라우팅 메커니즘은 deterministic, oblivious, adaptive 라우팅 알고리즘을 실제로 구현하는 방식을 뜻한다. 많은 라우터는 라우팅 알고리즘을 구현하기 위해 source 또는 각 홉(hop)에서 routing table을 사용한다. 목적지마다 단일 항목만 있는 테이블은 deterministic routing에만 사용할 수 있지만, 목적지마다 복수 항목을 제공하면 oblivious와 adaptive routing도 구현할 수 있다. table 기반이 아닌 대안으로는 algorithmic routing이 있으며, 이는 특수한 하드웨어가 런타임에 패킷의 경로나 다음 홉을 계산하는 방식이다. 그러나 algorithmic routing은 일반적으로 단순한 라우팅 알고리즘과 정규 토폴로지에만 제한된다.
11.1 테이블 기반 라우팅
8.3절의 Relation 8.1~8.3을 다시 떠올려 보자. 이는 모든 라우팅 알고리즘을 다음과 같이 정의한다.

이 세 가지 형태의 라우팅 관계는 모두 테이블을 통해 구현할 수 있다. 각 입력 쌍에 대한 관계 값이 테이블에 저장되며, 입력으로 테이블을 인덱싱한다. 예를 들어 첫 번째 형태에서는 각 노드 쌍마다 가능한 path 집합을 테이블에 저장하고, source와 destination 노드로 인덱싱한다. 각 노드에는 해당 노드가 source 또는 현재 노드일 때 필요한 테이블 일부만 저장하면 된다. 예를 들어 노드 x에서는 source 노드(또는 현재 노드) x에 해당하는 테이블 부분만 저장하면 된다.
테이블 기반 라우팅의 주요 장점은 일반성이다. 용량 제약만 없다면, 라우팅 테이블은 어떤 토폴로지에서든 어떤 라우팅 관계든 지원할 수 있다. 테이블 기반 라우팅을 사용하는 라우팅 칩은 테이블의 내용을 재프로그래밍하는 것만으로 다양한 토폴로지에서 사용할 수 있다.
이 절의 나머지에서는 테이블 기반 라우팅의 양 극단을 살펴본다. source-table routing에서는 전체 라우팅 경로를 source에서 한 번에 찾아 구현하고, node-table routing에서는 경로를 hop 단위로 점진적으로 찾아간다. 이 둘 사이에는 다양한 중간 형태가 존재하며, 각 테이블 조회는 경로의 일부분을 반환한다.
11.1.1 소스 라우팅 (Source Routing)
source routing은 패킷에 대한 모든 라우팅 결정을 source 터미널에서 미리 계산된 경로를 테이블 조회를 통해 완전히 수행하는 방식이다. 각 source 노드는 목적지당 하나 이상의 경로를 갖는 라우팅 테이블을 가진다. 패킷을 라우팅할 때, 목적지 정보를 이용해 해당 경로나 경로 집합을 테이블에서 조회한다. 만약 복수의 경로가 반환된다면, 추가적인 상태 정보를 통해 oblivious 또는 adaptive 방식으로 하나의 경로를 선택한다. 선택된 경로는 패킷에 붙어서 네트워크를 따라 전달되며, 중간에서의 추가 계산 없이 빠르게 패킷을 전달할 수 있다.
이 방식은 속도, 단순성, 확장성 측면에서 매우 유리하므로 deterministic 및 oblivious routing에서 널리 사용된다. 하지만 source table routing은 중간 홉의 네트워크 상태 정보를 활용할 수 없기 때문에 adaptive routing 구현에는 잘 사용되지 않는다.
다음 표는 Figure 11.1의 4 × 2 torus 네트워크에서 노드 00의 source routing table을 보여준다. 이 테이블은 네트워크 내 모든 목적지에 대해 두 개의 경로를 제공한다. 각 경로는 source 노드에서 목적지 노드까지의 경로를 포트 선택자의 문자열로 나타낸다. 이 포트 선택자는 NEWSX의 다섯 개 기호로 이루어진 알파벳에서 3비트 이진수로 인코딩되어 있다.
표 11.1: Figure 11.1의 4 × 2 torus 네트워크에서 노드 00의 source routing table
| 00 | X | X |
| 10 | EX | WWWX |
| 20 | EEX | WWX |
| 30 | WX | EEEX |
| 01 | NX | SX |
| 11 | NEX | ENX |
| 21 | NEEX | WWNX |
| 31 | NWX | WNX |
패킷이 node 00에서 node 21로 라우팅되는 예를 보자. Figure 11.1의 네트워크에서, source node는 Table 11.1을 목적지 21로 인덱싱해 미리 계산된 두 경로 NEEX와 WWNX를 찾는다. 이 중 임의로 첫 번째 경로 NEEX를 선택한다. 이 라우팅 문자열은 네트워크를 따라 패킷을 전달하기 위해 한 글자씩 해석된다. 첫 번째 문자 N은 node 00의 north 포트를 선택하고 제거되며, 나머지 문자열 EEX는 node 01로 전달된다. node 01에서는 east 포트를 선택하고 EX를 node 11로 보낸다. 다시 east 포트를 선택하고 마지막 문자 X는 node 21로 간다. X는 router의 exit 포트를 지정하며, 패킷을 node 21의 input queue로 보낸다.
source routing은 이 장의 다른 방법들에 비해 여러 가지 장점이 있다. 가장 큰 장점은 속도이다. source에서 처음 테이블을 조회하고 경로를 선택한 이후에는 라우팅에 소요되는 시간이 없다. 각 패킷이 라우터에 도착할 때 즉시 출력 포트를 선택할 수 있고, 계산이나 메모리 접근이 필요 없다. hop당 지연 중 라우팅 지연은 0이다. 또한 router 설계가 단순해진다. 각 router에 라우팅 로직이나 테이블이 필요 없다.
source routing은 토폴로지에 독립적이다. router 포트 수, source 테이블 크기, 경로의 최대 길이만 만족한다면 임의의 strongly connected 토폴지에서 라우팅이 가능하다. 예를 들어 Figure 11.1의 네트워크처럼 포트가 4개인 router들을 이용해 degree-4 네트워크를 구성하면 source routing을 통해 패킷을 전달할 수 있다.

source routing을 사용하는 router는 네트워크 크기에 구애받지 않고 사용 가능하다. 네트워크 크기, 테이블 크기, 경로 길이에 대한 제약은 source에만 있기 때문에, 큰 네트워크를 지원하는 데 드는 비용은 terminal에만 국한되며, 작은 네트워크에 그 비용이 전가되지 않는다.
임의 길이의 경로를 처리하려면 router는 임의 길이의 경로를 지원해야 한다. 경로는 exit 포트 선택자 X로 끝나는 임의 길이 문자열이지만, 이를 고정 길이의 routing phit과 flit에 적절히 인코딩해야 한다.
Figure 11.2는 임의 길이 source route를 인코딩하는 방법을 보여준다. 이 예에서는 router가 16-bit phit, 32-bit flit, 최대 13개의 포트를 지원한다고 가정한다. 각 16-bit phit에는 4개의 4-bit 포트 선택자가 들어 있고, 각 flit에는 8개의 선택자가 들어간다.

packing을 용이하게 하기 위해 P와 F라는 두 개의 새로운 포트 선택 기호를 도입한다. P는 phit 연속, F는 flit 연속을 나타낸다.
Figure 11.2(a)는 13-hop 경로 NENNWNNENNWNN이 두 개의 flit에 인코딩된 예이다. 각 phit에서는 포트 선택자를 오른쪽에서 왼쪽 순서로 해석한다. 처음에는 연속 기호가 없지만, 이후 hop이 진행되면서 순차적으로 P와 F가 삽입된다. Figure 11.2(b)에서는 첫 hop 이후 phit의 가장 왼쪽에 P가 삽입된다. Figure 11.2(c)에서는 네 번째 hop 후에 P가 오른쪽 끝에 나타나고, 이는 라우터에 해당 phit을 제거하고 flit 끝에 F를 붙이라는 명령이 된다. Figure 11.2(e)에서는 flit 연속 기호 F를 만나 flit을 제거하고 다음 flit을 처리하게 한다. 이와 같은 방식으로 exit 포트 선택자 X를 만날 때까지 처리된다. 이러한 방식으로 여러 phit과 flit에 걸쳐 임의 길이의 경로를 인코딩할 수 있다.
이 연속 선택자 덕분에 router는 단일 phit만 처리하면 되며, 각 단계의 leading phit 입력만으로 출력을 결정할 수 있으므로 다음 phit이 도착하기 전에 출력을 생성하고 전송할 수 있다.

source terminal의 라우팅 테이블은 임의 길이의 문자열을 효율적으로 저장할 수 있도록 설계되어야 한다. Figure 11.3처럼 단일 간접화(indirection) 레벨을 사용해 이를 구현할 수 있다. 테이블을 목적지로 인덱싱하면 하나 이상의 포인터가 반환되며, 각 포인터는 가변 길이의 경로 문자열을 가리킨다. 모든 경로는 X로 끝나며, 한 경로가 다른 경로의 접미사인 경우, 첫 경로의 문자열 내부를 가리키는 포인터로 나타낼 수 있어 저장 공간이 절약된다. 이러한 방식은 경로를 조회할 때 추가 메모리 접근이 필요하지만, 가장 짧은 경로를 제외한 경우에는 경로를 고정 길이로 만드는 데 드는 낭비를 줄이므로 전체적으로 더 효율적이다. 절충안으로는 경로의 처음 몇 hop을 테이블에 직접 저장하고 나머지 경로에 대한 포인터를 포함하는 방식이 있다.
source routing 테이블은 각 목적지에 대해 여러 개의 경로를 저장할 수 있다. Table 11.1에서도 각 목적지에 두 개의 경로를 저장하고 있다. 이처럼 한 쌍의 source-destination 사이에 복수 경로를 제공하는 것은 여러 이점을 갖는다.
- Fault tolerance: 일부 경로가 edge-disjoint라면, 노드 간 연결 채널이 하나 이상 고장 나더라도 경로가 유지된다.
- Load balance: 여러 경로를 통해 트래픽이 분산되므로 다양한 트래픽 패턴에서도 네트워크의 부하가 고르게 유지된다.
- Distribution: 테이블 인덱싱에 사용되는 목적지가 특정 서버가 아닌 서비스 같은 논리적 목적지인 경우, 여러 경로는 여러 서버로 연결될 수 있다. 이 경우 라우팅 테이블은 특정 서비스를 제공하는 서버 간에 트래픽을 분산하는 역할을 한다.
여러 개의 경로가 있을 때는 각 패킷이 어떤 경로를 따라야 할지 결정해야 한다. 패킷 순서를 보장할 필요가 없다면, 의사 난수 생성기를 사용해 트래픽을 무작위로 분산시키는 방식이 효과적이다. 경로와 테이블 항목 수가 동일하고 난수가 균등하게 분포한다면, 모든 경로는 동일한 확률로 선택된다. 일반적으로는 경로 수가 목적지마다 다르고, 테이블에 고정 개수의 항목만 존재하므로 1:1 매핑은 어렵다. 대신 테이블 항목 수를 충분히 늘리면 부하 균형을 근사할 수 있다. 예를 들어 M개의 경로에 대해 N개의 테이블 항목이 있다면, 각 경로는 k 또는 k+1개의 항목에 저장되며, 두 경로 간의 부하 차이는 1/N으로 제한된다.
또 다른 방법은 각 경로에 확률값을 이진 필드로 저장하는 것이다. 로직 회로는 이 확률과 난수를 결합해 경로를 선택할 수 있다. 이 방식은 임의의 확률 분포를 표현할 수 있고, 테이블 항목을 중복 저장하는 것보다 훨씬 더 저장 공간 효율적이다.
경우에 따라 네트워크를 통해 전송되는 특정 패킷들의 순서를 보장해야 할 수도 있다. 프로토콜이 재정렬 기능이 없거나, 예를 들어 cache coherence protocol처럼 메시지 순서가 정확성에 영향을 미치는 경우, 순서를 유지해야 한다. 이러한 패킷 집합은 flow라고 하며, 각 패킷은 flow 식별자(flow identifier)로 라벨링된다. 이는 프로토콜과 패킷 종류를 식별하는 header 필드 조합일 수 있다. flow 식별자를 해싱해서 경로 선택자 생성에 사용하면, 해당 flow의 모든 패킷이 동일한 경로를 따라가므로 (FIFO queueing을 가정할 때) 순서가 유지된다. 그러나 flow 분포가 고르지 않으면 경로 선택 확률이 왜곡될 수 있다. Avici TSR의 randomized table-based routing에서 flow 순서를 유지하는 방식은 9.5절에 설명되어 있다.
11.1.2 Node-Table Routing
table-based routing은 라우팅 테이블을 terminal이 아닌 라우팅 노드에 저장하는 방식으로도 구현할 수 있다. node-table routing은 각 단계에서 사용할 수 있는 여러 다음 홉 중 하나를 네트워크 상태에 따라 선택할 수 있으므로 adaptive routing에 더 적합하다. node table을 사용하면 각 노드는 목적지까지 전체 경로가 아니라 다음 홉 정보만 저장하면 되므로 라우팅 테이블 전체 저장 공간을 크게 줄일 수 있다. 하지만 저장 공간이 줄어드는 대신, 성능 저하와 라우팅 제한이라는 단점이 있다. 이 구조에서는 패킷이 라우터에 도착할 때마다 테이블 조회를 수행해야 출력 포트를 결정할 수 있다.
패킷이 라우터에 도착했을 때 목적지 외에도 도착한 input 포트를 기준으로 테이블 항목을 선택하는 방식도 가능하다. source routing과 달리 경로의 각 단계마다 테이블을 조회해야 하므로, 라우터를 통과하는 패킷의 지연 시간이 상당히 증가한다. 또한, 모든 노드가 가장 큰 네트워크에서 모든 목적지에 대한 다음 홉 정보를 저장할 수 있어야 하므로 확장성도 희생된다. 더불어, 이 방식에서는 서로 다른 source 노드 x와 y에서 같은 목적지 z로 향하는 패킷이 동일한 중간 노드 w의 같은 채널로 들어온 경우, w → z 구간에서 서로 다른 경로를 주는 것이 불가능하다. source routing에서는 이게 쉽게 가능하다.

Table 11.2는 Figure 11.1 네트워크에 대한 node routing table의 예시를 보여준다. 각 노드에 대한 테이블이 노드 번호 아래 두 개의 열로 나타나 있으며, 각 목적지마다 한 행이 있다. 각 노드와 목적지 쌍에 대해 두 개의 가능한 다음 홉이 주어져 있어, 일정 수준의 adaptive routing이 가능하다. 예를 들어, node 01에서 node 13으로 향하는 패킷은 N 또는 E 방향 중 하나를 선택할 수 있다. 일부 다음 홉은 실제로는 목적지로부터 멀어지는 방향이며, 이러한 misroute는 굵게 표시되어 있다.
node-table routing에서는 livelock 문제가 발생할 수 있다. 테이블 항목이 패킷을 무한 루프로 보내는 방향으로 설정될 수 있기 때문이다. 예를 들어, node 00에서 node 11로 가는 항목이 N 방향이고, node 10에서 node 11로 가는 항목이 S 방향이라면, 패킷은 00 ↔ 10 사이를 무한히 순환하게 된다. 반면, source routing은 고정된 길이의 경로를 가지므로 반드시 도착지에 도달하게 되며 이런 문제가 없다. node-table routing에서도 테이블을 신중하게 구성하면 이러한 문제를 피할 수 있다.
node-table routing은 로컬에서 경로를 조정할 수 있다는 장점이 있다. 특정 output 링크가 혼잡하거나 고장났을 때, 다른 노드와 협의 없이도 노드 스스로 경로를 변경할 수 있다. Table 11.2처럼 각 목적지에 대해 여러 엔트리가 있으면, 혼잡도나 사용 가능성을 기준으로 출력 포트 선택에 bias를 줄 수 있다. 예를 들어, Table 11.2에서 node 00의 N 포트가 혼잡하면, 목적지 10인 패킷은 다음 홉으로 N이 아닌 S를 선택할 수 있다.
매우 큰 네트워크에서는 저장 공간을 줄이기 위해 node-table을 계층적(hierarchical)으로 구성할 수 있다. 예를 들어, 가까운 노드는 개별적으로 다음 홉을 저장하고, 멀리 있는 노드는 그룹으로 묶어서 저장하는 식이다. 이런 방식의 한 예로는 CAM(Content Addressable Memory)을 라우팅 테이블로 사용하는 것이다. Table 11.3은 8-ary 3-cube 네트워크에서 node 4448의 CAM 기반 라우팅 테이블 예시이다. 각 행은 목적지 그룹과 해당 그룹에 대한 다음 홉으로 구성되며, 9비트 주소(x, y, z 각 3비트)로 표현된 목적지 그룹은 일부 비트에 “X”(don’t care)를 포함할 수 있다. “X”를 허용하는 CAM은 ternary CAM(TCAM)이라 부른다.

X의 수에 따라 이 주소는 단일 노드, 1D, 2D, 3D로 연속된 노드 그룹을 인코딩할 수 있다. 예를 들어 첫 번째 행은 node 444 자체를 나타내며, 다음 행은 서쪽에 있는 1D 노드 배열(440443)을 나타낸다. 마지막 항목은 2D 노드 배열(500577)을 나타내며, 나머지 항목은 3D 노드 그룹을 표현한다.
CAM 기반 라우팅 테이블은 마치 출력 포트를 선택하는 논리함수를 계산하는 프로그램 가능 로직 배열(PLA)처럼 작동한다. 특정 포트를 선택하는 각 항목은 논리식에서 해당 포트를 위한 항(term) 하나로 작용한다. 예를 들어, W 포트를 선택하는 논리식은 두 번째와 여덟 번째 행에 대응하는 두 항(term)으로 구성된다. 이런 방식으로 하나의 포트에 대한 모든 항목을 최소한의 합-곱식으로 압축하면 node routing table을 줄일 수 있다.
node-table routing은 대부분의 광역 패킷 라우터에서 사용하는 방식이다. 이는 네트워크 연결성과 라우팅을 분산 알고리즘으로 계산하는 데 적합하기 때문이다. 하지만 interconnection network처럼 노드가 가까이 위치한 시스템에서는, delay가 증가하므로 adaptivity가 필요한 경우가 아니면 source routing이 보통 더 우수하다.
source routing과 node-table routing은 table-based routing의 두 극단을 나타낸다. node-table routing은 다음 홉만 저장하고, source routing은 전체 경로를 저장한다. 물론 이 두 극단 사이에는 다양한 중간 지점이 있을 수 있으며, 테이블에 다음 M개 (M > 1)의 홉을 저장하는 방식도 있다. 이 방식은 지역적인 adaptivity와 중간 수준의 hop latency를 제공하지만, 실제로는 거의 사용되지 않는다. hybrid 방식에서는 노드마다 다른 동작을 해야 하므로 대칭성이 없기 때문이다.
11.2 알고리즘 기반 라우팅 (Algorithmic Routing)
라우팅 관계를 테이블에 저장하는 대신, 알고리즘을 이용해 계산할 수 있다. 속도를 위해 이 알고리즘은 보통 조합 논리 회로로 구현된다. 이런 알고리즘 기반 라우팅은 테이블 기반 라우팅의 일반성은 희생하지만, 특정 토폴로지와 그에 맞는 라우팅 전략에 최적화될 수 있다. 대신, 면적과 속도 측면에서 더 효율적일 수 있다.
가장 단순한 예는 목적지 주소의 특정 자릿수를 추출하는 digit selector이며, 이는 destination-tag routing에서 사용된다. 예를 들어 Section 2.5의 간단한 라우터에서는 이러한 회로가 사용된다.

2D torus 라우팅용 알고리즘 회로는 Figure 11.4에 나와 있다. 이 회로는 sx, sy라는 각 차원에 대한 부호 비트와 목적지까지 몇 hop 남았는지를 나타내는 상대 좌표 x, y를 입력으로 받는다. 상대 주소는 zero checker에 전달되어 xdone, ydone 신호를 생성한다. 이 신호들은 각 차원에서 라우팅이 완료되었는지를 나타낸다. 부호 비트와 done 신호는 다섯 개의 AND 게이트에 입력되며, 목적지로 가까워지는 생산적인 방향(productive direction)을 결정한다. 예를 들어, xdone=0이고 sx=0이면 +x 방향으로 진행 중이며, 이는 생산적인 방향이 된다.
이처럼 생성된 5비트 생산적 방향 벡터는 route selection 블록에 전달되어 하나의 방향을 선택하고, 그 선택된 방향 벡터가 출력된다.
route selection 블록은 이 회로가 수행하는 라우팅 방식의 종류를 결정한다. productive direction 벡터에서 하나를 무작위로 선택하면 minimal oblivious router가 되며, 출력 큐의 길이를 기준으로 선택하면 minimal adaptive router가 된다. 모든 생산적인 방향의 큐 길이가 특정 임계값을 초과하면 비생산적인 방향도 선택할 수 있게 하면 fully adaptive router가 된다.
Figure 11.5는 512-프로세서 IBM SP2 시스템을 보여준다. 각 캐비닛(또는 frame)은 16개의 RS6000 워크스테이션과 하나의 32포트 스위치 보드를 포함하고 있다.

tag 라인은 유효한 flit을 식별하며, token 라인은 반대 방향으로 동작하여 송신 노드에 credit을 반환한다(흐름 제어를 위함). 스위치를 통과하는 지연 시간은 20ns 사이클 5개다.

Figure 11.6에 보이듯, 8개의 switch 칩이 2단계 양방향 네트워크로 구성된 32포트 스위치 모듈에 배열된다. 이 모듈은 양쪽 측면에서 각각 16개의 양방향 채널을 제공한다. 스위치 모듈 밖으로 나가는 모든 채널은 differential ECL 신호로 전달된다. SP 시스템의 가장 하위 단계에서는 16개의 프로세서 모듈이 하나의 스위치 모듈의 한 쪽 16포트에 연결된다. 이 17개의 모듈은 하나의 캐비닛(frame)에 통합되어 구성된다.

16개 이상의 프로세서를 가진 SP 시스템은 여러 frame과 switch module로 구성된다. 최대 80프로세서(5 frame)까지는 Figure 11.7처럼 frame들을 직접 연결하여 구성할 수 있다. 더 큰 시스템은 frame을 folded Clos 네트워크의 첫 두 단계로 사용하고, 16×16 중간단계와 32포트 최종단계를 제공하기 위해 switch module을 사용한다. 예를 들어, Figure 11.8은 32개의 frame과 16개의 추가 switch module로 512프로세서 시스템을 구성하는 방식을 보여준다. 8K 프로세서 시스템까지는 두 단계의 switch module을 이용해 구축할 수 있다.

※ 각 switch module은 fault tolerance를 위해 동일한 32포트 switching 구조를 2세트 보유한다(총 16개의 switch chip). 한 세트는 실제 switching을 수행하고, 다른 하나는 이를 shadow하여 오류를 감지한다.
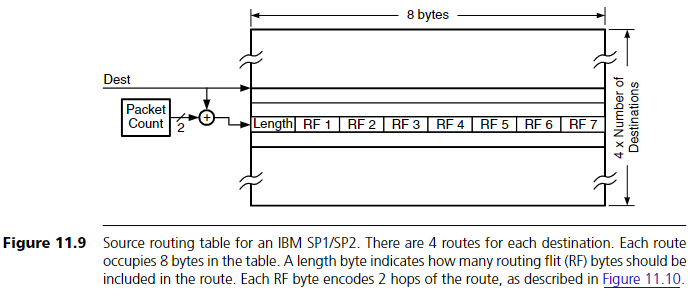
각 노드는 Section 11.1.1에서 설명한 source routing table을 포함한다. 이 테이블은 각 목적지마다 4개의 경로를 저장하고 있다. Figure 11.9에서 보듯, 패킷이 라우팅을 위해 도착하면, 목적지와 함께 2비트 packet counter 값을 이용해 테이블을 인덱싱한다. packet counter는 매번 패킷이 생성될 때 증가한다. 8바이트의 route descriptor가 테이블에서 읽혀지는데, 그 중 첫 바이트는 이 descriptor에서 유효한 라우팅 flit의 개수 N(0~7)을 나타낸다.
이후 N개의 바이트는 각각 1~2 hop을 인코딩하는 routing flit이며, 최대 길이의 route descriptor는 최대 14 hop을 인코딩하는 7개의 flit을 포함할 수 있다. 이 routing flit들은 라우팅 시 사용되기 위해 패킷 앞에 붙는다.

Figure 11.10은 SP 패킷 형식을 보여준다. 패킷은 초기의 length flit 다음에 하나 이상의 routing flit과 payload data flit을 포함한다. 각 라우터는 첫 routing flit을 검사한다. selector bit인 S가 0이면, upper hop 필드(bits 4–6)를 사용해 출력 포트를 선택하고, S를 1로 설정한다. S가 1이면, lower hop 필드(bits 0–2)를 사용하고 해당 flit은 폐기되며 length는 감소한다. 기본적으로 S는 0으로 시작하지만, 경로가 홀수 개의 hop으로 구성된 경우, 마지막 routing flit의 S bit는 1로 초기 설정되어야 한다. SP 패킷은 source에서 정해진 경로를 따라 이동하며, 2 hop마다 하나의 routing flit을 소비한다. 목적지에 도달하면 routing flit은 모두 소모되어 length flit과 data flit만 남는다. 각 routing flit이 소모될 때마다 length flit이 감소하므로, 어느 시점에서든 패킷의 현재 길이를 나타낸다.
라우팅 테이블은 네트워크 링크 간의 부하를 균형 있게 분산하고, edge-disjoint 경로를 제공하도록 구성된다. 각 노드에 대해 첫 번째 목적지 경로는 네트워크에 대해 최소 신장 트리를 구성함으로써 결정된다. 초기에는 각 edge에 단위 가중치를 부여하고, 경로에 사용될 때마다 edge 가중치에 작은 값 ε를 더하여 가중치를 증가시킨다. 이후 업데이트된 edge 가중치를 기준으로 새로운 최소 신장 트리를 생성하고, 이를 기반으로 두 번째 경로를 생성한다. 이 과정을 반복하여 세 번째 및 네 번째 경로를 생성한다.
IBM SP 네트워크는 CM-5(Section 10.6) 및 Avici TSR(Section 9.5)의 네트워크와 비교해볼 만하다. SP 네트워크는 large configuration에서 CM-5와 거의 동일한 토폴로지를 갖고 있으며, 둘 다 8×8 포트 switch를 이용한 folded Clos 구조를 사용한다. 주요 차이는 SP 네트워크에는 concentration이 없고, CM-5는 4배 concentration이 존재한다는 점이다. 하지만 동일한 토폴로지를 사용하더라도 라우팅 방식은 매우 다르다. CM-5는 상향 링크에서 adaptive routing을 사용해 동적으로 부하를 분산시키는 반면, SP 네트워크는 oblivious하게 라우팅한다.
CM-5와 SP는 동일한 토폴로지를 갖고 라우팅 방식에서 차이를 보이는 반면, TSR과 SP는 매우 유사한 라우팅 방식을 갖지만 적용되는 토폴로지는 매우 다르다. TSR과 SP 모두 각 목적지에 대해 여러 개의 대체 경로를 source 테이블에 저장하는 oblivious source routing 방식을 사용한다. SP는 각 목적지마다 4개의 경로를, TSR은 24개의 경로를 유지한다. SP는 packet counter를 이용해 라우트를 선택하고, TSR은 flow identifier를 해싱하여 라우트를 선택한다. 이 방식은 관련된 패킷이 동일한 경로를 따라가도록 하여 순서를 유지하게 한다. 두 시스템 모두 라우팅 테이블의 대체 경로들을 네트워크 채널에 부하를 statically 분산되도록 구성한다. 이처럼 oblivious source routing 기법은 불규칙한 3D torus부터 folded Clos 네트워크까지 매우 다른 토폴로지에 적용 가능하며, 이는 source routing의 토폴로지 독립성이라는 큰 장점을 보여준다.
11.4 참고 문헌 노트
table-based routing은 유연성과 단순성 덕분에 실제 구현에서 인기가 많다. Section 11.3에서 언급했듯이 IBM SP1과 SP2 네트워크는 source routing table을 사용하며, Avici TSR도 마찬가지다. 그러나 네트워크 규모가 커질수록 source table의 크기는 부담이 된다. 그래서 SGI Spider, InfiniBand, 인터넷 같은 많은 네트워크는 node-table 방식을 채택한다. 많은 node-table 구현에서는 McQuillan이 도입하고 Kleinrock과 Kamoun이 자세히 분석한 hierarchical routing을 사용하여 테이블 크기를 줄인다. SGI Spider에서 사용된 hierarchical routing 메커니즘은 Exercise 11.4에서 다루어진다. 테이블 크기를 줄이는 또 다른 접근은 interval routing이다(Exercise 11.5 참고). 이는 Santoaro와 Khatib이 개발하고 van Leeuwen과 Tan이 확장하였으며 INMOS Transputer에서 구현되었다. CAM은 routing table 구현에서 일반적으로 사용되며, Pei와 Zukowski, McAuley와 Francis의 연구에서 설명되어 있다. Fredkin이 도입한 trie 구조도 특히 IP 라우터에서 routing table로 많이 사용된다. Pei와 Zukowski는 hardware에서의 trie 설계를, Doeringer 등은 IP lookup에 적합하도록 trie를 확장한 내용을 설명하였다.
11.5 연습문제
11.1 Source route 압축
본 장에서 제시된 source route에서는 각 포트 선택자 기호(N, S, E, W, X)를 3비트로 인코딩했다. source route 표현 시 평균 비트 수를 줄이기 위한 대체 인코딩 방법을 제안하라. torus에서 흔히 나타날 수 있는 "일반적인" 경로를 고려하여 인코딩 방식을 정당화하라. 또한 다음 경로들에 대해 기존 3비트 인코딩과 제안한 인코딩을 비교하라.
(a) NNNNNEEEX
(b) WNEENWWWWWNX
(c) SSEESSX
11.2 CAM 기반 routing table
8-ary 2-cube 토폴로지에서 node 34의 node-table을 고려하라. 이를 RAM에 저장할 경우 몇 개의 테이블 항목이 필요한가? CAM을 사용할 경우 얼마나 줄일 수 있는가? CAM에 필요한 항목들을 나열하라.
11.3 Minimal adaptive 경로 선택 논리
Figure 11.4에 제시된 route selection block에 대해 minimal adaptive routing을 구현하기 위한 논리를 설계하라. downstream 큐 길이가 가장 짧은 productive 경로를 선택하는 논리를 구상하라.
11.4 SGI Spider에서의 hierarchical routing
SGI Spider는 meta-table과 local table이라는 두 레벨의 hierarchical node-table을 사용한다. 네트워크 내 각 노드의 ID는 meta address(상위 비트)와 local address(하위 비트)로 나뉜다. 패킷이 next hop을 계산할 때, 먼저 meta address가 현재 노드와 일치하는지를 확인한다. 다르면 목적지의 meta address를 사용해 meta-table에서 next hop을 찾고, 같으면 local address를 사용해 local table에서 next hop을 찾는다. 개념적으로 meta address는 패킷을 해당 "영역(region)"으로 이동시키며, local address는 정확한 목적지까지 보낸다. 이 방식에서 node ID 중 2비트를 meta address로 사용할 경우, 2D torus 네트워크의 routing table 크기는 얼마나 작아질 수 있을까?
11.5 mesh 네트워크에서의 linear interval routing
interval routing은 각 노드의 outgoing edge에 중복되지 않는 구간(interval)을 할당함으로써 routing table 크기를 줄이는 방식이다. Figure 11.11은 linear interval labeling의 예시를 보여준다. 각 채널은 [x, y] 구간을 갖고, 목적지 d가 x ≤ d ≤ y를 만족하면 해당 채널을 통해 전송된다. 예를 들어, node 3에서 node 1로 가는 경우, node 3의 west 채널이 해당 구간을 포함하므로 west로 보낸다. 이어서 node 1에서 목적지인 node 0으로 이동한다. 4×4 mesh 네트워크에 대해 linear interval labeling을 구성하라. (목적지 노드 번호는 0~15로 부여)
11.6 IBM SP2를 위한 경로 생성
512-node IBM SP2 네트워크에서 spanning tree를 계산하는 프로그램을 작성하라. 이 트리를 이용해 각 목적지당 4개의 경로를 포함한 routing table을 생성하라.
11.7 Spanning tree 경로의 부하 균형
Exercise 11.6에서 생성한 routing table을 사용해 무작위 permutation을 여러 번 수행한 후, 채널 부하를 계산하라. 부하가 얼마나 균형적으로 분산되는가?
11.8 IBM SP 네트워크에서의 adaptive routing
SP 네트워크의 후속 버전은 상향 링크에서는 CM-5와 같은 adaptive source routing을 사용하고, 하향 링크에서는 source routing을 사용하였다. 이 방식이 어떻게 작동할 수 있을지 설명하라. SP 네트워크 구조 내에서 이 방식이 동작할 수 있도록 경로 인코딩 방식을 개발하라.
11.9 시뮬레이션
CM-5 스타일의 adaptive routing과 IBM SP 스타일의 oblivious routing을 512-node SP 네트워크에서 비교 시뮬레이션하라.
'System-on-Chip Design > NoC' 카테고리의 다른 글
| Buffered Flow Control (1) | 2025.06.05 |
|---|---|
| Flow Control Basics (2) | 2025.06.02 |
| Adaptive Routing (1) | 2025.06.02 |
| Oblivious Routing (3) | 2025.06.02 |
| Routing Basics (1) | 2025.06.02 |