야 하며, 각 노드는 peak bandwidth가 10 Gbit/s, 평균 500 Mbit/s를 가진다. bisection bandwidth는 2.56 Tbit/s로 고정된 torus network에서, concentrator, 차원 수, radix 측면에서 다양한 topology를 비교하라. 모든 concentrator와 router node는 별도의 chip에 패키징되며 chip당 최대 100 Gbit/s의 pin bandwidth를 가진다.
- 가장 낮은 pin bandwidth를 제공하는 topology는 무엇인가?
- serialization latency를 증가시키지 않고도 가장 낮은 pin bandwidth를 제공하는 topology는 무엇인가?
7.2 Line card에서의 traffic distribution
64개의 40 Gbit/s line card를, 10 Gbit/s를 초과하지 않는 channel로 구성된 torus network에 연결하려 한다. 모든 노드가 bisection을 통과하여 트래픽을 전송하는 worst-case traffic을 지원해야 한다.
- distributor를 사용해 어떻게 연결할 수 있을까?
- 채널 속도가 40 Gbit/s인 경우와 비교해 bisection bandwidth는 어떻게 달라질까?
7.3 Butterfly slicing
Radix-4 butterfly node (w=2비트 channel)를 두 개의 module로 나누는 세 가지 slicing 방식 (bit, dimension(port), channel)을 고려하라.
- flit 크기는 64비트, 이 중 16비트는 header이다.
- 각 분할 방식을 스케치하고 channel width 및 chip당 필요한 signal 수를 표시하라.
- 각 경우의 latency 특성을 정성적으로 비교하라.
7.4 Sub-signal slicing
channel slicing factor를 채널이 1 signal보다 좁아지도록 설정할 수도 있다. 예를 들어, slicing 결과가 0.5 signal이면, 두 채널이 하나의 물리적 signal을 공유하게 된다.
- 이런 수준의 slicing이 zero-load latency를 줄이는 데 도움이 될 수 있을까?
7.5 Clos network의 channel slicing
N = 256인 rearrangeable Clos network (m = n)에서, switch는 32 signals, 각 노드는 8 Gbit/s bandwidth 필요, L = 128, tᵣ = 20 ns, f = 1 Gbit/s일 때,
- latency를 최소화하는 slicing factor x를 구하라.
7.6 Butterfly network의 bit slicing
Table 7.1 첫 번째 row의 network 조건에 기반한 4096 node butterfly network에서,
- zero-load latency를 최소화하는 bit slicing을 구하라.
- 각 bit slice마다 32-bit header가 반복되며, slice 간 control signal은 필요 없다.
- router latency tᵣ는 전체 header 수신 이후부터 적용된다.
7.7 Tiny Tera의 header 분배
Tiny Tera의 bit sliced switch에서 crossbar 구성은 centralized scheduler에 의해 계산된 뒤 input port로 분배된다. 각 packet slice에는 해당 header 정보가 덧붙는다.
- 포트 A를 기준으로, A에서 전송되는 packet은 목적지가 아니라 A로 전송한 포트의 주소를 담고 있다.
- 왜 이런 방식이 더 효율적인 encoding이 되는가?
힌트: Tiny Tera는 multicast 트래픽을 지원한다.
'System-on-Chip Design > NoC' 카테고리의 다른 글
| Oblivious Routing (3) | 2025.06.02 |
|---|---|
| Routing Basics (1) | 2025.06.02 |
| Non-Blocking Network (2) | 2025.06.02 |
| Torus Networks (2) | 2025.06.02 |
| Butterfly Networks (1) | 2025.06.02 |