NVIDIA NVLink 네트워크가 AI 추천 시스템(Neural Recommender Engine) 및 임베딩 테이블(Embedding Tables) 학습에서 어떻게 높은 대역폭을 제공하는지를 설명하는 개념도입니다.
특히, 기존 InfiniBand(IB) 대비 4.5배 더 높은 대역폭을 제공하는 NVLink의 성능 차이를 강조하고 있습니다.
1. 좌측: NVLink 기반 Neural Recommender Engine 구조
✅ (1) Neural Recommender Engine의 병렬 학습 방식
- 딥러닝 기반 추천 시스템은 모델 병렬(Model Parallel)과 데이터 병렬(Data Parallel) 방식을 혼합하여 학습
- 상단의 Linear Layers(선형 레이어)는 데이터 병렬 방식으로 여러 GPU에 복제(Replicated across GPUs)
- 하단의 Embedding Tables(임베딩 테이블)는 모델 병렬 방식으로 GPU마다 서로 다른 데이터를 저장(Distributed across GPUs)
✅ (2) Model-Parallel → Data-Parallel 변환 (All2All)
- 모델의 일부(임베딩 테이블)는 여러 GPU에 분산 저장되지만, 이후 모델을 학습하기 위해서는 GPU 간 데이터 공유가 필요
- All2All 연산을 통해 모델 병렬 방식에서 데이터 병렬 방식으로 변환
- 이 과정에서 GPU 간 대량의 데이터 전송 발생 → NVLink의 높은 대역폭이 필수적
✅ (3) GPU 간 데이터 이동량 (Bandwidth 요구량)
- 각 GPU는 임베딩 테이블 데이터를 다르게 저장하며, 다른 GPU의 데이터를 가져와야 함
- 예제에서 GPU 0~n의 메모리 구성을 보면,
- GPU 0: 10GB + 20GB
- GPU 1: 40GB + 10GB
- GPU 2: 60GB
- GPU n: 60GB
→ 모델 병렬 학습 시, 서로 다른 GPU 간 대규모 데이터 교환이 필요하므로 NVLink가 필수
2. 우측: NVLink vs. InfiniBand (IB) 대역폭 비교
14TB 임베딩 테이블을 사용하는 예제 추천 시스템에서 H100 NVLink 네트워크의 대역폭 성능 비교
- A100 + InfiniBand (IB)
- 기준선(1x)
- 기존 InfiniBand 네트워크를 사용할 경우 대역폭이 상대적으로 낮음
- H100 + InfiniBand (IB)
- A100 대비 대역폭이 2배 증가
- InfiniBand만으로도 H100의 성능을 일부 활용 가능
- H100 + NVLink Network
- H100 + InfiniBand 대비 2배 더 높은 대역폭 제공
- A100 + InfiniBand 대비 4.5배 더 높은 대역폭 제공
- NVLink 기반 네트워크를 활용하면 GPU 간 데이터 교환 속도가 획기적으로 향상됨
3. NVLink의 효과 및 중요성
- 기존 InfiniBand(IB) 대비 4.5배 더 높은 대역폭 제공
- 임베딩 테이블이 매우 큰 추천 시스템(Neural Recommender Engine)에서 필수적인 네트워크 솔루션
- GPU 간 All2All 통신을 최적화하여 모델 병렬과 데이터 병렬 변환 과정에서 성능 극대화
- H100에서 NVLink를 활용하면, AI 모델 학습 및 추천 시스템 성능이 획기적으로 향상
4. 결론
- H100 NVLink 네트워크는 AI 추천 시스템에서 InfiniBand보다 4.5배 높은 대역폭 제공
- 대규모 임베딩 테이블(Embedding Tables)을 활용하는 추천 시스템에서 NVLink의 높은 전송 속도가 필수적
- NVLink를 활용하면 모델 병렬과 데이터 병렬 변환(All2All)이 훨씬 더 빠르게 수행됨
- 기존 A100 기반 InfiniBand 네트워크보다 H100 NVLink가 압도적인 성능 제공
👉 즉, NVLink는 AI 추천 시스템 및 대규모 데이터 학습에서 필수적인 GPU 간 네트워크 기술로, InfiniBand 대비 훨씬 높은 대역폭을 제공하여 딥러닝 학습 속도를 극대화할 수 있습니다. 🚀
딥러닝 기반 추천 시스템: 모델 병렬과 데이터 병렬의 필요성
딥러닝 기반 추천 시스템은 대규모 사용자 데이터와 아이템 데이터를 분석하여 최적의 추천을 제공하는 AI 모델입니다.
대표적인 추천 시스템 모델로는 Deep Learning Recommendation Model (DLRM), Wide & Deep, Transformer 기반 추천 모델 등이 있습니다.
이러한 추천 시스템은 대규모 임베딩 테이블(Embedding Tables)과 신경망 모델(MLP, Transformer 등)을 함께 사용하기 때문에, 모델 병렬(Model Parallel)과 데이터 병렬(Data Parallel)을 혼합하여 학습해야 성능을 극대화할 수 있습니다.
1. 추천 시스템에서 학습해야 할 주요 요소
딥러닝 기반 추천 모델은 주로 두 가지 요소를 학습합니다.
✅ (1) 임베딩 테이블 (Embedding Tables)
- 사용자 및 아이템의 특성(Feature)을 벡터로 변환하여 저장
- 사용자 ID, 나이, 성별, 지역, 선호 카테고리, 아이템 ID 등을 고차원 벡터로 표현
- 추천 모델에서는 이러한 임베딩 벡터를 사용하여 유사한 사용자 및 아이템을 찾음
- 문제점: 임베딩 테이블이 매우 커질 수 있음 (수십~수백 TB)
✅ (2) 신경망 모델 (Neural Network, MLP or Transformer)
- 사용자의 현재 행동(클릭, 좋아요, 검색, 구매 등)과 임베딩 벡터를 결합하여 추천 결과 생성
- 일반적으로 다층 퍼셉트론(MLP) 또는 Transformer를 활용하여 예측을 수행
- 문제점: 연산량이 많고, 병렬 처리가 필요
2. 모델 병렬(Model Parallel)과 데이터 병렬(Data Parallel)을 함께 사용해야 하는 이유
추천 시스템에서는 단순히 데이터 병렬(Data Parallel)만으로는 해결할 수 없는 문제들이 존재합니다.
특히, 임베딩 테이블은 모델 병렬(Model Parallel), 신경망 모델은 데이터 병렬(Data Parallel)로 처리하는 것이 최적의 방법입니다.
방식사용 대상이유
| 모델 병렬 (Model Parallel) | 임베딩 테이블 (Embedding Tables) | 너무 크기 때문에 여러 GPU에 분산 저장해야 함 |
| 데이터 병렬 (Data Parallel) | 신경망 모델 (MLP, Transformer 등) | 모든 GPU에서 동일한 모델을 실행하면서 병렬 연산 최적화 |
3. 모델 병렬과 데이터 병렬을 함께 사용해야 하는 이유 (예제 포함)
예제: Netflix 추천 시스템
Netflix는 수억 명의 사용자와 수백만 개의 영화를 추천해야 하는 대규모 추천 시스템을 운영합니다.
각 사용자에게 맞춤형 콘텐츠를 제공하기 위해 사용자 데이터와 영화 데이터를 임베딩 테이블로 변환한 후, 신경망 모델을 통해 추천을 수행합니다.
✅ (1) 모델 병렬이 필요한 이유 (임베딩 테이블 분산)
- Netflix에는 수억 명의 사용자와 수백만 개의 영화가 존재
- 각 사용자와 영화에 대한 임베딩 벡터를 저장하려면 엄청난 메모리가 필요 (수십 TB~수백 TB)
- 하나의 GPU에 저장하기에는 불가능
→ 해결책: **모델 병렬(Model Parallel)**을 사용하여 여러 GPU에 임베딩 테이블을 분산 저장
✅ (2) 데이터 병렬이 필요한 이유 (신경망 모델 병렬 처리)
- 추천을 수행하는 MLP(다층 퍼셉트론) 또는 Transformer 모델은 모든 GPU에서 동일한 연산을 수행
- 배치 데이터를 여러 GPU에 나누어 처리하면 학습 속도가 향상됨
→ 해결책: **데이터 병렬(Data Parallel)**을 사용하여 동일한 신경망 모델을 여러 GPU에서 동시에 학습
4. 모델 병렬(Model Parallel)과 데이터 병렬(Data Parallel)의 동작 방식
✅ (1) 모델 병렬 (Model Parallel)
- 임베딩 테이블을 여러 GPU에 분산 저장
- GPU마다 서로 다른 부분의 임베딩 데이터를 저장하고, 필요할 때 다른 GPU의 임베딩 데이터를 가져와야 함
- All2All 통신(All-to-All Communication)이 발생 (GPU 간 데이터 이동 필요)
🔹 예제 (4개의 GPU가 임베딩 테이블을 나눠 저장하는 경우)
- GPU 0: 사용자 ID 임베딩 저장
- GPU 1: 영화 ID 임베딩 저장
- GPU 2: 카테고리 임베딩 저장
- GPU 3: 지역 및 장르 임베딩 저장
→ 사용자 ID와 영화 ID가 동일한 GPU에 없으므로, 데이터를 공유해야 함 → All2All 통신이 필수적
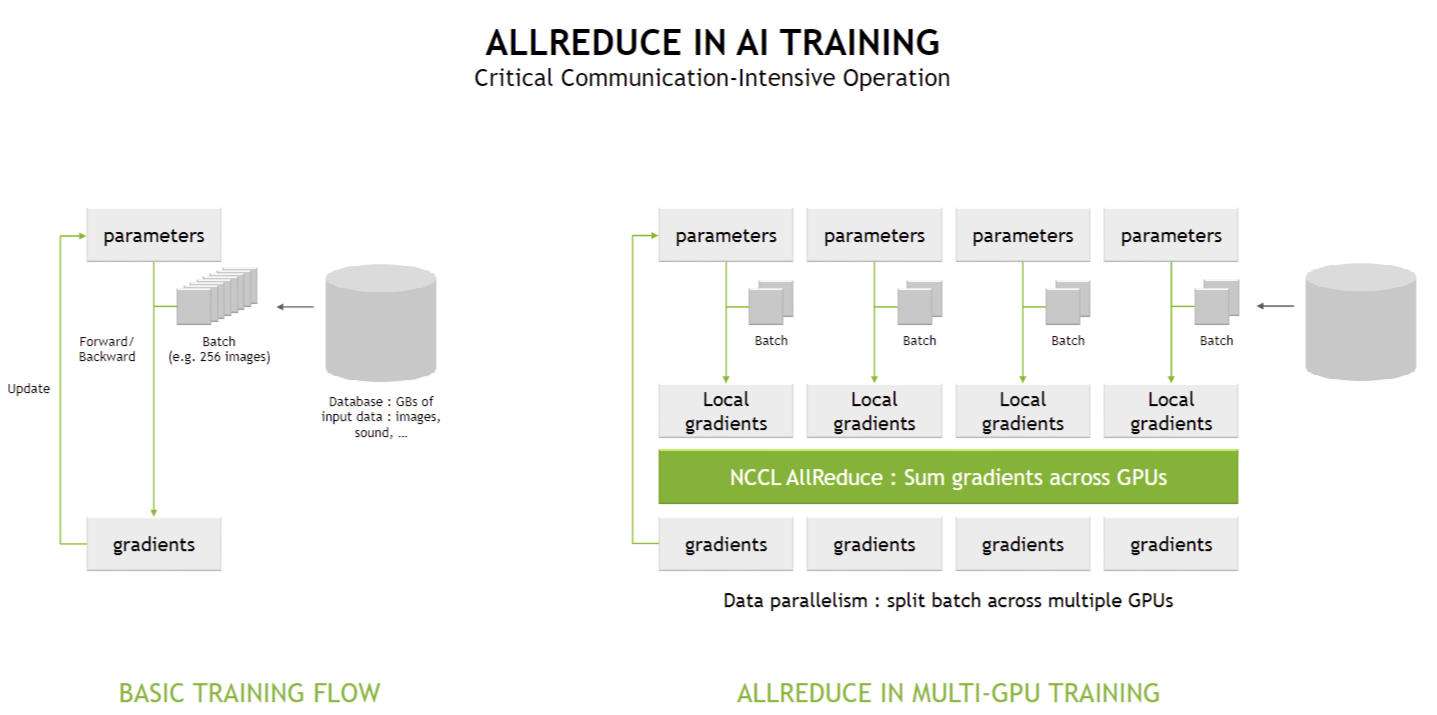
✅ (2) 데이터 병렬 (Data Parallel)
- 같은 신경망 모델(MLP 또는 Transformer)을 모든 GPU에서 복사하여 실행
- 각 GPU는 서로 다른 배치를 학습하면서 그래디언트를 계산
- 학습이 끝나면 AllReduce 연산을 수행하여 모든 GPU가 동일한 그래디언트 업데이트 적용
🔹 예제 (4개의 GPU가 데이터 병렬로 학습하는 경우)
- GPU 0: 첫 번째 배치(256개 샘플) 학습
- GPU 1: 두 번째 배치(256개 샘플) 학습
- GPU 2: 세 번째 배치(256개 샘플) 학습
- GPU 3: 네 번째 배치(256개 샘플) 학습
→ 모든 GPU가 동일한 신경망 모델을 학습하지만, 서로 다른 배치를 학습함
→ AllReduce 연산을 사용하여 그래디언트를 동기화해야 함
5. 결론
- 딥러닝 기반 추천 시스템에서는 임베딩 테이블과 신경망 모델을 동시에 처리해야 하므로, 모델 병렬과 데이터 병렬을 함께 사용해야 함
- 임베딩 테이블은 너무 크기 때문에 모델 병렬(Model Parallel) 방식으로 여러 GPU에 분산 저장
- 신경망 모델(MLP, Transformer 등)은 데이터 병렬(Data Parallel) 방식으로 모든 GPU에서 동일한 연산을 수행
- All2All 통신(All-to-All Communication)과 AllReduce 연산을 활용하여 GPU 간 데이터 이동 및 그래디언트 동기화 수행
- Netflix, YouTube, TikTok 같은 대규모 추천 시스템에서 필수적인 학습 방식
👉 즉, 모델 병렬과 데이터 병렬을 동시에 사용해야 대규모 추천 시스템을 효율적으로 학습할 수 있으며, 이를 위해 GPU 간 빠른 데이터 교환이 가능한 NVLink 및 NVSwitch 기술이 필수적입니다. 🚀
1. 추천 시스템에서 NVLink 대역폭이 중요한 이유
✅ (1) 임베딩 테이블의 크기 문제
- 추천 시스템에서는 사용자 ID, 아이템 ID, 선호 카테고리 등의 임베딩 벡터를 저장하는 임베딩 테이블(Embedding Tables)이 매우 큼
- 수십~수백 TB 크기의 데이터를 GPU 여러 개에 분산 저장해야 함
- 데이터가 한 GPU에 들어가지 않기 때문에 GPU 간 빠른 데이터 이동이 필수적
✅ (2) All2All 통신(모델 병렬 → 데이터 병렬 변환)
- 임베딩 테이블이 여러 GPU에 분산 저장되므로, 학습 시 서로 다른 GPU의 데이터를 가져와야 함
- 이를 위해 All2All 통신(All-to-All Communication)이 필수적
- 이 과정에서 GPU 간 대량의 데이터 교환이 발생 → NVLink의 높은 대역폭이 필요
✅ (3) NVLink vs. InfiniBand(IB) 비교 시 추천 시스템이 가장 두드러진 차이를 보임
- H100 + NVLink가 InfiniBand보다 4.5배 높은 대역폭을 제공
- All2All 통신을 최적화하면 임베딩 테이블을 처리하는 속도가 크게 향상됨
- 결과적으로, NVLink를 사용할 때 추천 시스템의 학습 속도가 극적으로 향상됨
2. NVLink의 효과가 두드러지는 AI 워크로드
추천 시스템 외에도 NVLink의 높은 대역폭이 중요한 AI 워크로드는 많습니다. 하지만 그중에서도 추천 시스템이 가장 직접적인 성능 차이를 보여주는 대표적인 사례입니다.
AI 워크로드NVLink 효과이유
| 추천 시스템 (Neural Recommender Engine) | 🚀🚀🚀🚀🚀 (최고 효과) | 임베딩 테이블이 크고 All2All 통신이 많아 GPU 간 대역폭이 중요 |
| 대형 언어 모델 (LLM, GPT-4 등) | 🚀🚀🚀🚀 (매우 효과적) | 모델 병렬 학습 시 GPU 간 빠른 데이터 공유 필요 |
| 비전 트랜스포머 (Vision Transformer, ViT) | 🚀🚀🚀 (효과적) | 대규모 이미지 배치 처리 시 GPU 간 빠른 데이터 전송 필요 |
| 자율주행 AI (Self-Driving AI) | 🚀🚀 (일부 효과) | 실시간 데이터 처리 시 활용 가능하지만, 대역폭보다는 지연 시간 최적화가 더 중요 |
3. 결론
- 추천 시스템은 NVLink의 높은 대역폭이 가장 두드러지게 효과를 발휘하는 대표적인 AI 워크로드
- 임베딩 테이블이 매우 크고, GPU 간 All2All 통신이 많아 NVLink가 필수적
- NVLink가 없으면 GPU 간 데이터 전송이 InfiniBand보다 4.5배 느려져 학습 속도가 급격히 저하
- 대규모 AI 모델(LLM, ViT 등)에서도 NVLink의 효과가 크지만, 추천 시스템이 가장 차이가 명확함
👉 즉, NVIDIA가 추천 시스템 예제를 사용한 이유는 NVLink의 대역폭 증가 효과가 가장 극적으로 나타나는 AI 워크로드이기 때문입니다. 🚀
'AI > NVIDIA' 카테고리의 다른 글
| NVLink Network의 전통적인 네트워킹과의 매핑 (0) | 2025.02.23 |
|---|---|
| NVLink Network: 새로운 NVLink 네트워크 아키텍처 (0) | 2025.02.23 |
| NVLink SHARP Acceleration: NVLink 기반의 SHARP 가속화 (0) | 2025.02.23 |
| 전통적인 AllReduce 계산 (Traditional AllReduce Calculation) (0) | 2025.02.23 |
| AllReduce in AI Training: AI 학습에서의 AllReduce 역할 (0) | 2025.02.23 |