라우터는 register, switch, function unit, control logic으로 구성되며, 목적지로 향하는 flit을 버퍼링하고 전달하는 데 필요한 라우팅 및 흐름 제어 기능을 함께 구현한다. 다양한 라우터 구성 방식이 있지만, 이 장에서는 일반적인 virtual-channel router의 아키텍처를 살펴보고 라우터 설계에서 고려되는 주요 이슈와 트레이드오프에 대해 논의한다.
현대 라우터는 flit 단위로 파이프라인화되어 있다. head flit은 라우팅과 virtual channel 할당을 수행하는 파이프라인 단계를 거치고, 모든 flit은 switch 할당 및 switch traversal 단계를 거친다. 특정 파이프라인 단계가 현재 사이클에서 완료되지 않으면 pipeline stall이 발생한다. 이 경우 flit의 순서를 유지해야 하므로 해당 stall 이전의 모든 파이프라인 단계의 동작이 중단된다.
대부분의 라우터는 buffer 공간을 할당하기 위해 credit 방식을 사용한다. flit이 채널을 따라 downstream으로 이동하면서, upstream 방향으로는 방금 비워진 버퍼에 접근할 수 있도록 credit이 전달된다. 버퍼 수가 제한된 라우터에서는 credit 처리 지연이 성능에 큰 영향을 줄 수 있다. 또한 credit은 deadlock 속성에도 영향을 미친다. 모든 credit이 반환되기 전에 virtual channel이 할당되면, 현재 채널을 할당받은 패킷과 downstream 버퍼에 아직 남아있는 다른 패킷 사이에 의존성이 생긴다.
16.1 기본 라우터 아키텍처
16.1.1 블록 다이어그램
그림 16.1은 일반적인 virtual-channel router의 블록 다이어그램을 보여준다. 이 블록들은 기능에 따라 datapath와 control plane의 두 그룹으로 구분할 수 있다. datapath는 패킷의 payload 저장 및 이동을 처리하며, 입력 버퍼 집합, 스위치, 출력 버퍼 집합으로 구성된다.

control plane은 datapath 자원 내에서 패킷의 이동을 조정하는 역할을 하며, 라우터에서는 route computation, virtual-channel allocation, switch allocation을 수행한다. 입력 버퍼에는 입력 제어 상태가 포함되어 input unit을 구성하며, 출력도 마찬가지 방식이다.
각 패킷의 flit은 라우터의 input unit에 도착한다. input unit은 도착한 flit을 저장하기 위한 flit buffer와 해당 입력 링크에 연결된 각 virtual channel의 상태를 유지한다. 일반적으로 각 virtual channel의 상태는 Table 16.1에 제시된 다섯 개의 필드로 구성된다.
패킷 전송을 시작하려면 우선 route computation을 수행해 어떤 출력 포트로 보낼지 결정해야 한다. 출력 포트가 정해지면, virtual-channel allocator에게 출력 virtual channel을 요청한다. 라우팅과 virtual channel 할당이 완료되면, switch allocator가 switch와 출력 채널에 대해 시간 슬롯을 할당해 flit을 해당 출력 unit으로 전송한다. 마지막으로, 출력 unit은 flit을 다음 라우터로 전달한다. 입력 unit과 마찬가지로, 출력 virtual channel 상태도 Table 16.2에 제시된 여러 상태 필드를 포함한다.
라우터의 제어는 packet 단위와 flit 단위라는 두 가지 다른 주기로 동작한다. route computation과 virtual-channel allocation은 packet당 한 번 수행되며, 이에 따라 virtual channel의 R, O, I 필드가 한 번만 갱신된다. 반면 switch allocation은 flit마다 수행되므로, P와 C 필드는 flit 주기로 갱신된다.
Table 16.1: 입력 virtual channel 상태 필드 (5-vector: GROPC)
| G (Global state) | idle (I), routing (R), output VC 대기 중 (V), active (A), credit 대기 중 (C) 중 하나의 상태 |
| R (Route) | 라우팅 완료 후 선택된 출력 포트 |
| O (Output VC) | virtual-channel 할당 완료 후 패킷에 할당된 출력 포트 R의 virtual channel |
| P (Pointers) | 해당 virtual channel의 head와 tail flit이 위치한 input buffer 포인터 |
| C (Credit count) | 출력 포트 R의 virtual channel O에서 사용 가능한 downstream flit buffer 수 |
Table 16.2: 출력 virtual channel 상태 필드 (3-vector: GIC)
| G (Global state) | idle (I), active (A), credit 대기 중 (C) 중 하나의 상태 |
| I (Input VC) | 현재 이 출력 virtual channel로 flit을 전송하는 입력 포트 및 virtual channel 정보 |
| C (Credit count) | downstream 노드에서 이 virtual channel이 사용할 수 있는 빈 버퍼 수 |
16.1.2 라우터 파이프라인
그림 16.2는 일반적인 virtual-channel router의 파이프라인 동작을 Gantt 차트 형식으로 보여준다. 각 head flit은 라우팅 계산(RC), virtual channel 할당(VA), switch 할당(SA), switch 전송(ST)의 단계를 거쳐야 한다. 그림에서는 각 단계가 1 클럭 사이클씩 걸리는 파이프라인을 나타낸다. 도표에서는 stall 없이 패킷이 각 파이프라인 단계를 통과하는 이상적인 상황을 보여준다. 실제로는 어느 단계에서든 stall이 발생할 수 있다.

라우팅 과정은 head flit이 cycle 0에 라우터에 도착하면서 시작된다. 이때 flit의 헤더에는 도착한 입력 포트의 virtual channel 정보가 포함되어 있다. 이 virtual channel의 초기 global 상태(G)는 idle이다. head flit의 도착으로 인해 cycle 1 시작 시 해당 virtual channel은 routing 상태(G = R)로 전이된다.
cycle 1 동안 head flit의 정보를 이용해 라우터 블록은 출력 포트를 선택한다. 이 결과는 virtual channel 상태의 route 필드(R)에 반영되며, virtual channel 상태는 cycle 2 시작 시 output VC 대기 상태(G = V)로 전이된다. 이와 동시에 첫 번째 body flit이 라우터에 도착한다.
cycle 2에서는 head flit이 VA 단계로 진입하고, 첫 번째 body flit은 RC 단계를 통과하며, 두 번째 body flit이 도착한다. VA 단계에서는 R 필드의 값을 이용해 출력 포트를 지정하고, 해당 포트에서 사용할 수 있는 output virtual channel을 할당받는다. VA 결과는 virtual channel 상태의 O 필드에 반영된다.
그림 16.2에서 보는 바와 같이 RC와 VA는 head flit에만 적용되며, SA와 ST는 모든 flit에 대해 적용된다. stall이 없는 경우 각 flit은 앞선 flit보다 한 사이클씩 늦게 파이프라인에 진입하고 각 단계마다 한 사이클씩 진행된다.
virtual-channel allocator가 성공적으로 할당되면, 해당 입력 virtual channel의 상태는 active(G = A)로 전환된다. 동시에 할당된 출력 virtual channel의 상태 벡터도 active(G = A)로 설정되며, 해당 입력 virtual channel을 식별하기 위해 출력 virtual channel의 입력 필드(I)가 업데이트된다. tail flit이 채널을 해제할 때까지, 출력 virtual channel의 credit(C) 필드는 입력 virtual channel의 C 필드와 동일한 값을 유지한다.
deadlock 분석 관점에서 보면, VA 단계에서 입력 virtual channel에서 출력 virtual channel로의 의존성이 생긴다. 하나의 출력 virtual channel이 패킷에 할당되면, 해당 패킷이 전부 다음 노드의 출력 virtual channel buffer로 이동할 때까지 입력 virtual channel은 해제되지 않는다.
cycle 3이 시작되면 패킷 단위의 모든 제어 처리는 완료되고, 그 이후로는 flit 단위의 switch allocation(SA) 처리만 남는다. 이 시점에서 head flit이 시작하지만 다른 flit들과 동일하게 처리된다. 이 단계에서는, 활성 상태(G = A)이고 buffer에 flit이 있으며(P), downstream buffer가 비어 있는(C > 0) 모든 virtual channel이 switch를 통해 출력 unit으로 flit을 전송하기 위한 시간 슬롯을 요청한다. switch 구성에 따라, 이 할당은 switch의 출력 포트뿐 아니라 동일한 입력 unit 내 다른 virtual channel들과 입력 포트에 대해서도 경합할 수 있다. switch 할당 요청이 성공하면, 입력 버퍼의 포인터 필드(P)가 갱신되고, 해당 flit이 차지했던 buffer가 해제되었음을 반영해 credit count가 감소되며, 이전 라우터로 credit이 전송된다.
그림 16.2에서 cycle 3에 switch allocation이 성공하고, cycle 4에 head flit이 switch를 통과(ST)한다. switch가 비어 있는 상황이라면, cycle 5에 다음 라우터로 flit을 전송할 수 있다.
head flit이 virtual channel 할당을 받고 있는 동안 첫 번째 body flit은 RC 단계에 있으며, head flit이 SA 단계에 있을 때 첫 번째 body flit은 VA 단계, 두 번째 body flit은 RC 단계에 있다. 하지만 routing과 virtual-channel allocation은 패킷 단위로 처리되므로, body flit은 해당 단계에서 수행할 작업이 없다. body flit은 해당 단계를 우회할 수 없고 순서를 유지해야 하므로, SA 단계에 도달할 때까지 input buffer에 저장되어야 한다. stall이 없다면, 파이프라인에 동시에 세 개의 body flit이 존재하므로 최소 세 개의 입력 buffer 위치가 필요하다. 이후 credit stall을 방지하기 위해 더 큰 buffer가 필요함을 설명할 것이다.
각 body flit이 SA 단계에 도달하면 head flit과 동일하게 switch 시간 슬롯을 요청한다. 이 처리 과정은 flit 단위로 수행되며, head flit과 동일하게 취급된다. 각 flit에 대해 switch 슬롯이 할당되면 virtual channel의 P와 C 필드가 갱신되고 credit이 생성되어 이전 라우터로 전달된다.
마지막으로 cycle 6에서는 tail flit이 SA 단계에 도달한다. tail flit의 switch 할당도 head 및 body flit과 동일하게 처리된다. cycle 6에서 tail flit의 할당이 성공하면, cycle 7 시작 시 해당 virtual channel은 해제되며 출력 virtual channel 상태와 입력 virtual channel 상태는 idle(G = I)로 전환된다. 단, 입력 버퍼가 비어 있지 않다면 다음 패킷의 head flit이 이미 대기 중일 수 있으며, 이 경우 상태는 바로 routing(G = R)으로 전환된다.
16.2 Stall
앞서 설명에서는 flit과 packet이 파이프라인을 따라 지연 없이 진행된다는 이상적인 상황을 가정했다. 즉, 할당은 항상 성공하고 채널, flit, credit이 필요할 때 항상 사용 가능하다고 가정했다. 이 절에서는 이상적인 동작을 방해하는 6가지 stall 사례를 Table 16.3을 기준으로 설명한다.
처음 세 가지는 packet stall로, 라우터의 packet 처리 단계에서 발생한다. 이들은 virtual channel이 R, V, A 상태로 진입하지 못하게 한다. 반면 virtual channel이 active(A) 상태에 들어간 후에는 packet 처리가 완료되었으며, 이후에는 flit stall만 발생할 수 있다. flit stall은 switch allocation이 실패하여 flit이 진행하지 못하는 경우로, 그 원인은 flit 없음, credit 없음, switch 슬롯 경쟁 실패 등이 있다.
Table 16.3: 라우터 파이프라인 stall의 종류
| VC Busy | P | ¬I | 연속된 packet으로 인해 발생. 이전 패킷의 tail flit이 switch allocation을 마치기 전 다음 packet의 head flit이 도착해 buffer에 대기함 |
| Route | P | R | 라우팅 실패로 R 상태에서 재시도 필요 |
| VC Allocation | P | V | VA 실패로 V 상태에서 재시도 필요 |
| Credit | F | A | credit 없음. downstream에서 credit이 도착해야 진행 가능 |
| Buffer Empty | F | A | flit 없음. upstream에서 stall 발생 가능성 |
| Switch | F | A | switch 할당 실패. 다음 사이클에 재시도 |
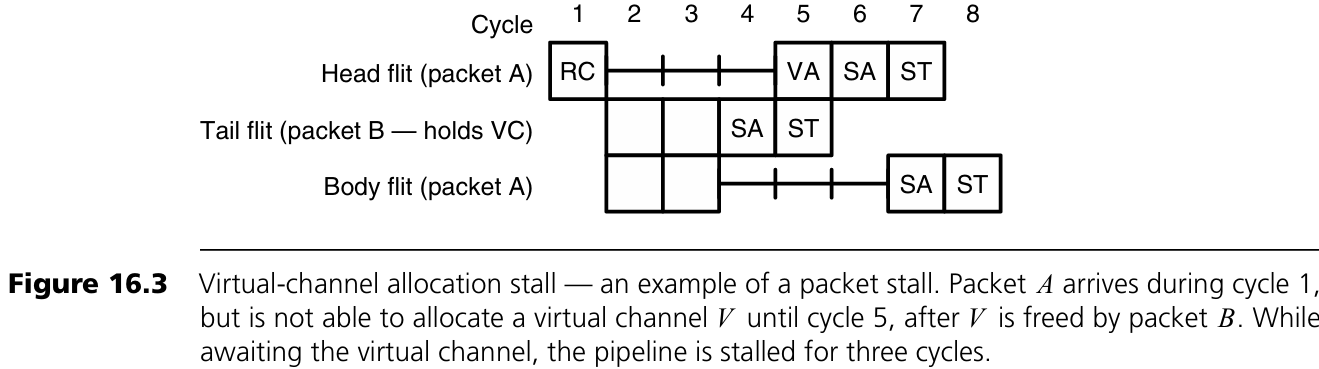
Figure 16.3: Virtual-channel allocation stall 예시
패킷 A의 head flit은 cycle 1에서 라우팅을 마치고 cycle 2부터 출력 virtual channel을 요청하지만, 모두 사용 중이라 할당 실패. 이 요청은 tail flit이 cycle 4에 switch allocation을 마친 패킷 B가 virtual channel을 해제할 때까지 실패한다. cycle 5에 패킷 A가 virtual channel을 할당받고, cycle 6에 switch allocation, cycle 7에 switch traversal을 수행한다. 이때 A의 body flit도 head flit이 SA 단계를 마치기 전까지 stall된다. 단, 충분한 입력 버퍼(예: 6개 flit)가 있다면 입력 채널의 전달 속도는 느려지지 않는다.

Figure 16.4: Switch allocation stall 예시
head flit과 첫 번째 body flit은 stall 없이 통과하지만, 두 번째 body flit은 cycle 5에 switch 할당 실패. cycle 6에 재시도 성공. 이후 flit도 모두 1 사이클씩 지연됨. credit stall도 동일한 타이밍을 가지지만, switch 슬롯 부족이 아닌 credit 부족으로 인해 요청 자체를 못 하는 상황이다.
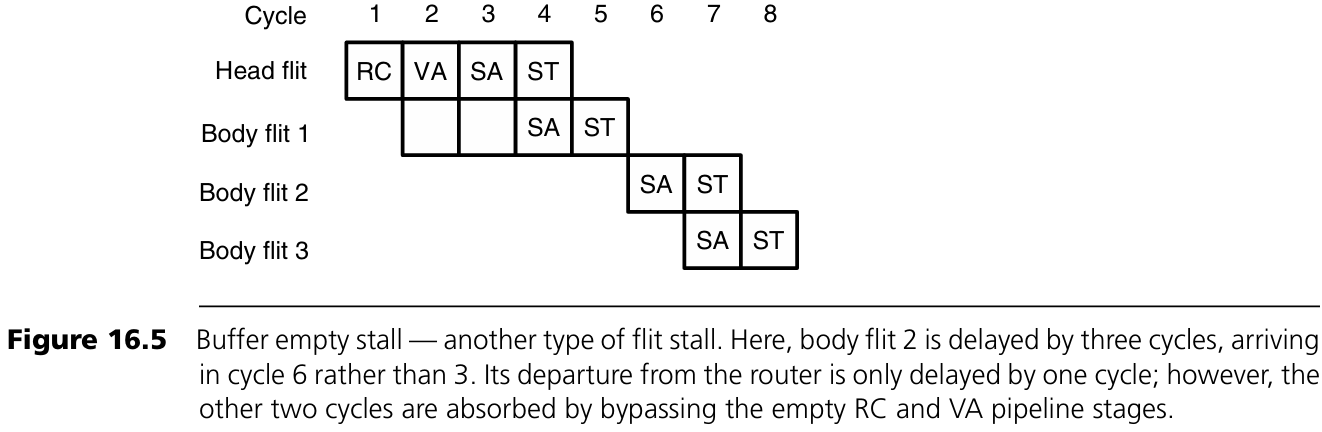
Figure 16.5: Buffer empty stall 예시
head flit과 body flit 1은 정상 처리되지만 body flit 2는 cycle 6에 도착. 이 flit은 도착 직후인 cycle 7에 SA 단계를 거치고, RC와 VA는 비워진 pipeline 단계를 그대로 우회한다. 이후 flit들도 마찬가지로 SA 단계로 바로 이동한다.
16.3 Credit을 이용한 루프 닫기
SA 단계에서 flit이 링크의 upstream 측을 떠나면 buffer가 할당된다. 이 buffer는 동일한 flit이 downstream의 SA 단계를 통과한 뒤 reverse 채널을 통해 credit이 반환되어야 재사용할 수 있다. 이 credit이 upstream 측의 입력 unit에 도달해야 buffer를 재사용할 수 있다. 따라서 buffer 하나를 나타내는 token은 하나의 루프를 따라 움직인다고 볼 수 있다: upstream의 SA → flit과 함께 downstream으로 이동 → downstream SA → credit으로 upstream으로 복귀. 이 동안 flit은 upstream 측의 RC, VA, SA 세 단계에서만 buffer를 점유하며, 루프의 나머지 시간은 buffer가 비어 있는 idle 시간이다.
credit 루프 지연 시간 tcrtt_{crt}는 flit 시간 단위로 표현되며, credit stall 없이 채널이 최대 대역폭으로 동작하려면 upstream 측에 필요한 최소 flit buffer 수의 하한을 제공한다. 각 flit이 하나의 buffer를 필요로 하므로...
token이 credit 루프를 완전히 한 바퀴 돌아야만 buffer를 재사용할 수 있기 때문에, flit buffer 수가 tcrtt_{crt}보다 적으면 첫 번째 credit이 돌아오기 전에 buffer가 모두 소진된다. credit 루프 지연 시간은 flit 시간 단위로 다음과 같이 정의된다.


즉, 충분한 buffer가 있으면 duty factor는 1이 되어 전체 대역폭을 사용할 수 있지만, buffer 수가 부족하면 credit stall로 인해 duty factor가 감소하고, 그에 따라 전송률도 비례하여 감소한다. 이때 남은 물리 채널 대역폭은 다른 virtual channel이 사용할 수 있다.

Figure 16.6: credit stall 예시
6개의 flit으로 구성된 패킷이 4개의 flit buffer만 있는 채널을 통과하는 경우를 보여준다. upstream은 흰색, downstream은 회색으로 표시했다. 링크 한 방향 이동 시간은 2 cycle이며, credit 전송은 CT, credit count 갱신은 CU 파이프라인 단계에서 수행된다.
이 예에서
- tf=4t_f = 4 (RC, VA, SA, ST)
- tc=2t_c = 2 (CT, CU)
- Tw=2T_w = 2
이를 식 (16.1)에 대입하면 tcrt=11t_{crt} = 11 사이클이 된다. 실제로 body flit 4는 head flit의 credit을 재사용하여 cycle 12에서 SA 단계에 진입한다. buffer가 4개이므로, 식 (16.2)의 duty factor는 4/114/11로 계산된다.
16.4 채널 재할당
credit이 flit buffer의 재사용을 가능하게 하듯, tail flit의 통과는 출력 virtual channel을 재할당할 수 있도록 한다. 하지만 이 재할당은 네트워크의 deadlock 특성에 큰 영향을 줄 수 있다.
패킷 A의 tail flit이 ST 단계에 진입하면, A에 할당된 출력 virtual channel xx를 다른 패킷 B에 할당할 수 있다. B는 같은 입력 포트, 같은 입력 virtual channel, 다른 포트의 virtual channel 등 어디에서든 올 수 있다.
그러나 이 시점에 xx를 B에 할당하면 B → A의 의존성이 생긴다. downstream 라우터의 입력 버퍼에서 A가 차지하고 있다면, B는 그 공간이 비워질 때까지 대기해야 한다. 이를 방지하려면, upstream 라우터의 ST 단계가 아니라 downstream 라우터의 ST 단계에서 tail flit이 빠져나가는 시점까지 기다려야 한다. 실제로는 upstream 라우터가 downstream의 ST 상태를 알 수 없으므로, tail flit의 credit이 돌아와 credit count가 최대치가 되는 시점까지 기다린다. 그러나 이 방식은 많은 short packet이 연이어 전송되는 상황에서는 물리 채널의 대역폭 낭비로 이어질 수 있다.

Figure 16.7: 출력 virtual channel 재할당의 세 가지 방식
- (a) 보수적 방식: tail flit의 credit이 돌아올 때까지 기다림. B의 head flit은 cycle 3에 RC를 완료한 뒤 cycle 15까지 VA 단계로 진입하지 못하고 12 cycle 동안 stall됨. 이 경우 지연은 tcrt+1t_{crt} + 1.
- (b) 공격적 방식: tail flit이 SA 단계를 마치자마자 VA 수행. B는 cycle 5에 VA 완료, 단 한 번만 stall됨. 단, downstream 라우터의 RC는 tail flit이 해당 라우터의 ST 단계를 끝낸 cycle 11까지 지연됨. 논리 단순.
- (c) 더욱 공격적 방식: tail flit이 아직 ST를 끝내기 전에도 B가 RC를 수행함. 이때 virtual channel은 동시에 두 패킷의 상태를 관리해야 하므로 제어 논리가 복잡해짐. 예를 들어 B는 RC를 완료했지만, A가 SA 할당에 실패하면 R 필드는 B의 것이고 O, P, C 필드는 A의 것이 되어 몇 cycle 동안 혼재된다. 이 경우 VA 단계에서 busy stall 발생 가능.
16.5 추측과 Lookahead
interconnection network의 지연(latency)은 파이프라인의 깊이와 직접적으로 연관되므로, 각 단계의 지연을 늘리지 않는 범위 내에서 파이프라인 단계를 줄이는 것이 이득이다. 이를 위해 다음 두 가지 방법을 사용할 수 있다:
- Speculation (추측 실행): 원래 순차적으로 수행되던 작업을 병렬로 수행
- Lookahead (선제 계산): 미리 계산을 수행하여 critical path에서 제거
예를 들어, virtual channel 할당이 성공할 것이라고 가정하고, VA와 SA를 동시에 수행하면 head flit은 세 단계만 거치게 되고, body flit은 RC에서 1 cycle 동안만 idle 상태가 된다.
RC 단계에서 가능한 virtual channel 집합을 얻은 뒤, 이 중 하나에 대한 VA와 해당 물리 채널의 switch 슬롯에 대한 SA를 동시에 요청할 수 있다. virtual channel 할당이 실패하면 다음 사이클에 VA와 SA를 다시 시도하며, switch 할당이 실패하면 다음 사이클에는 SA만 다시 시도하면 된다. 이 경우 이미 output virtual channel은 할당된 상태이므로 더 이상 추측이 아니다.
주: RC 결과가 여러 물리 채널에 걸쳐 있는 경우, 어떤 채널을 선택할지에 대해서도 추측할 수 있다.

Figure 16.8은 virtual-channel allocation(VA)과 switch allocation(SA)을 동시에 수행하는 speculative router pipeline을 보여준다. 이 경우 head flit에 대한 switch allocation은 추측(speculative)이며, VA가 성공할 때만 유효하다. VA가 실패하면 SA가 성공하더라도 무시된다.
성능에 부정적인 영향을 주지 않기 위해, switch allocation에서는 추측 요청보다 비추측(non-speculative) 요청에 우선권을 주는 보수적 추측 방식을 사용할 수 있다. 이렇게 하면 비추측 요청에 사용될 수 있는 switch 사이클이 잘못된 추측 요청에 낭비되는 일이 없다.
실제로는, 추측 실행은 파이프라인 지연이 중요한 상황에서 매우 잘 작동한다. 파이프라인 지연은 라우터가 적게 로드되었을 때 중요하며, 이 경우 대부분의 virtual channel이 비어 있어 추측이 거의 항상 성공한다. 반면 라우터가 무겁게 로드되면 대기열 지연(queueing latency)이 지배적이므로, 추측의 성공 여부가 전체 성능에 큰 영향을 미치지 않는다.

한 단계 더 나아가 switch traversal(ST)도 VA 및 SA와 병렬로 추측 수행할 수 있다. Figure 16.9는 VA, SA, ST를 모두 병렬로 수행하는 doubly speculative pipeline을 보여준다. 이 경우 flit은 switch allocation 결과를 기다리지 않고 출력으로 먼저 전송된다. 이를 위해 switch는 충분한 속도향상(speedup), 또는 최소한 입력 속도향상(input speedup)을 가져야 한다. flit이 switch를 통과하는 동안 switch allocation은 병렬로 수행되며, 결과적으로 선택된 flit이 출력된다.
이중 추측이 클럭 사이클 시간을 늘리지 않고 가능한지는 switch와 allocator의 구현 세부 사항에 따라 다르다. 많은 라우터에서는 virtual-channel allocator가 크리티컬 패스이고, switch allocation과 출력 선택은 직렬로 처리해도 클럭 시간을 증가시키지 않는다.
파이프라인 단계를 2사이클까지 줄였지만, 1사이클로 줄이는 것도 가능할까? routing computation도 VA, SA, ST와 병렬로 추측해 수행하는 세 번째 추측을 생각해볼 수 있다. 그러나 이는 비효율적이다. flit이 어디로 갈지를 모르고 채널이나 switch 슬롯을 할당하거나 전송을 시도하는 것은 불가능하기 때문이다.
대신, routing 결과를 lookahead 방식으로 미리 계산할 수 있다. hop i에서 라우터를 통과할 때, 현재 라우터에 대한 라우팅이 아니라, 다음 hop (i+1)의 라우터에 대한 라우팅을 미리 계산하고 그 결과를 head flit에 함께 전달하는 방식이다. 그러면 각 라우터에 도착할 때 이미 출력 경로가 정해져 있어 VA와 SA가 즉시 시작될 수 있다. 다음 hop 라우팅 계산(NRC)은 파이프라인 어느 단계와도 병행 수행 가능하다.

Figure 16.10은 이러한 1-hop route lookahead 방식을 두 가지 파이프라인에 적용한 예다.
- 왼쪽: 기존 4단계 파이프라인에서 NRC를 VA에 병합해 3단계로 줄임
- 오른쪽: Figure 16.9의 이중 추측 파이프라인에 적용하여 단일 단계로 축소
latency가 중요한 응용에서는 이보다 더 줄이기 어렵다.
16.6 Flit 및 Credit 인코딩
지금까지 flit과 credit이 라우터 사이를 오간다고 했지만, 실제로 어떻게 구분하고, 어디서 시작하는지, 어떤 방식으로 인코딩되는지는 설명하지 않았다. 이 절에서는 그 구체적인 방식을 간략히 설명한다.
Flit과 Credit의 분리

가장 단순한 방법은 flit과 credit을 별도의 채널로 전송하는 것이다 (Figure 16.11(a)). 일반적으로 flit 채널은 더 많은 정보를 담아야 하므로 credit 채널보다 훨씬 넓다. 그러나 이 방식은 비효율적이다. credit 채널에 대역폭이 남는 일이 많고, 채널이 좁으면 credit을 serialize하여 latency가 증가한다.
더 일반적이고 효율적인 방식은 flit과 credit을 하나의 물리 채널로 통합하는 것이다 (Figure 16.11(b)). 이 경우 각 flit에 credit을 포함시키는 방식(piggybacking)을 사용할 수 있다. 이는 credit이 flit에 '태워져' 같이 전송되는 형태다. 두 객체의 크기는 다르지만, 평균적으로는 flit 하나당 credit 하나가 필요하므로 이 방식은 적절하다.
다른 방법으로는 flit과 credit을 phit 단위로 멀티플렉싱하는 것도 있다. 이 방법은 flit과 credit 비율이 일시적으로 달라질 때, 전체 대역폭을 flit 또는 credit에 집중할 수 있는 장점이 있다. 단, credit이 phit 단위에 딱 맞지 않으면 단편화(fragmentation) 손실이 발생할 수 있다.
Phit-level 멀티플렉싱과 인코딩

phit 단위 멀티플렉싱을 위해서는 각 phit이 무엇의 시작인지(flit/credit/idle), 어디서 시작되는지 알아야 한다. 이 정보는 phit-level 프로토콜로 인코딩된다. Figure 16.12(a)에서 각 phit은 타입 필드(type field)와 payload 필드를 가진다. 타입 필드는 다음과 같이 정의될 수 있다:
- 10: credit 시작
- 11: flit 시작
- 0X: idle
credit과 flit의 길이는 고정되어 있으므로, 중간에 있는 phit은 별도 표시 없이 길이로 추론 가능하다. 중간 phit의 type 필드는 추가 payload 정보에 사용할 수 있다. 만약 credit을 flit에 piggyback한다면 credit 시작 인코딩은 필요 없고, type 필드는 1비트로 줄일 수 있다.
Flit과 Credit의 내용

Figure 16.13에서 각 flit은 다음 필드를 포함한다:
- VC 식별자: 해당 flit이 속한 virtual channel
- Type: head flit인지 아닌지, tail 여부도 포함 가능
- Payload: 실제 데이터
- Check: 오류 검사용 필드
- Route 정보: head flit에만 존재, routing 함수가 출력 virtual channel 선택 시 사용
- Credit 필드: piggyback 방식인 경우 head 및 non-head flit 모두에 포함
Credit은 다음 필드를 포함한다:
- VC 식별자: credit을 받을 virtual channel
- Check: 오류 검사용
- Type (선택): on/off flow control 등의 back-channel 정보 포함 가능
16.7 사례 분석: Alpha 21364 라우터
Alpha 21364는 Alpha 마이크로프로세서 아키텍처 계열의 최신 버전이다. 이 1.2GHz, 1억 5200만 개의 트랜지스터로 이루어진 칩은 Alpha 21264 프로세서 코어에 cache coherence 하드웨어, 두 개의 메모리 컨트롤러, 그리고 네트워크 라우터를 단일 다이에 통합했다. 이를 통해 Alpha 21364는 대규모 공유 메모리 시스템의 단일 칩 구성 블록으로 활용될 수 있다.
이 라우터는 4개의 외부 포트를 가지며 총 22.4GB/s의 네트워크 대역폭을 제공하고, 최대 128개의 프로세서를 2D torus 네트워크로 연결할 수 있다. 21364 라우터의 아키텍처는 본 장에서 소개한 기본 virtual-channel 라우터 구조와 매우 유사하다. 높은 1.2GHz 작동 주파수를 만족시키기 위해 라우터 내부에서 패킷은 깊은 파이프라인을 거치며, 이로 인한 지연을 회복하기 위해 speculation도 사용된다.

Figure 16.14는 21364 라우터 아키텍처의 단순화된 구조를 보여준다. 실제 구현은 8개의 입력 포트와 7개의 출력 포트를 가지지만, 그림에서는 단순화를 위해 3×3 라우터만 표시되어 있다. crossbar는 각 출력 포트에 대한 mux로 구현되어 있으며, switch allocator는 local arbiter와 global arbiter 두 부분으로 나뉘어 있다.
이 설계는 wormhole flow control이 아닌 cut-through flow control을 사용한다. 이로 인해 각 입력 unit은 전체 패킷을 저장할 수 있어야 하지만, coherence 프로토콜에서 최대 패킷 크기가 76바이트에 불과하기 때문에 실용적인 접근이다. 각 입력 unit은 여러 개의 최대 크기 패킷을 저장할 수 있는 버퍼를 포함하고 있으며, 전체 라우터는 316개의 패킷 버퍼를 가진다. 이 정도의 버퍼 수는 deadlock 회피와 adaptive routing을 위한 여러 개의 virtual channel 운용에 충분하다.

Figure 16.15는 라우터의 파이프라인 단계를 보여준다. cut-through 방식이므로 phit 기준으로 파이프라인이 정의된다. 첫 번째 phit은 RC 단계에서 라우팅되고, 이후 wire 지연(T) 단계를 거친다. header decode 및 입력 unit 상태 갱신(DW)을 수행한 후, payload는 input queue에 저장(WrQ)된다. 이 과정과 병행하여 첫 번째 phit이 입력 버퍼에 저장되는 동안 switch allocation이 시작된다.
cut-through flow control을 사용하므로 일반 virtual-channel 라우터에서 분리되었던 virtual-channel allocation과 switch allocation 단계를 하나의 단일 allocation(SA) 단계로 병합할 수 있다. 일반적으로 virtual channel은 출력 포트당 여러 개가 활성화될 수 있지만, cut-through 라우터는 각 출력 포트당 하나의 virtual channel만 활성화되도록 단순화할 수 있다. 이로 인해 virtual channel이 할당되면, 그 자체가 switch allocation도 유효함을 보장한다.
이 구조는 wormhole flow control에서는 virtual channel이 막힐 수 있어 부적합하지만, cut-through 방식에서는 downstream 라우터가 전체 패킷을 수용할 수 있는 충분한 buffer를 가지므로 blocking 없이 전달이 가능하다.
정밀한 타이밍 요구사항을 만족시키기 위해, switch allocation은 local arbiter와 global arbiter로 나뉘며 2단계로 구성된다.
- SA1 단계: 각 입력 unit에서 local arbiter가 준비된 패킷 중 하나를 선택. 출력 포트가 사용 가능하고 downstream에 빈 패킷 버퍼가 있을 때 준비 상태로 간주된다.
- RE 단계: 선택된 패킷의 header 정보가 읽혀서 해당 출력으로 전송된다.
- SA2 단계: 여러 패킷이 하나의 출력 포트를 요청할 수 있으므로, global arbiter가 최종적으로 출력당 하나의 패킷을 선택해 할당한다.
- ST1 단계: local arbiter에 의해 선택된 모든 패킷의 데이터는 speculative하게 출력으로 전송된다. 나중에 global arbiter 결과에 따라 승자만 유효하게 처리된다.
- ST2 단계: 실제 전송이 완료됨
- ECC 단계: 7비트의 오류 정정 코드가 phit에 추가되어 downstream 라우터로 전송됨
스펙 실행 결과는 backchannel을 통해 입력 unit으로 피드백되며, 성공하면 이후 phit은 계속 전송되고 실패 시 switch 내에서 폐기되며 재전송된다. 이와 같은 deep pipeline 설계와 speculative transfer 덕분에 Alpha 21364 라우터는 10.8ns의 매우 낮은 per-hop latency와 70~90%의 피크 처리량을 달성할 수 있다.
16.8 참고 문헌 비고
이 장에서 설명한 기본 virtual-channel router 구조는 Torus Routing Chip에서 유래되었다. 이후 Reliable Router, Cray T3D/T3E, IBM SP 시리즈, SGI SPIDER chip 등에서 개선되었으며, 특히 SPIDER는 한 단계 앞서 라우팅을 수행한 최초의 라우터였다. 라우터 latency를 줄이기 위한 speculation 기법은 Peh와 Dally가 처음 제안하였다.
16.9 연습문제
16.1 단일 virtual channel 사용 시의 단순화
물리 채널당 하나의 virtual channel만 있을 경우, 파이프라인과 global state는 어떻게 변하는가? 각 파이프라인 단계와 global state의 각 필드를 설명하라.
16.2 circuit switching 라우터의 아키텍처
Figure 12.6과 같은 circuit switching 라우터를 설계하라. global state는 무엇인가? 파이프라인은 어떻게 구성되는가? 각 circuit과 flit을 처리하는 단계는 무엇인가?
16.3 ack/nack 흐름 제어가 파이프라인에 미치는 영향
credit 기반 흐름 제어 대신 ack/nack 흐름 제어를 사용할 경우, 라우터 파이프라인은 어떻게 변하는가? credit stall은 어떻게 처리되는가?
16.4 공격적인 virtual-channel 재할당으로 인한 의존성
Duato의 프로토콜을 기반으로 한 2D mesh 네트워크의 최소 adaptive routing 알고리즘을 고려하자. VC 0은 dimension-order routing에, VC 1은 adaptive routing에 사용된다. Figure 16.7에 나온 재할당 전략 중 어떤 것이 이 알고리즘에서 deadlock-free한가?
16.5 좁은 채널에서의 flit 포맷 구성
Figure 16.13의 필드 요구사항이 다음과 같다고 하자: VC 필드 4비트, type 정보 2비트, credit 필드 8비트, route 정보 6비트. 입력 채널이 클럭 사이클당 8비트를 수신할 경우, 라우팅을 시작하기까지 몇 사이클이 필요한가? 필요한 경우 해당 flit 포맷을 제시하라. route lookahead를 사용할 경우, virtual-channel allocation은 첫 사이클에 시작할 수 있는가?
'System-on-Chip Design > NoC' 카테고리의 다른 글
| Arbitration (1) | 2025.06.16 |
|---|---|
| Router Datapath Components (0) | 2025.06.16 |
| Quality of Service (1) | 2025.06.05 |
| Deadlock and Livelock (2) | 2025.06.05 |
| Buffered Flow Control (1) | 2025.06.05 |