

Abstract
이 연구는 현대 컴퓨팅 시스템에서 신경망을 가속화하는 데 필수적인 신경 처리 장치(NPUs)가 생성하는 열을 관리하는 새로운 방법을 탐구합니다. NPU는 처리를 위해 많은 곱셈-누적(MAC) 단위를 사용하는데, 이는 훌륭하지만 많은 열을 생성합니다. 이 연구는 이러한 열 문제를 처음으로 조사합니다.
주요 발견은 다음과 같습니다:
- 정밀도 및 주파수 스케일링: 연구는 계산의 정확도(정밀도 스케일링)와 NPU의 속도(주파수 스케일링)를 변경하는 것이 온도를 낮추는 데 어떻게 도움이 되는지를 테스트했습니다.
- 고급 냉각 기술: 초격자 박막 열전재료를 사용하는 새로운 냉각 방법을 도입했으며, 이는 NPU 칩의 온도, 처리 속도, 냉각 비용 및 정확도 사이의 새로운 균형을 가능하게 합니다.
- 하이브리드 열 관리 (PFS-TE 기법): PFS-TE라고 하는 새로운 접근 방식이 제안되었습니다. 이는 새로운 냉각 기술과 정밀도 및 주파수 스케일링을 결합하여 효과적인 열 관리를 위한 것입니다.
- 종합적 분석 및 시뮬레이션: 팀은 MAC 배열에 초점을 맞추어 NPU의 열 발생 및 냉각을 분석하기 위해 고급 도구와 시뮬레이션을 사용했습니다. 이들은 14nm 인텔 FinFET 기술을 사용하여 설계되었습니다.
- 디자인 공간 탐색: 연구는 온도 감소, 냉각에 필요한 전력, 처리 속도 및 정확도 사이의 다양한 트레이드오프를 탐색했습니다.
- 실험 결과: 이미지 분류를 위해 다양한 신경망을 테스트했습니다. 새로운 열 관리 방법은 다양한 온도 제한(105°C, 85°C, 70°C) 하에서 NPU의 효율성(TOPS/줄)을 최대 2배까지 향상시켰습니다. 이 네트워크의 정확도는 89.0%에서 85.5%로 약간만 감소했습니다.
더 간단한 말로, 이 연구는 고급 냉각 기술과 처리 속도 및 정확도 조정을 결합한 새로운 방법을 통해 NPU를 시원하고 효율적으로 유지하는 방법을 찾았습니다. 이 접근 방식은 NPU가 수행하는 작업의 정확도를 약간만 줄이면서 성능과 효율성을 향상시킵니다.
이 연구는 컴퓨팅과 열 관리 분야에서 상당히 중요하다고 생각합니다. 몇 가지 이유는 다음과 같습니다:
- 혁신적인 접근: 신경 처리 장치(NPUs)의 열 문제를 해결하기 위한 이 연구의 다각적 접근 방식은 기술 혁신의 좋은 예입니다. 정밀도 및 주파수 스케일링과 고급 냉각 기술의 결합은 창의적이며, 이는 다른 반도체 기술에도 영감을 줄 수 있습니다.
- 효율성과 성능의 향상: 열 관리는 전자 장치의 성능과 효율성을 크게 제한할 수 있습니다. 이 연구는 NPU의 효율성을 향상시키면서도 정확도를 크게 희생하지 않는 방법을 제시합니다.
- 지속 가능성 측면: 열 관리는 에너지 소비를 줄이고, 따라서 환경에 미치는 영향을 감소시키는 데 중요한 역할을 할 수 있습니다. 이 연구는 에너지 효율적인 컴퓨팅 시스템을 향한 중요한 단계를 나타냅니다.
- 실용적인 적용 가능성: 연구가 14nm 인텔 FinFET 기술을 기반으로 한 것은 이 기술이 현재의 제조 공정과 호환될 수 있음을 시사합니다. 이는 실제 산업 적용으로 이어질 가능성이 높습니다.
- 데이터 센터와 클라우드 컴퓨팅에의 영향: NPU의 효율성과 신뢰성을 향상시키는 것은 대규모 데이터 센터와 클라우드 컴퓨팅 인프라의 효율성과 지속 가능성에도 중요한 영향을 미칠 수 있습니다.
종합적으로, 이 연구는 고성능 컴퓨팅 시스템의 설계와 운영에 있어서 중요한 발전을 나타내며, 이는 향후에 다양한 기술 분야에 걸쳐 중요한 파급 효과를 가질 수 있습니다.
1. Introduction
이 연구는 인공지능 분야에서 최근 일어난 주요 발전과 그로 인한 신경망(NNs)의 정확도 향상에 대해 설명하고 있습니다. 예를 들어, 이미지 및 음성 인식과 같은 일부 기계 학습 응용 프로그램의 오류율이 크게 감소했습니다(예: 26%에서 3.5%로). 그러나 이러한 정확도 향상은 컴퓨팅 요구의 엄청난 증가를 동반합니다. 이에 따라, 특정 영역에 맞춘 하드웨어 가속을 제공하는 맞춤형 ASIC이 필수적이 되었습니다.
2016년 초에 구글이 성공적으로 신경 처리 장치(NPU)를 시연한 이후, 학계와 산업계에서는 NPUs에 대한 관심이 크게 증가했습니다. 이는 CPU나 GPU를 사용하는 전통적인 신경망 추론에 비해 NPUs가 비용-에너지-성능 면에서 가져올 수 있는 엄청난 개선 때문입니다.
NPU의 핵심은 다수의 곱셈-누적(MAC) 단위로 구성된 대규모 배열입니다. 예를 들어, 삼성의 내장 NPU는 1024개의 MAC을 포함하고 있으며, 구글의 TPU는 더 많은 128×128 또는 256×256 MAC 단위를 가지고 있습니다. 이러한 MAC 단위들은 2차원 배열을 형성하여 신경망 추론 실행 과정에서 필요한 계산을 크게 가속화합니다. 그러나 많은 수의 MAC 단위가 상대적으로 작은 영역에 밀집되어 있어, 초당 수 테라의 MAC 연산을 동시에 수행하게 되면, 불가피하게 칩 내부의 과도한 전력 밀도로 인해 열 병목 현상이 발생합니다.
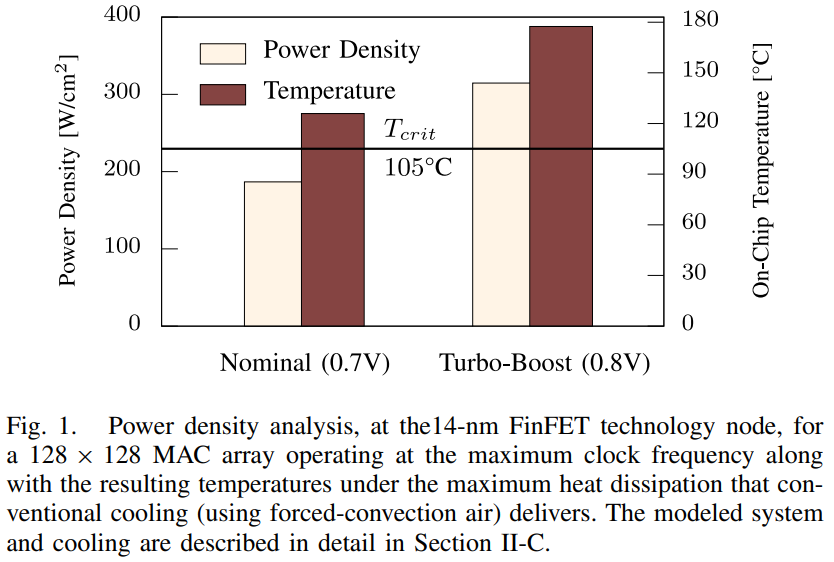
14nm 인텔 FinFET 기술을 사용한 128×128 MAC 배열의 전력 밀도(열 유속) 분석 결과, 최대 클록 주파수에서 187 W/cm²와 312 W/cm²에 달하는 높은 전력 밀도가 관찰되었으며, 이는 일반적으로 인텔에서 정의한 임계 온도 105°C를 넘어서는 지속 불가능한 칩 내 온도를 초래합니다.
이 연구는 전체 칩(즉, RTL에서 GDSII까지) 디자인에 대해 Synopsys 및 Cadence의 상용 사인오프 도구를 사용하여 주파수 및 전력 분석을 수행했습니다. 이러한 온도는 ANSYS의 상용 다중물리학 도구를 사용하여 유한 요소 방법을 사용한 정확한 열 시뮬레이션을 통해 추정되었습니다.
최근 구글의 TPU V3.0의 최신 세대에서는 과도한 칩 내 전력 밀도로 인해 처음으로 액체 냉각이 사용되었습니다. 이는 알파벳 CEO가 기조 연설에서 발표한 바와 같습니다: "이 칩들은 너무 강력하여 우리는 처음으로 데이터 센터에 액체 냉각을 도입해야 했습니다." 우리의 분석은 TPU V3.0 MAC 배열의 전력 밀도가 최대 성능(22.5 TOPS)에서 200 W/cm²에 이르며, 이는 우리가 검토한 MAC 배열에 대해 그림 1에서 제시된 것과 유사함을 보여줍니다. 따라서 구글이 처음으로 액체 냉각으로 전환하기로 한 결정은 NPU의 주파수와 처리량을 극대화하기 위한 고급 냉각 솔루션이 필요함을 더욱 강조합니다.
A. Managing the Temperature of NPUs at Run-Time
이 연구는 신경 처리 장치(NPU) 칩이 실행 중에 다루어야 할 다양한 열 제약(예: 105°C, 85°C, 70°C)에 대해 설명하고 있습니다. 이 열 제약은 NPU가 배치된 컴퓨팅 시스템에 따라 다릅니다. 열 제약이 높을수록 칩의 수명은 단축됩니다. 왜냐하면 칩 내부의 온도가 증가하면 트랜지스터와 회로의 노화가 가속화되기 때문입니다. 실제로, NPU의 최고 온도를 줄이고 열 병목을 제거하기 위해서는 MAC 배열의 온도를 낮춰야 합니다. 이를 위해 MAC 배열이 소비하는 전체 전력을 감소시키거나 더 많은 열을 발산하기 위해 추가적인 냉각이 필요합니다. 다음은 MAC 배열의 온도를 줄이기 위해 실행 중에 사용할 수 있는 세 가지 주요 방법과 그와 관련된 비용을 요약한 것입니다:
- 주파수 스케일링, 처리량과 온도: MAC 배열 전력을 줄이기 위해 클록 주파수를 낮출 수 있습니다. 이는 처리량 감소를 초래하지만, 전력 밀도가 줄어들어 칩 내 온도가 낮아집니다. 대안으로, 배열 내의 일부 MAC 유닛을 전원 차단하여 유사하게 처리량 손실을 대가로 온도를 낮출 수 있습니다. 그러나 전원 차단은 NPU에서 받아들일 수 없는 지연과 관련된 중대한 부담을 추가로 가져올 수 있습니다.
- 정밀도 스케일링, 정확도와 온도: MAC 배열 전력을 줄이기 위해 MAC 유닛의 일부 비트를 클록 차단하여 동적 전력을 줄일 수 있습니다. 이 경우 신경망 추론의 정확도를 희생하여 정밀도가 감소합니다. 정밀도 스케일링(PS)에 대한 민감도는 다양한 신경망 사이에서 크게 다를 수 있으며, 일부는 단일 비트 감소도 견딜 수 없을 수 있습니다.
- 능동 냉각, 전력과 온도: 강제 대류 공기의 최대 능력을 넘어서 열을 발산하기 위해, 칩 패키징 내에 초격자 박막 열전(TE)을 통합한 고급 칩 내 냉각을 사용할 수 있습니다. 이러한 능동 냉각 메커니즘은 신경망 추론의 처리량이나 정확도 손실을 감수할 수 없을 때 필수적입니다.
B. Key Focus of Our Work
이 연구의 주요 목표는 신경 처리 장치(NPU) 칩의 열 문제를 조사하고, 이러한 문제가 곱셈-누적(MAC) 배열의 과도한 전력 밀도에서 비롯되는 것을 파악하는 것입니다. 또한 이로 인해 발생하는 열 핫스팟을 효과적으로 억제하는 방법을 연구합니다. 신경망(NNs)이 MAC 연산에서 정밀도 감소를 견딜 수 있는 능력을 이용하여, 열 제약을 충족시키면서 신경망 추론의 처리량을 최대화하기 위해 정밀도 레벨과 주파수를 조절하는 열 관리 방법을 연구합니다. 또한, 초격자 열전(TE)에 의해 제공되는 고급 칩 내 냉각이 NPU에 어떤 역할을 하는지도 조사합니다.
물리학과 시스템 수준 연결을 통한 정확한 분석:
- MAC 배열의 주파수 및 전력 분석은 Cadence의 상용 표준 사인오프 도구를 사용하여 레이아웃 패러사이트를 포함한 최종 칩 수준에서 수행됩니다. 이 분석은 인텔 14nm FinFET 기술을 기반으로 합니다.
- ANSYS의 상용 다중물리학 도구 플로우를 사용하여 열 및 냉각 시뮬레이션을 수행합니다. 이를 통해 초격자 TE의 효과와 실리콘 다이, 펠티어 효과, TE의 줄 열, 아래쪽 열 유속, 방열판, 공기 대류 간의 복잡한 상호작용을 정확하게 모델링합니다.
- 다양한 신경망의 추론 정확도 분석은 Facebook이 주로 개발한 오픈소스 기계 학습 플랫폼인 Pytorch를 사용하여 수행됩니다.
이 글에서 제시하는 새로운 기여는 다음과 같습니다.
- 정밀도 스케일링(PS), 주파수 스케일링(FS), 초격자 TE가 NPU의 온도 관리에 미치는 영향을 처음으로 조사하고, 각각의 개별 솔루션을 단독으로 적용했을 때의 제한된 능력과/또는 비효율성을 입증합니다.
- NPU를 위한 첫 번째 하이브리드 열 관리 기술(PFS)을 제시합니다. 이 기술은 PS와 FS를 사용하여 온도, 처리량 및 추론 정확도 사이의 타협을 달성합니다.
- 효율성을 더욱 높이기 위해 제안된 PFS 기술에 초격자 TE를 추가하여 하이브리드 PFS-TE를 구현합니다. 그리고 다양한 최적화 시나리오에 대한 파레토 최적 구성을 보여주기 위해 전체 결과 디자인 공간(온도, 처리량, 냉각 비용)을 제시합니다.
- 우리의 PFS-TE(칩 내 냉각을 포함)가 105°C, 85°C, 70°C의 다양한 Tcrit에서 NPU의 효율성을 각각 26%, 65%, 78% 증가시키는 것을 보여줍니다. 이는 추론 정확도의 손실 없이 이루어집니다. 추론 정확도의 일부 손실이 허용되는 경우(기본 신경망의 특성에 따라), 우리의 PFS-TE는 효율성을 최대 2.9배까지 더 향상시킵니다.
2. POWER, TEMPERATURE, COOLING, AND ACCURACY MODELING OF NPU

최근의 연구에서 우리는 신경 처리 장치(NPU)의 열 도전 과제를 탐구하고, 이를 해결하기 위한 포괄적인 접근법을 개발했습니다. NPU에서 발생하는 과도한 전력 밀도와 그 결과로 나타나는 열 핫스팟은 첨단 컴퓨팅 시스템의 성능에 중대한 제약을 가하며, 따라서 효과적인 열 관리 전략의 개발은 필수적입니다.
이 연구는 두 가지 주요한 기술적 측면을 아우릅니다: 칩의 설계 및 레이아웃 최적화와 고급 열 관리 솔루션의 통합입니다. 우리는 PyTorch를 사용하여 신경망을 훈련시키고, Synopsys와 Cadence 도구를 활용하여 14nm FinFET 기술에 기반한 MAC 배열의 전력 및 주파수를 분석했습니다. 추가적으로, 열 시뮬레이션을 위해 ANSYS의 다중물리학 도구를 사용하여 실리콘 다이 내부의 복잡한 열 상호작용을 모델링했습니다.
본 연구의 혁신적인 점은 초격자 박막 열전재료를 이용한 칩 내 냉각 시스템의 도입입니다. 이는 전통적인 냉각 방식을 뛰어넘어 열을 효과적으로 제거할 수 있는 능력을 보여주며, 이를 통해 NPU의 성능과 수명을 향상시키는 새로운 길을 열었습니다.
우리는 또한 정밀도 및 주파수 스케일링을 통해 온도를 관리하고, 신경망 추론의 처리량과 정확도 사이의 균형을 최적화할 수 있는 하이브리드 열 관리 기술을 제시했습니다. 이 기술은 처리량, 온도 및 냉각 비용 간의 파레토 최적화를 실현함으로써, 다양한 최적화 시나리오에 대응할 수 있는 설계 공간을 제공합니다.
결론적으로, 본 연구는 열 관리가 신경망 기반 컴퓨팅의 한계를 극복하고, 성능을 극대화하는 데 있어서 얼마나 중요한지를 입증합니다. 우리의 접근법은 NPU 칩의 효율성을 최대 2.9배 향상시키는 것으로 나타났으며, 이는 고성능 컴퓨팅의 미래를 위한 중요한 발전입니다.
- 시스템 레벨: PyTorch를 사용하여 신경망 학습, 양자화 및 추론을 수행합니다.
- 이미지넷 데이터셋: 대규모 이미지 데이터셋을 학습에 사용합니다.
- 신경망(NN) 학습: 32비트 부동소수점 정밀도로 신경망을 훈련합니다.
- 정밀도 양자화: 다양한 정밀도 레벨(8비트에서 5비트)에 대해 신경망을 양자화합니다.
- 추론 정확도: 여러 정밀도 레벨에서 신경망 추론을 수행하고 정확도를 측정합니다.
- 칩 설계: Synopsys와 Cadence 도구를 사용하여 논리합성과 레이아웃 설계를 합니다.
- 14nm FinFET: 사용되는 기술은 인텔의 14nm FinFET 공정입니다.
- GDSII 구현: 논리합성, 배치 및 경로, 전원 배전 네트워크(PDN) 설계/최적화 및 레이아웃을 통해 GDSII 파일을 구현합니다.
- 레이아웃 후 넷리스트: 배치 후 넷리스트를 추출하여 게이트 레벨 시뮬레이션 준비를 합니다.
- 패러사이트 추출: 레이아웃의 전기적 속성을 반영하기 위해 패러사이트를 추출합니다.
- 게이트 레벨 시뮬레이션: 배치 후 넷리스트를 사용하여 게이트 레벨에서 회로의 시뮬레이션을 수행합니다.
- .vcd 파일: 시뮬레이션 결과를 저장하는 파일 형식입니다.
- 타이밍 및 전력 사인오프: 최종 칩 설계의 타이밍 및 전력 분석을 수행합니다.
- 열 및 냉각: ANSYS 다중물리학 도구를 사용하여 열 및 냉각 시뮬레이션을 수행합니다.
- 초격자 박막 열전재료: 칩 냉각에 사용되는 초격자 박막 열전(TE) 냉각 재료입니다.
- 다양한 냉각 강도 분석: TE에 공급되는 전류량에 따라 다양한 냉각 강도를 분석합니다.
- 온도 분석 및 냉각 비용: 온도를 분석하고 냉각에 드는 비용을 평가합니다.
- 디자인 공간 탐색: 온도, 전력, 냉각 비용, 신경망 처리량 및 정확도 간의 트레이드오프를 탐색합니다.
- MAC 배열 주파수 및 전력 분석: 정밀도 레벨에 따라 MAC 배열의 주파수 및 전력 분석을 수행합니다.
- 입력 추적: 신경망 추론의 정밀도 레벨에 따른 입력 데이터를 추적합니다.
이 연구는 NPU 칩의 전체적인 설계와 열 문제를 해결하는 방법에 대한 큰 그림을 보여줍니다. 주요 세 가지 부분, 즉 1) 전력 및 주파수 분석, 2) 온도 및 냉각 분석, 그리고 3) 신경망(NN) 추론 정확도 분석이 서로 어떻게 연결되는지를 보여줍니다. 우리는 인텔의 14나노미터 FinFET 기술 노드를 사용하여, RTL에서 GDSII 레벨에 이르기까지 전체 MAC 배열의 칩 설계를 수행합니다. 이를 통해 최신 산업 기술을 기반으로 정확한 전력 및 주파수 분석을 추출할 수 있습니다.
전력 추정은 신경망 추론 시뮬레이션에서 추출된 활동 프로파일을 사용하여 게이트 레벨 넷리스트에서 수행됩니다. 다양한 정밀도 레벨에서 전력 추정을 반복하며, 8비트 추론은 32비트 부동소수점 정밀도에 가까운 높은 정확도를 제공하고, 5비트 이하에서는 신경망의 정확도가 매우 떨어지기 때문에 이 범위가 선택되었습니다. 각 설정(주파수 및 정밀도)에 따라 해당하는 전력 밀도(열 유속)가 계산되고, 그 결과로 예상되는 칩 내부 온도를 추정합니다. 온도 추정은 다른 칩 내 냉각 전력(즉, 냉각 비용)에 대해 반복됩니다.
앞서 설명했듯이, 칩 내 냉각은 초격자 열전(TE)을 사용하여 수행되며, 입력 전류는 0A에서 시작하여 7A까지 다양합니다. 여기서 0A는 어떠한 능동 냉각도 적용되지 않을 때의 기준 온도를 나타내며, 7A는 TE 냉각이 포화되어 더 이상의 열 발산을 제공하지 않으며, 오히려 TE 장치 내부의 줄 효과로 인한 추가적인 발열을 유발할 수 있습니다.

파레토 분석은 경제학자 빌프레도 파레토의 이름을 따서 명명된 경제학적 개념으로, 최적화 문제에서 중요한 의사 결정 도구 중 하나입니다. 이 분석은 "80/20 규칙"이라고도 불리우는데, 이는 종종 80%의 결과가 20%의 원인에 의해 발생한다는 일반적인 경험적 법칙을 나타냅니다.
최적화 및 엔지니어링 분야에서 파레토 분석은 서로 상충하는 목표들 사이의 효율적인 균형을 찾는 데 사용됩니다. 예를 들어, 제품 설계에서 비용을 최소화하면서 품질을 최대화하려는 목표가 있을 때, 모든 가능한 설계 옵션들을 고려하여 이 두 목표 사이의 최적의 절충안을 찾는 데 파레토 분석이 사용될 수 있습니다.
파레토 최적화에서는 "파레토 최적"이라는 개념이 중요한데, 이는 어떤 솔루션을 개선하려면 다른 솔루션을 악화시켜야 하는 경우, 즉 한 목표를 개선하는 것이 다른 목표를 희생해야만 가능한 경우를 나타냅니다. 이러한 솔루션들의 집합을 "파레토 프론티어" 또는 "파레토 경계"라고 합니다. 파레토 경계상의 솔루션은 더 이상 어떤 목표도 희생하지 않고는 개선할 수 없는 최적의 솔루션들입니다.
다중 목표 최적화 문제에서 파레토 분석을 사용하면, 각기 다른 목표들 사이의 최적의 균형을 찾을 수 있는 다양한 솔루션들을 식별할 수 있습니다. 이렇게 함으로써 의사결정자들은 가능한 최선의 선택을 할 수 있는 정보를 갖게 됩니다.
A. Chip Modeling: Power, Area, Delay
Technology Modeling and Calibration: 이 작업에서 우리는 우선 BSIM-CMG 모델을 보정합니다. 이것은 FinFET 기술을 위한 업계 표준 컴팩트 모델로, 인텔 14나노미터 FinFET 고부피 생산 공정의 측정치를 재현하기 위해 사용됩니다. 보정은 Synopsys Sentaurus Technology CAD(TCAD)를 사용하여 nFinFET 및 pFinFET 트랜지스터 모두에 대해 수행되며, 이 도구는 반도체 기술의 소자 제작을 시뮬레이션하는 표준 상업용 도구입니다. 그 후, 해당 nFinFET 및 pFinFET 트랜지스터 모델카드가 신중하게 추출됩니다. 이를 통해 인텔 측정치와 매우 잘 일치하는 보정된 SPICE 시뮬레이션을 수행할 수 있습니다. 그림 3에서 보여주듯, 우리의 FinFET 트랜지스터의 전기적 특성(IDS–VGS)은 인텔 14나노미터 측정치와 우수한 일치를 보여줍니다. 보정된 트랜지스터 모델카드를 사용하여, 우리는 Silvaco에서 제공하는 오픈소스 FinFET 표준 셀을 Synopsys SiliconSmart를 사용하여 특성화합니다. 이것은 상업용 셀 특성화 도구입니다. 우리가 생성한 14나노미터 FinFET 표준 셀 라이브러리는 기존의 EDA 도구 흐름과 완전히 호환되므로, 우리는 이를 직접 사용하여 전체 칩 설계뿐만 아니라 최종 레이아웃 넷리스트에 대한 후속 전력 및 타이밍 사인오프를 수행할 수 있습니다.
MAC 배열 칩 설계 및 모델링: 이 작업에서 우리는 구글이 설계한 텐서 처리 장치(TPU) 아키텍처에서 수행한 것처럼 128×128의 순차적 MAC 배열을 고려합니다. 배열의 행과 열은 파이프라인되어 있으며, 각 사이클마다 활성화 값들은 다음 행으로, 누적된 합계들은 다음 열로 전달됩니다. 우리는 산업용 Synopsys DesignWare 라이브러리의 산술 구성 요소를 사용하여 Verilog RTL에서 MAC 배열을 구현합니다. 각 MAC 유닛은 고정 소수점 곱셈기 다음에 고정 소수점 누산기로 구성됩니다. 곱셈기의 크기는 8 × 8이며, 누산 오버플로를 방지하기 위해 덧셈기의 크기는 32비트로 설정됩니다. Synopsys Design Compiler는 최대 가능한 주파수를 얻기 위해 (즉, 제로 슬랙으로) MAC 배열의 중요한 경로 지연에 대해 합성을 사용합니다. 로직 합성은 위에서 언급한 14나노미터 FinFET 표준 셀 라이브러리를 사용하여 수행됩니다. 합성 중에는 Design Compiler의 "compile_ultra" 옵션을 사용하여 최고의 최적화 노력하에 잘 최적화된 넷리스트를 얻습니다.
그 후, 얻어진 게이트 레벨 넷리스트를 사용하여 GDSII 레벨까지 전체 칩 설계가 Cadence 도구 흐름을 사용하여 수행됩니다. 배치 및 경로(즉, 레이아웃 설계)와 전력 전달 네트워크(PDN)는 Cadence Innovus 7.1을 사용하여 수행되며, 후자는 또한 MAC 배열의 최종 칩 면적을 보고하는 데 사용됩니다. 정확한 전력 및 타이밍 분석을 위해 전체 칩의 완전한 RC-패러사이트와 상호 연결이 추출되어 Cadence Tempus Timing Signoff 도구에서 지연 분석 및 Voltus IC Power Integrity 사인오프 도구에서 전력 분석에 사용됩니다. 정확한 전력 추정을 위해, 우리는 신경망 추론 중 PyTorch에서 추출된 대표적인 입력 트레이스를 사용하여 합성된 게이트 레벨 넷리스트의 스위칭 활동을 추출하기 위해 Mentor QuestaSim을 사용합니다. 추출된 스위칭 활동은 최종 레이아웃 넷리스트와 전체 칩의 RC-패러사이트와 함께 전력 사인오프 도구에 공급되어 MAC 배열의 총 전력 소비를 정확하게 추정합니다. MAC 배열의 최종 칩 면적은 Cadence Innovus에 의해 0.157 cm2로 보고되었습니다. MAC 배열이 정상 모드(0.7 V)에서 최대 주파수 1887 MHz로 작동할 때 총 전력은 29.32 W이며, 터보 부스트 모드(즉, 0.8 V에서 2326 MHz)에서는 49 W로 증가합니다. 이는 각각 187 W/cm2 및 312 W/cm2의 전력 밀도를 초래합니다(그림 1 참조).
B. Precision Scaling Modeling Through NN Quantization
PS(Precision Scaling)는 회로의 전력 소비를 줄이기 위해 널리 사용되는 기술입니다. 예를 들어, 입력 비트 수가 적을수록 회로의 스위칭 활동이 줄어들어 동적 전력이 감소합니다. 이 작업에서 우리는 온도 관리 목적으로 정밀도 양자화를 통한 PS를 사용합니다. 실제로, 동적 전력 사용량이 감소함에 따라 MAC 배열의 전력이 줄어들고, 이는 입력(예를 들어, 8비트 기준 대신 6비트 곱셈을 수행하는 것)의 정밀도가 감소함에 따라 결과적으로 칩 온도가 낮아지게 됩니다. 그러나 PS는 입력과 기본 훈련된 NN의 본질에 따라 NN 추론의 정밀도에 영향을 줄 수 있습니다.
NN 양자화 모델링: NN 추론에서 PS를 가능하게 하기 위해, 양자화는 일반적으로 적용됩니다. 양자화 중에는 가중치와 활성화가 32비트 부동소수점 표현에서 더 낮은 정밀도의 숫자 표현으로 변환됩니다. 연구에서는 "INT8"이 FLOAT32와 거의 같은 정확도를 제공하며 다른 것들 중에서도 연산의 복잡성을 줄이는 것으로 나타났습니다. 우리는 Google TPU와 Samsung NPU의 MAC 배열에 비슷한 정밀도 양자화를 적용하여 낮은 전력 및 온도 특성을 달성합니다. 양자화를 적용하면 정밀도가 더 높은 정확도를 나타내지만 양자화를 적용하면 가중치와 활성화가 스케일링되어야 한다는 점을 주목하세요. 정밀도 양자화 전에 Pytorch를 사용하여 NN을 훈련시키고, 이후 n비트 양자화를 적용합니다. 비대칭 최대/최소(post-training quantization method) 양자화 방법을 사용하여 제로 포인트(ZP)를 추가하고, 이 방법으로 FP 표현의 최소 및 최대 값을 해당 정밀도 레벨의 최소 및 최대 범위와 매핑합니다. NN이 훈련된 후에는, 텐서 가중치를 n비트로 양자화합니다. 결과가 정수가 아닌 경우 반올림이 필요합니다.

또한 우리는 같은 데이터셋을 사용하여 각각의 양자화된 표현에 대한 NN 추론 정확도를 분석합니다.
NN 추론 정확도 모델링: Section 5에서 검토된 모든 신경망들은 Pytorch를 사용하여 개발되었으며 32비트 부동소수점 정밀도로 훈련되었습니다. 우리는 평가 데이터셋들[11]에서 해당하는 추론 정확도를 캡처합니다. 우리는 위에서 설명한대로 32비트 부동소수점 표현의 가중치, 편향, 그리고 활성화를 기준인 8비트 정밀도와 더 낮은 정밀도 레벨인 7비트, 6비트, 5비트로 양자화합니다. 그런 다음, 우리는 사용된 동일한 데이터셋에서 각각의 양자화된 표현의 신경망 추론 정확도를 분석합니다.
C. Advanced On-Chip Cooling Modeling
현재와 다가오는 칩에서 사이트 특정적이고 수요에 맞는 냉각이 절실히 필요하기 때문에 고급 칩 내 냉각 기술이 빠르게 등장하고 있습니다. 14나노미터와 그 이하와 같은 작은 기술 노드에서는 실리콘 다이 전체에 걸쳐 열 발생이 매우 불균일하며, 국소적인 열 핫스팟이 열 병목 현상을 일으킬 수 있습니다. 그림 1에서 보여주듯이, NPU 내 MAC 배열의 전력 밀도는 187 W/cm²에 달하고 최대 312 W/cm²까지 올라가는데, 이는 기존의 강제 대류 공기 냉각이 최대 능력에 도달했음에도 불구하고 임계 임계치(예: 105°C)를 초과하는 지속 불가능한 칩 내 온도를 초래합니다. 따라서, 고급 칩 내 냉각 기술을 도입하는 것이 불가피해집니다. 그렇지 않으면, 최대 클록 주파수(즉, 최대 처리량)에서의 운영은 불가능해집니다. 고급 칩 내 냉각은 칩 패키징 내에 초격자 열전(TE) 냉각을 통합하여, 최대 1300 W/cm²까지의 열 유속을 냉각할 수 있는 매우 효율적인 냉각 기능을 제공합니다. 전류가 초격자 TE를 통과할 때, 펠티어 효과로 인해 상부와 하부 표면 사이에 열 그라디언트가 형성되어 효과적인 열 펌핑을 가능하게 합니다.
초격자 TE 모델링: 본 연구에서는 [12] 문헌에 기술된 최신 초격자 TE를 사용합니다. 이는 3×3 TE 커플로 구성되며, 각 커플은 두 개의 다리(n형 및 p형 다리)로 이루어져 있고, 각각의 표면적은 250 마이크로미터 × 500 마이크로미터이며, 두께는 8 마이크로미터입니다. 다리들은 표면적이 580 마이크로미터 × 580 마이크로미터이고 두께가 30 마이크로미터인 구리층으로 연결됩니다. 초격자 TE의 총 면적은 0.03 cm²(1.75 mm × 1.75 mm)입니다. 따라서 칩을 커버하기 위해 5개의 TE가 필요합니다. 재료 의존적 매개변수는 문헌 [12] 및 [13]에서 얻었습니다. 정확한 열/냉각 시뮬레이션 및 현실적 모델링을 위해, 실리콘 칩, 초격자 TE, 열 확산판, 열 싱크로 구성된 전체 시스템 스택을 고려합니다. 열 확산판은 면적이 0.16 cm²이고 두께가 1mm인 알루미늄 판입니다. 열 싱크 역시 알루미늄으로 만들어졌으며, 바닥 면적은 4 cm²(20 mm × 20 mm)입니다. 우리는 공기의 최대 강제 대류를 나타내는 100 W/m²K의 열 전달 계수(HTC)를 고려하여, 기존 냉각이 제공할 수 있는 최대 능력 아래에서 결과적인 온도를 추정합니다. 열 싱크 설계는 모든 핀을 포함하여 상용 열 싱크를 완전히 복제하기 위해 신중한 3D 모델링을 통해 수행되었습니다. 열 싱크의 기본 표면 면적이 4 cm²이지만, 여러 개의 핀으로 인해 총 표면 면적은 3112 mm²에 이릅니다. 이를 통해 검토된 칩에 적합한 열 발산이 가능합니다.
초격자 TE의 존재 여부에 따른 모든 열 및 냉각 시뮬레이션 분석은 유한 요소 방법을 사용하여 수행됩니다. 위에서 설명한 시스템은 ANSYS와 같은 상용 다중물리학 시뮬레이션 도구에서 완전히 구축되었으며, 이 도구는 실리콘 다이, 초격자 TE에서의 펠티어 효과, 전류 흐름으로 인한 TE의 줄 열, 그 아래의 열 유속, 열 확산판/싱크 및 열 싱크 위의 공기 대류 간의 복잡한 상호작용을 정확하게 모델링하는 열 및 열전 툴 플로우를 제공합니다. 수행된 다중물리학 시뮬레이션의 정확도는 관심 있는 문제에 대한 내재된 시간적 및 공간적 해상도가 충분한 메시 크기에 달려 있습니다. 우리는 시뮬레이션의 정확도를 극대화하기 위해 여러 번의 반복 끝에 필요한 메싱을 신중하게 설정했습니다. 우리의 분석은 실리콘 다이, 초격자 TE 장치(TE의 모든 내부 부품 포함), 열 확산판, 열 재료 인터페이스, 여러 핀을 포함한 전체 열 싱크, HTC 등 전체 시스템을 고려하고 시뮬레이션합니다. 이는 다양한 재료 간의 상호작용을 고려하면서 우리의 열 시뮬레이션에서 매우 높은 정확도를 보장합니다. 실제로, 수행된 각 유한 요소 시뮬레이션에서 75,000개 이상의 요소와 노드가 고려되었습니다.
3. NPU THERMAL MANAGEMENT: INDIVIDUAL COOLING SOLUTIONS
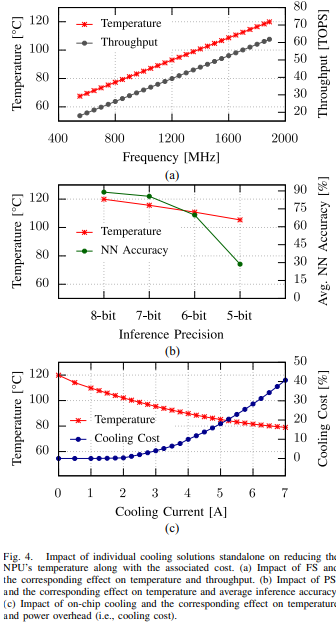
다음에서, 우리는 개별 냉각 솔루션들이 MAC 배열의 온도를 낮추는 데 미치는 영향을 보여줍니다. 따라서 최대 NPU 온도를 미리 정해진 임계 수준(즉, Tcrit) 이하로 유지합니다. 앞서 설명한 바와 같이, 이 작업에서 우리는 세 가지 주요 냉각 솔루션인 FS, PS, 그리고 고급 칩 내(초격자 TE) 냉각에 초점을 맞추고 있으며, 여기서 온도를 관리하는 기본 요소는 각각 MAC 배열의 클록 주파수, MAC 배열의 추론 정밀도, 그리고 적용된 냉각 전력(즉, TE 장치에 공급된 전기 전류)입니다. 이러한 각각의 냉각 솔루션은 각각 처리량 손실, 추론 정확도 손실, 그리고 전력 추가 비용이라는 자체 비용을 수반합니다. 그림 4에서 우리는 앞서 언급한 각 냉각 솔루션을 개별적으로 적용했을 때 온도가 어떻게 감소하는지와 그와 관련된 비용을 보여줍니다. x축은 적용된 열 관리 조절 요소(즉, 주파수, 정밀도, 냉각 전류)를 나타내고, 왼쪽 y축은 결과로 나타나는 온도를 보고하며, 오른쪽 y축은 그 온도 감소를 달성하기 위해 지불해야 하는(즉, 타협해야 하는) 각 비용을 나타냅니다.
'AI' 카테고리의 다른 글
| ChatGPT Prompt (0) | 2024.01.01 |
|---|---|
| ChatGPT Cheat Sheet (0) | 2023.12.31 |
| Kernel Trick (0) | 2023.12.26 |
| [분석] Efficient Execution of Deep Neural Networks on Mobile Devices with NPU (1) | 2023.12.25 |
| AI 생산성 도구 (2) | 2023.12.12 |