
초록 (Abstract)
본 장에서는 응용 프로그램 집합에 맞춤화된 minimal deterministic routing algorithm을 설계하기 위한 system-level framework를 제시한다. 이를 위해 먼저 네트워크의 평균 패킷 지연(latency)을 최소화하는 최적화 문제를 공식화하고, 이를 해결하기 위해 simulated annealing heuristic을 사용한다. 평균 패킷 지연을 추정하기 위해 트래픽의 burstiness을 반영할 수 있는 queueing 기반의 분석 모델을 사용한다. 제안된 프레임워크는 deadlock freedom을 보장하기 위해 virtual channel을 필요로 하지 않으며, 이는 acyclic channel dependency graph에서 route를 추출함으로써 달성된다. synthetic workload와 realistic workload를 이용한 실험을 통해 본 접근 방식의 효과가 입증되었다. 다양한 응용 및 아키텍처에서 network의 최대 지속 가능한 처리량(maximum sustainable throughput)이 향상됨을 확인하였다.
2.1 Introduction
ASIC(Application Specific Integrated Circuit)은 높은 성능과 낮은 전력 소모 덕분에 embedded system-on-chip 설계에 흔히 사용되어 왔다. 반도체 기술의 발전으로 인해 reconfigurable logic과 ASIC 모듈의 통합이 가능해졌으며, 이는 DSP, 멀티미디어, 컴퓨터 비전과 같은 계산량이 많은 응용 프로그램을 구현하는 데 있어 새로운 대안으로 사용되고 있다.
2000년대 초, Network-on-Chip (NoC)은 on-chip architecture에서의 표준 솔루션으로 등장하였다.
2.2 Related Work
Turn model은 mesh 및 hypercube 네트워크에서 부분적으로 adaptive routing algorithm을 설계하기 위해 제안되었다 [9]. 최소한의 turn만을 금지함으로써 모든 cycle을 제거하고 deadlock-free routing을 생성할 수 있다. 이 모델은 이후 Odd-Even adaptive routing algorithm 개발에 사용되었다. 이 방식은 특정 위치에서만 turn을 허용함으로써 deadlock을 방지한다. Turn model에 비해 Odd-Even routing은 다양한 source-destination pair에 대해 보다 균등한 라우팅 적응성을 제공한다.
DyAD routing scheme은 deterministic과 adaptive 라우팅을 결합한 방식으로, 네트워크가 혼잡하지 않을 때는 deterministic 모드로, 혼잡할 때는 adaptive 모드로 동작한다. 각 라우터가 자신의 부하를 측정하여 이웃에게 전달하고, 이 정보를 바탕으로 hot-spot을 회피하는 경로를 결정하는 방식을 제안하였다. APSRA라는 방법론도 제시되었는데, 이는 애플리케이션별 통신 쌍 및 통신하지 않는 쌍 정보를 활용해 적응성(adaptivity)과 성능을 극대화하도록 설계되었다.
이러한 방식들은 모두 adaptive routing 기반이므로 packet 순서가 어긋나는 문제를 겪는다. 본 장에서 제안하는 방식은 이러한 문제를 피하면서도 네트워크 평균 지연을 최소화한다. application-aware oblivious routing이 제안되었고, 이는 정적으로 deadlock-free route를 설정한다. 여기서는 mixed integer-linear programming 및 heuristic 방법을 사용하여 채널 부하를 최소화하였다. 그러나 task mapping의 영향은 분석하지 않았으며, 이에 우리는 혼잡 인식 라우팅(congestion-aware routing)을 제안하였다. 하지만 이 프레임워크는 트래픽의 burstiness를 반영하지 못하므로, 본 연구에서는 [14]에서 제안된 분석 모델을 이용하여 이를 처리한다.
2.3 LAR Framework
Latency-Aware Routing (LAR) 프레임워크는 Fig. 2.1의 flowchart와 같이 총 5단계로 구성된다.

- Topology Graph (TG) 및 Communication Graph (CG)를 통해 아키텍처 및 애플리케이션을 모델링한다.
- TG와 CG를 기반으로 Channel Dependency Graph (CDG)를 구성한다.
- Deadlock을 방지하기 위해 CDG에서 일부 edge를 삭제하여 acyclic CDG를 추출한다.
- 각 흐름(flow)에 대해 가능한 모든 최단 경로를 찾고 routing space를 생성한다.
- routing space 상에서 최적화 문제를 정의하고 해결한다.
2.3.1 Model Architecture and Application
Topology Graph (TG)는 NoC 아키텍처의 topology를 표현하는 유향 그래프로, node는 core 및 wormhole-switched router를 나타내며, link는 edge로 표현된다. 각 core는 processor, DSP, reconfigurable HW, I/O controller 또는 memory block일 수 있으며, Resource Network Interface (RNI)를 통해 router와 연결된다.
RNI는 패킷을 포장 및 해제하고 injection channel을 통해 네트워크에 주입하거나 ejection channel을 통해 네트워크에서 제거한다. Fig. 2.2는 4×4 mesh network의 TG를 나타낸다.

Communication Graph (CG)는 애플리케이션을 모델링한 유향 그래프로, 각 노드는 task를, 각 edge는 task 간의 통신량을 나타낸다. 예를 들어, Fig. 2.3은 VOPD(Video Object Plane Decoder) 애플리케이션의 CG를 보여주며, 각 edge 근처의 숫자는 bandwidth(MBytes/s)를 나타낸다.

2.3.2 Construct Channel Dependency Graph
Dally와 Seitz는 deadlock-free routing 알고리즘 설계를 단순화하기 위해 acyclic CDG가 deadlock-free를 보장함을 증명하였다. CDG의 각 vertex는 TG 내의 channel이며, 두 channel 간 direct한 연속 사용이 가능할 경우 edge를 둔다. Dijkstra 알고리즘을 사용하여 TG에서 가능한 모든 source-destination pair 간 최단 경로를 구하고 이를 기반으로 CDG의 edge를 생성한다. Fig. 2.4a는 minimal fully adaptive routing 하에서 4×4 mesh network의 CDG를 보여준다.

2.3.3 Remove Cycles from CDG
전통적인 routing algorithm은, 예를 들어 dimension-order routing (DOR)과 turn model처럼, 트래픽 패턴에 관계없이 CDG에서 일부 edge를 체계적으로 제거하여 acyclic CDG를 생성한다. 하지만 이는 종종 불필요한 turn을 금지함으로써 routing algorithm의 성능을 저하시킬 수 있다. 예를 들어, Fig. 2.4b에서 보는 바와 같이 transpose traffic pattern 하의 4×4 mesh network의 CDG에는 cycle이 없다. 이 패턴은 행 i, 열 j에 있는 노드가 행 j, 열 i에 있는 노드로 패킷을 전송하는 구조다. 그러나 기존의 알고리즘들은 이러한 상황에서도 보수적으로 edge들을 제거한다.
우리는 CDG에서 cycle을 찾기 위해 depth-first-search (dfs) 알고리즘을 수정하였다. 최소한의 edge만 제거하기 위해, 여러 cycle에 공유되어 있는 edge를 우선적으로 삭제한다. 단, 모든 flow의 reachability가 보장되는 경우에만 해당 edge를 제거한다. 예를 들어 Fig. 2.4a의 4×4 mesh network의 CDG에는 총 6,982,870개의 cycle이 존재하며, 이 중 vertex 40에서 vertex 01로 가는 edge는 5,041,173개의 cycle에 공유된다. 따라서 이 edge를 제거하면 cycle 수는 1,941,697로 크게 줄어든다. 이 과정을 반복하여 CDG에 cycle이 더 이상 없을 때까지 수행한다.
Table 2.1은 다양한 mesh network에서 LAR이 찾아낸 cycle의 수를 보여준다. TG의 크기가 증가함에 따라 CDG의 cycle 수는 기하급수적으로 증가하며, 모든 cycle을 찾는 데 매우 긴 시간이 소요된다. 따라서 우리는 CDG 내에서 일정 수 이상의 cycle이 존재할 경우, 가장 많은 cycle에 공유된 edge를 찾아 제거하는 방식으로 진행한다.

2.3.4 Create Routing Space (RS)
이 단계에서는 acyclic CDG에 대해 Dijkstra 알고리즘을 적용하여 TG 내 모든 flow의 source와 destination 간 모든 최단 경로를 찾는다. 이를 통해 flow 수 f에 대한 routing space RS = {F₁, F₂, ..., F_f}를 생성한다.
각 flow Fᵢ는 다음과 같이 정의된다:
Fᵢ = (λᵢ, CAᵢ, nᵢ, Pᵢ)
- λᵢ: flow i의 평균 패킷 생성율
- CAᵢ: 패킷 도착 간격의 coefficient of variation (CV)
- CV는 확률변수 X에 대해 C²_X = x² / x̄² − 1로 정의됨
- [14]에서는 CV가 burstiness intensity를 잘 반영한다고 설명
- nᵢ: flow i에 대해 가능한 최단 경로의 수
- Pᵢ: flow i의 모든 nᵢ개의 route 집합
일반적으로 두 노드 사이에는 1개 이상의 최단 경로(nᵢ > 1)가 존재하므로, 평균 패킷 지연(latency)을 최소화하는 경로를 선택하는 것이 합리적이다. 다음 절에서는 RS 내에서 각 flow에 적합한 route를 찾기 위한 최적화 문제를 정의하고, 이를 해결하기 위해 simulated annealing heuristic을 사용하는 방법을 제시한다.
2.3.5 Routing Space Exploration
2.3.5.1 Define Optimization Problem
이 절에서는 RS 내의 routing space를 탐색하기 위한 최적화 문제를 정의한다. 이를 위해 먼저 결정 변수(decision variables)와 목적 함수(objective function)를 정의해야 한다.
목표는 각 flow i (1 ≤ i ≤ f)에 대해 가능한 nᵢ개의 경로 중 하나를 선택하여 평균 패킷 지연(latency)을 최소화하는 것이다. 이를 위해, X = {x₁, x₂, ..., x_f} 라는 결정 변수 집합을 정의하고, 여기서 xᵢ는 flow i에 대해 선택된 경로의 번호이며, 1 ≤ xᵢ ≤ nᵢ이다.
목적 함수는 네트워크의 평균 패킷 지연이다.
이러한 문제를 시뮬레이션을 통해 해결하려면 연산량이 매우 커지며, 네트워크 크기 증가에 따라 exploration space가 폭발적으로 증가하므로 최적화 루프 내에서 시뮬레이션 사용은 비현실적이다. 따라서 다음 절에서는 효율적인 분석 모델(analytical model)을 통해 근사 최적 해를 빠르게 구하는 방법을 설명한다.
2.3.5.2 Analytical Latency Model
다른 output channel들에 대해서는 일반적인 수식으로 직접적으로 계산할 수 없으며, 더 복잡한 접근 방식이 필요하다. 이제 우리는 OCi<sup>M</sup>의 average service time (first moment)을 다음과 같이 추정할 수 있다:


2.3.5.3 Simulated Annealing
Simulated Annealing은 매우 큰 탐색 공간에서 global optimization problem을 해결하기 위한 확률 기반 계산 기법이다. 주로 탐색 공간이 이산적일(discrete) 경우에 사용된다. 예를 들어, module placement나 packet routing과 같은 CAD 문제에서 사용된 바 있다. 이러한 문제에 대해 simulated annealing은 전수 검색(exhaustive enumeration)보다 더 효율적일 수 있다.
Simulated annealing은 최적 해를 반드시 찾는 것은 아니지만, 제한된 시간 내에 충분히 양호한 해를 찾을 수 있는 장점이 있다. 이 방법은 1983년, 1985년에 독립적으로 제안되었다. 이 기법은 금속 열처리 과정(annealing)에서 유래한 것으로, 물질을 가열한 후 서서히 냉각시켜 결정 크기를 키우고 결함을 줄이는 원리를 따른다.
이 물리적 annealing 과정을 모사하기 위해, 알고리즘은 초기 해에서 시작해 매 반복마다 무작위로 trial solution을 생성한다. 이 trial solution이 objective function 값을 낮추면(더 나은 해이면) 무조건 수용하며, 그렇지 않더라도 일정 확률로 수용한다. 일반적으로 Metropolis algorithm을 acceptance criterion으로 사용하며, 이는 다음과 같다:
e−ΔE/T>R(0,1)(2.9)e^{- \Delta E / T} > R(0,1) \tag{2.9}
여기서
- ΔE는 현재 해와 trial solution 간의 objective function 값의 차이 (더 나은 경우 음수, 더 나쁜 경우 양수),
- T는 synthetic temperature,
- R(0,1)은 [0,1] 범위의 난수이다.
이 과정은 시스템이 충분히 좋은 상태에 도달하거나, 지정된 계산량이 소진될 때까지 반복된다. 이처럼 나쁜 해도 수용함으로써, 알고리즘이 초기 local minimum에 갇히는 것을 피하고, global 탐색을 수행할 수 있게 된다. 보다 자세한 내용은 [17] 참고.
앞서 2.3.5.1절에서 설명한 것처럼, objective function은 average packet latency, 결정 변수는 routing set X = {x₁, x₂, ..., x_f}이다. 여기서 xᵢ는 flow i에 대해 선택된 경로 번호이다 (1 ≤ xᵢ ≤ nᵢ).
초기 routing set X = {x₁, x₂, ..., x_r, ..., x_f}에서, trial routing set X<sub>new</sub> = {x₁, x₂, ..., x_r<sup>new</sup>, ..., x_f}를 만들기 위해 다음 단계를 따른다:
- 1 ≤ r ≤ f 범위에서 랜덤 숫자 r을 선택해 flow를 고르고,
- 1 ≤ x<sub>r</sub><sup>new</sup> ≤ n<sub>r</sub> 범위에서 다른 경로 번호 x<sub>r</sub><sup>new</sup>를 선택한다 (단, x<sub>r</sub><sup>new</sup> ≠ x<sub>r</sub>).
그리고 2.3.5.2절의 analytical model을 사용해, 현재 routing set과 trial routing set에 대한 평균 패킷 지연을 계산한다.
2.4 Experimental Results
제안된 프레임워크의 성능을 평가하기 위해, 우리는 flit level에서 routing algorithm의 동작을 모사하는 discrete-event simulator를 개발하였다. NoC 분야에서 mesh network의 인기가 높기 때문에, 본 실험에서는 mesh topology를 중심으로 분석하였으나, LAR 프레임워크는 다른 topology에도 변경 없이 동일하게 적용될 수 있다. 모든 실험에서, simulated annealing 알고리즘의 초기 해로는 DOR routing을 사용하였다. LAR의 성능은 2D mesh network에서 XY routing이 되는 DOR과 비교하였다.
시뮬레이션 결과의 정확도를 높이기 위해, 우리는 batch means method를 사용하였다. 전체 실험은 10개의 batch로 구성되었으며, 각 batch는 workload 유형, 패킷 주입률, network 크기에 따라 1,000개에서 최대 1,000,000개의 패킷을 포함하였다. 시뮬레이션 시작 단계의 편향을 피하기 위해 첫 번째 batch에서는 통계 수집을 하지 않았다. 지연 시간(latency) 측정의 표준편차는 평균값의 1.8% 이하였으며, 그 결과 시뮬레이션 결과의 신뢰수준(confidence level)은 0.99, 신뢰구간(confidence interval)은 0.02로 설정되었다.
보다 포괄적인 연구를 위해, 다양한 workload 유형과 network 크기 조합에 대해 여러 검증 실험을 수행하였다. 이후에서는 synthetic traffic과 realistic traffic 모두에 대해 LAR의 성능을 평가한다. 이 두 traffic 유형은 응용 목적이 매우 다르므로, 그에 따른 트래픽 패턴 또한 크게 상이하다.
2.4.1 Synthetic Traffic
본 연구에서 사용된 synthetic traffic pattern은 uniform, transpose, shuffle, bit-complement, bit-reversal이다 [5]. spatial traffic distribution을 설명하는 모델을 설계한 후, 우리는 temporal traffic distribution을 설명할 수 있는 적절한 모델을 사용해야 한다. synthetic traffic의 경우, 우리는 Poisson process를 사용하여 시간 축 방향의 트래픽 변동을 모델링하였다. 이는 하나의 core에서 연속된 두 패킷 사이의 시간 간격이 지수 분포를 따른다는 의미이다. Poisson 모델은 다양한 성능 분석 연구에서 광범위하게 사용되며, 이 확률적 가정을 기반으로 한 수많은 논문들이 존재한다.
Fig. 2.5와 Fig. 2.6에서는 각각 4×4, 8×8 mesh network에서 network의 offered load에 따라 average packet latency가 어떻게 변화하는지를 보여준다.
- Uniform과 bit-complement traffic pattern 하에서는, LAR의 결과가 DOR와 수렴한다. 이는 해당 트래픽에서는 DOR이 이미 평균 지연이 최소이기 때문이며, simulated annealing이 더 나은 경로를 찾지 못했음을 의미한다. 즉, 최종 해가 초기 해와 동일하다. 이러한 결과는 [4, 9, 12, 19]의 기존 결과와도 일치한다. 그 이유는 DOR이 장기적으로 균일하게 트래픽을 분산시키기 때문이다 [9]. 기존의 Odd-Even [4], Turn Model [9], DyAD [12], APSRA [19] 등의 연구도 uniform traffic에서는 DOR보다 성능이 낮았음을 보여준다. Fig. 2.5a, Fig. 2.6a에서도 확인되듯이, 우리 프레임워크는 다양한 트래픽 부하에서도 DOR과 동일한 성능을 보인다.
- Fig. 2.5b, c에서는 transpose와 bit-reversal workload 하에서 4×4 mesh network에서의 DOR과 LAR의 latency를 비교한다. 여기서는 LAR이 DOR보다 명확히 더 나은 성능을 보인다. 8×8 mesh network의 경우에도 Fig. 2.6b, c에서처럼 LAR이 DOR을 능가한다.
- Fig. 2.5d, Fig. 2.6d에서는 shuffle traffic pattern 하에서 LAR이 DOR보다 조금 더 좋은 성능을 보인다.

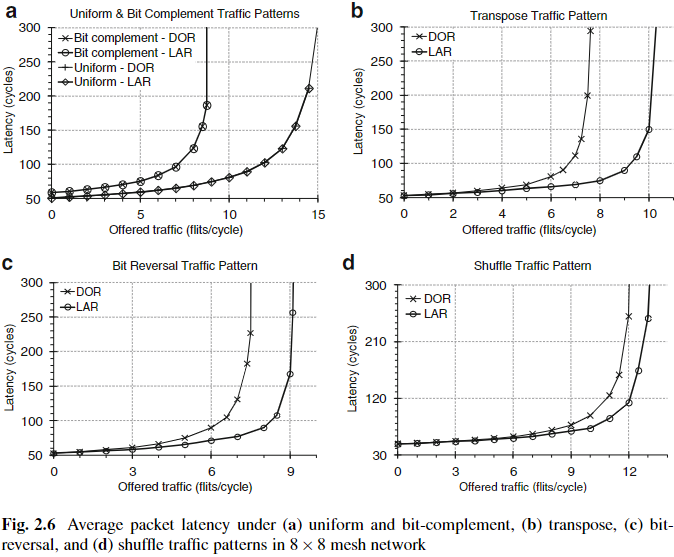
Table 2.3은 각각의 workload에 대해, 4×4 및 8×8 mesh network에서 DOR과 LAR의 maximum sustainable throughput과 그 개선율(%)을 보여준다. 평균적으로 LAR이 DOR을 능가함을 확인할 수 있으며, LAR을 사용한 경우 network가 감당할 수 있는 최대 트래픽 부하는 최대 205%까지 개선되었다.

또한 우리는 LAR 프레임워크의 성능을 DyAD routing scheme과 비교하였다. DyAD는 deterministic routing과 adaptive routing을 결합한 구조다. 우리는 동일한 구조(6×6 mesh network)에서 uniform과 transpose workload를 시뮬레이션하고, 이들의 DOR 대비 성능 개선률을 비교하였다.
Table 2.4는 DOR 대비 DyAD와 LAR의 개선률(%)을 보여준다.
- Uniform traffic의 경우, DyAD는 오히려 DOR보다 낮은 성능을 보였고, LAR은 DOR과 동일한 성능을 보였다.
- Transpose traffic의 경우, DyAD와 LAR은 각각 62%, 60% 개선을 보였다.

이 결과는, 우리의 deterministic routing 방식이 adaptive routing 방식과 경쟁 가능하며, 동시에 in-order packet delivery를 보장함을 보여준다.
2.4.2 Realistic Traffic
Realistic traffic의 경우, 우리는 multiple virtual channel routing과의 호환성을 보여주기 위해 각 link에 대해 2개의 virtual channel을 고려한다. 실제 통신 시나리오로는 generic multimedia system (MMS)과 video object plane decoder (VOPD) 애플리케이션을 다룬다. MMS는 H.263 video encoder, H.263 video decoder, MP3 audio encoder, MP3 audio decoder로 구성된다. 이 애플리케이션의 통신량 요구사항은 Table 2.5에 요약되어 있다. VOPD는 MPEG-4 비디오 디코딩을 위한 애플리케이션으로, 그 communication graph는 Fig. 2.3에 나타나 있다. 다수의 연구들에서는, multimedia traffic에서의 on-chip interconnection networks에 bursty packet injection이 존재함을 보고한 바 있다.

Poisson process는 bursty traffic의 경우 적절한 모델이 아니므로, 우리는 Markov-modulated Poisson process (MMPP)를 사용하여 애플리케이션 트래픽의 bursty 특성을 모델링하였다 [5, 8]. MMPP는 temporal domain에서 트래픽 burstiness를 모델링하기 위해 널리 사용되고 있다 [8]. Fig. 2.7은 두 상태(two-state)의 MMPP 모델을 보여주며, 여기서 각 상태에서의 패킷 도착은 각각 Poisson rate λ₀, λ₁을 따른다. 상태 0에서 1로의 전이율은 r₀, 상태 1에서 0으로의 전이율은 r₁이다.

이러한 시스템에서는 core의 종류가 다양하고 요구 대역폭도 다르기 때문에, task의 배치(mapping)가 system performance에 강한 영향을 미친다. 우리는 이 애플리케이션들에 대해 적절한 매핑을 찾기 위해 design space를 단시간 내에 줄이기 위한 또 다른 최적화 문제를 수립하고, 다시 simulated annealing heuristic을 사용하여 적절한 mapping vector를 찾는다.
초기에는 task i를 node i에 매핑하고, 이후 simulated annealing을 통해 average packet latency를 최소화하려 한다. Fig. 2.8a에서, MMS 애플리케이션과 DOR 하에서 초기 mapping인 M1의 average packet latency는 87이며, 여러 번의 시도 후 mapping M4로 수렴, 그때의 latency는 41이다. 또한, simulated annealing 과정 중 발생하는 local minimum 지점인 M2와 M3의 latency 값도 함께 도식화되어 있다.

mapping 단계가 끝난 후, 우리는 이 4개의 mapping vector에 대해 LAR framework를 적용한다. Fig. 2.8a는 M1 매핑에 대해 LAR이 average packet latency를 87에서 67로 유의미하게 줄임을 보여준다. 그러나 M2, M3, M4처럼 효율적인 매핑의 경우, 개선 효과는 상대적으로 작다. 특히, 최적의 매핑(M4)의 경우 latency는 41에서 40으로만 감소한다. 이는 당연한 결과인데, mapping 문제를 푸는 과정에서 routing policy를 DOR로 고정하고 이 DOR 하에서 average latency를 최소화하도록 설계했기 때문이다. 마찬가지로, VOPD 애플리케이션의 경우에도 Fig. 2.8b에서 유사한 분석 결과를 보인다.
Fig. 2.8은 application-specific traffic pattern 하에서는, routing scheme의 성능 개선 정도가 task를 topology에 어떻게 매핑하느냐에 크게 의존함을 보여준다. 이러한 사실은 [16] 같은 관련 연구들에서는 고려되지 않았다.
오늘날의 embedded systems-on-chip에는 DSP, embedded DRAM, ASIC, generic processor 등 다양한 core들이 있으며, 이들의 물리적 위치는 고정되어 있다. 한편, 이러한 시스템은 서로 다른 workload를 가진 여러 개의 애플리케이션을 동시에 수행하고, 최근의 embedded 장치는 런타임에 사용자 애플리케이션을 설치할 수도 있으므로, design phase에서 이러한 시스템을 완전히 분석하는 것은 불가능하다.
결과적으로, 모든 애플리케이션을 고정된 routing algorithm 하에서 균일하게 load balance 하도록 mapping하는 것은 실현 불가능하며, 대신 routing phase에서 load를 balancing 해야 한다.
이 섹션에서는 LAR framework를 사용하여 mesh network 내에서 low latency 경로를 찾았다. 2D mesh topology는 구조적 단순함, 규칙성, 저비용 등의 장점 때문에 NoC 분야에서 가장 널리 사용된다. 하지만 미래에 보편화될 대형 및 3D NoC에서는, mesh 아키텍처 내의 통신이 매우 오래 걸린다. 다음 절에서는, 임의의 topology에서 deadlock-free 경로를 찾기 위해 LAR을 활용한다.
2.4.3 Find Routes in an Arbitrary Topology
LAR framework가 임의의 topology에서도 deadlock-free 경로를 찾을 수 있는 능력을 보여주기 위해, Fig. 2.9a에 나타난 topology를 고려한다. LAR은 uniform traffic pattern 하에서 해당 topology의 CDG에 두 개의 cycle이 존재함을 보고하고, turn 52–21과 87–73(Fig. 2.9b에 표시됨)을 금지함으로써(deadlock-prevention) deadlock-free 상태를 보장한다.

Table 2.6은 Fig. 2.9a에 나타난 topology의 node 0에 대한 routing table을 보여준다. 각 경로는 node 0에서 특정 목적지로 가는 경로를 채널 이름을 사용하여 지정한다.
- SE: South-East
- SW: South-West
- EJ: Ejection channel

패킷을 라우팅할 때, destination address로 routing table을 인덱싱하여 LAR이 미리 계산한 경로를 조회한다. 해당 경로는 패킷 헤더에 삽입된다.
이 network에는 총 7개의 채널이 존재하며 (E, S, NE, NW, SE, SW, EJ), 이들은 3-bit binary 값으로 인코딩할 수 있다. 또한, routing table의 크기를 줄이기 위한 기술들도 존재한다 [5, 19].
2.5 Conclusion
On-chip packet routing은 system의 성능과 전력 소비에 큰 영향을 미치기 때문에 매우 중요하다. 이는 routing 최적화의 필요성을 강하게 요구한다. 그러나 network가 제공하는 다양한 연결성과, buffer 및 link 공유에서 발생하는 간섭 때문에, minimal하고 deadlock-free한 경로를 트래픽 flow마다 찾는 것은 간단하지 않다.
이 장에서는 latency-aware routing 문제를 다루었다. 우리는 먼저 analytical model을 사용하여 평균 패킷 지연을 추정하였고, 이를 기반으로 simulated annealing heuristic을 통해 routing space를 탐색하여 deadlock-free하고 효율적인 routing 경로를 도출하였다.
이 논문(LAR framework)은 다음과 같은 과정을 수행합니다:
1. RS (Routing Space) 생성
- 모든 flow에 대해 가능한 최단 경로 집합을 생성함
2. 각 RS 조합 평가
- 각 flow마다 하나의 경로를 선택한 조합(RS의 한 인스턴스)에 대해
→ analytical model을 사용하여 전체 평균 패킷 지연 L을 계산
3. Simulated Annealing
- 다양한 RS 조합을 시도하면서 가장 L이 작은 조합을 탐색
4. 최종 경로 선택 후 Routing Table 생성
- 선택된 경로를 바탕으로
→ 각 router가 목적지 주소를 보고 어느 output port로 보낼지를 미리 정리한
→ routing table을 생성
→ 이 테이블은 run-time에 lookup만 수행
'System-on-Chip Design > NoC' 카테고리의 다른 글
| A Simple Interconnection Network (2) | 2025.06.01 |
|---|---|
| Introduction to Interconnection Networks (6) | 2025.06.01 |
| Run-time Deadlock Detection (5) | 2025.06.01 |
| Basic Concepts on On-Chip Networks (6) | 2025.05.31 |
| Design and Optimization of Networks-on-Chip (1) | 2025.05.30 |