1. Abstract
많은 고급 심층 신경망(Deep Neural Network, DNN) 기반 애플리케이션들이 모바일 장치에서 개발되고 실행되고 있습니다. 이러한 고급 DNN 모델들은 더 나은 결과를 제공할 수 있지만, 모바일 장치에서 실행할 때 높은 계산 부담으로 인해 지연 시간이 길어지고 에너지 소
비가 많아집니다. 이러한 문제를 해결하기 위해, 많은 회사들은 모바일 장치용 전용 신경처리장치(Neural Processing Unit, NPU)를 개발했는데, 이는 인공지능 기능을 처리할 수 있습니다. CPU에 비해 NPU는 DNN 모델을 훨씬 빠르게 실행할 수 있지만, 정확도는 낮습니다. 이 문제를 해결하기 위해, 우리는 모바일 장치에서 NPU를 사용하여 DNN 모델의 성능을 향상시키기 위해 모델 파티션 기술을 활용합니다. 도전 과제는 DNN 모델의 어떤 부분을 CPU에서 실행하고 어떤 부분을 NPU에서 실행할지 결정하는 것입니다. 애플리케이션의 지연 시간과 정확도 요구 사항을 바탕으로, 우리는 두 가지 문제를 연구합니다: '최대 정확도(Max-Accuracy)'는 일정 시간 제약 하에 정확도를 최대화하는 것이 목표이며, '최소 시간(Min-Time)'은 정확도가 특정 임계값 이상인 동안 처리 시간을 최소화하는 것이 목표입니다. 이러한 문제를 해결하기 위해, 우리는 간단하지만 DNN 모델 레이어 조합(즉, 어느 레이어를 어디에서 실행할지)을 소수만 검색하는 휴리스틱 기반 알고리즘을 제안합니다. 성능을 더 향상시키기 위해, 우리는 기계학습 기반 모델 파티션(MLMP) 알고리즘을 제안합니다. MLMP는 더 많은 레이어 조합을 검색하고 정확도 손실과 처리 시간을 동시에 고려합니다. 또한, 모바일 장치에서 NPU를 사용하는 모델 파티션 기술을 지원하기 위한 많은 구현 문제를 해결합니다. 실험 결과에 따르면 MLMP는 휴리스틱 기반 알고리즘보다 우수한 성능을 보이며, 애플리케이션 요구 사항에 따라 정확도를 크게 향상시키거나 처리 시간을 줄일 수 있습니다.
NPU (Neural Processing Unit)가 CPU (Central Processing Unit)에 비해 정확도가 떨어지는 이유는 여러 가지가 있습니다. 주요 원인은 다음과 같습니다:
- 특화된 하드웨어 설계: NPU는 딥 러닝과 같은 특정 AI 작업을 위해 최적화되어 설계되었습니다. 이러한 최적화는 종종 속도와 효율성을 중시하며, 때로는 정확도가 소폭 희생될 수 있습니다.
- 낮은 정밀도 연산: 속도와 효율성을 높이기 위해, NPU는 종종 낮은 비트 정밀도를 사용하여 연산을 수행합니다. 예를 들어, NPU는 32비트 부동소수점 연산 대신 16비트 또는 8비트 연산을 사용할 수 있습니다. 이러한 낮은 정밀도는 계산 속도를 높이지만, 때로는 모델의 정확도를 감소시킬 수 있습니다.
- 에너지 효율성: 모바일 기기에서 에너지 사용은 큰 고려 사항입니다. NPU는 에너지 효율성을 높이기 위해 설계되었으며, 이는 때로는 계산 복잡성을 감소시키고 결과적으로 정확도를 약간 희생하는 것을 의미할 수 있습니다.
- 모델 최적화와 압축: 모바일 장치에서 실행 가능하도록, 딥 러닝 모델들은 종종 크기를 줄이기 위해 최적화되거나 압축됩니다. 이러한 과정에서 모델의 복잡성이 감소되어 정확도가 떨어질 수 있습니다.
이러한 제한 사항에도 불구하고, NPU의 사용은 모바일 장치에서 AI 기능을 실행할 때 매우 유용합니다. NPU는 빠른 처리 속도와 낮은 에너지 소비를 제공하여 모바일 환경에서의 딥 러닝 작업을 실질적으로 가능하게 합니다.
2. Introduction
효율적으로 현지에서 DNN(Deep Neural Network) 모델을 실행하기 위해 화웨이, 퀄컴, 삼성과 같은 많은 회사들이 모바일 장치용 전용 신경처리장치(Neural Processing Units, NPUs)를 개발했습니다. 이 NPU를 사용하면 이러한 DNN 모델의 실행 시간을 크게 단축시킬 수 있습니다. 예를 들어, 화웨이 메이트 10 프로(Mate 10 Pro)에서 NPU를 사용하여 ResNet-50(하나의 DNN 모델)을 실행하는 것은 CPU에서 실행하는 것보다 20배 빠릅니다. 비록 현재 NPUs가 고급 휴대폰 모델에서만 사용 가능하지만, 가까운 미래에 다른 모바일 장치나 심지어 사물인터넷(IoT) 장치에도 적용될 큰 잠재력이 있습니다. 예를 들어, 퀄컴 스냅드래곤 855(Qualcomm Snapdragon 855)는 AI 전용 NPU 칩셋을 탑재하고 있고, 삼성은 향후 10년 동안 NPU 기술에 종사하는 직원 수를 10배 증가시킬 계획을 발표했습니다. 화웨이는 이미 현재 및 미래의 스마트폰 모델인 메이트 30 프로(Mate 30 Pro)와 노바 시리즈(Nova series)에 NPU를 배치했습니다.
NPU에는 몇 가지 근본적인 제한 사항이 있으며, 이는 NPU에서 DNN(Deep Neural Network) 모델을 효율적이고 효과적으로 실행하기 위한 연구 과제를 제시합니다. NPU의 가장 중요한 제한 사항은 부동 소수점 숫자의 정밀도입니다. NPU는 CPU에서 32비트를 사용하는 대신 16비트 또는 8비트를 사용하여 부동 소수점 숫자를 표현합니다. 그 결과, NPU는 CPU에 비해 DNN 모델을 훨씬 빠르게 실행하지만 정확도는 떨어집니다. NPU에서 DNN 모델의 정확도를 향상시키는 것은 도전 과제입니다.
이 문제를 해결하기 위해, 우리는 모델 분할 기술을 활용하여 모바일 장치에서 NPU를 사용하는 DNN 모델의 성능을 향상시킵니다. 모델 분할 기술은 [17, 22, 30, 44]에서 연구되었으며, 여기서 DNN 모델은 다양한 레이어로 나누어져 CPU, GPU 또는 클라우드 서버와 같은 다양한 장소에서 실행됩니다. 그러나, 그들의 초점은 계산 시간을 줄이는 것이며, NPU에 의해 도입된 낮은 정확도 문제는 고려하지 않습니다.
모델 분할 기술을 적용하는 주요 도전 과제는 애플리케이션의 처리 시간과 정확도 요구 사항에 기반하여 어떤 레이어를 CPU에서 실행하고 어떤 레이어를 NPU에서 실행할지 결정하는 것입니다. 비행 드론의 예를 고려해 보겠습니다. 드론의 카메라는 비디오를 촬영하고 이를 실시간으로 처리하여 건물에 충돌하거나 나무에 갇히지 않도록 근처 물체를 감지합니다. 어떤 물체도 놓치지 않기 위해서는 감지 결과가 가능한 한 정확해야 합니다. 여기서 시간 제약은 중요하며, 일정 시간 제약 하에 정확도를 최대화해야 합니다. 다른 애플리케이션의 경우, 예를 들어 스마트폰을 잠금 해제하거나 얼굴 인식을 통해 결제를 하는 경우, 처리 시간보다 정확도가 더 중요합니다. 따라서, 정확도가 특정 임계값 이상인 상태에서 처리 시간을 최소화해야 합니다.
다양한 모바일 애플리케이션의 처리 시간과 정확도 요구 사항을 기반으로, 우리는 두 가지 문제를 연구합니다: '최대 정확도(Max-Accuracy)'는 일정 시간 제약 하에 정확도를 최대화하는 것이 목표이며, '최소 시간(Min-Time)'은 정확도가 특정 임계값 이상인 상태에서 처리 시간을 최소화하는 것이 목표입니다.
다양한 DNN 모델 레이어는 서로 다른 부동 소수점 연산을 수행하므로, NPU나 CPU에서 실행될 때 처리 시간과 정확도 측면에서 다른 특성을 가집니다. 일부 레이어는 NPU에서의 낮은 정밀도 부동 소수점 연산에 민감하며, NPU에서 실행될 경우 정확도가 떨어집니다. 다른 일부 레이어는 계산 집약적이며, CPU에서 실행될 경우 처리 시간이 길어집니다. 이 논문에서는 모바일 장치에서 NPU를 사용하여 DNN 모델을 실행할 때 이러한 특별한 특성을 식별합니다. 우리는 '최대 정확도' 문제와 '최소 시간' 문제를 정식화하고, 식별된 특별한 특성에 기반하여 해결하기 위한 휴리스틱 기반 솔루션을 제안합니다. 더 구체적으로, 우리는 모델 분할 기술을 제안하여 지연 및 정확도 요구 사항을 충족하기 위해 어떤 레이어를 CPU에서 실행하고 어떤 레이어를 NPU에서 실행할지 결정합니다.
우리의 휴리스틱 기반 솔루션은 적은 수의 레이어 조합(즉, 어떤 레이어를 어디에서 실행할지)만 시도하기 때문에, 우리는 기계 학습 기반 모델 분할(MLMP) 알고리즘을 제안하여 성능을 더 향상시킵니다. MLMP는 더 많은 레이어 조합을 시도하고 정확도 손실과 처리 시간을 동시에 고려합니다. 이는 기계 학습 기술을 활용하여 레이어 조합으로 DNN 모델을 실행할 때의 정확도 손실을 효율적으로 추정합니다. NPU용 소프트웨어 개발 키트(SDK)에는 NPU에서 레이어 처리 시간을 측정하는 도구가 포함되어 있지 않으며, NPU와 메모리 간의 데이터 전송 시간도 마찬가지이므로, 우리는 이를 더 잘 추정하는 기술을 제안하고, 그런 다음 CPU와 NPU 사이에서 모델 레이어를 어떻게 분할할지 결정합니다. 이는 '최대 정확도(Max-accuracy)' 또는 '최소 시간(Min-Time)'을 위한 것입니다.
이 내용의 요약은 다음과 같습니다:
- 우리는 NPU에서 DNN 모델을 실행할 때 특별한 특성을 식별하여 어떤 레이어를 어디에서 실행할지 결정하는 데 도움을 줍니다. 이는 정확도와 지연 사이의 더 나은 균형을 달성하기 위함입니다.
- '최대 정확도(Max-Accuracy)' 문제와 '최소 시간(Min-Time)' 문제를 정식화하고, 이를 해결하기 위한 휴리스틱 기반 알고리즘을 제안합니다.
- 휴리스틱 기반 알고리즘의 한계를 해결하기 위해, 우리는 성능을 더 향상시키기 위한 기계 학습 기반 모델 분할(MLMP) 알고리즘을 제안합니다.
- NPU가 탑재된 모바일 장치에서 모델 분할을 실현하기 위한 여러 구현 문제를 해결합니다. 광범위한 평가 결과는 MLMP가 애플리케이션 요구 사항에 따라 정확도를 크게 향상시키거나 처리 시간을 줄일 수 있음을 보여줍니다.
논문의 나머지 부분은 다음과 같이 구성됩니다. 2장에서는 NPU에서 DNN 모델을 실행할 때의 특별한 특성을 제시합니다. 3장에서는 '최대 정확도' 문제와 '최소 시간' 문제를 정식화하고, 이를 해결하기 위한 휴리스틱 알고리즘을 제안합니다. 4장에서는 MLMP의 기술적 세부 사항을 제시합니다. 5장에서는 우리 알고리즘의 구현 세부 사항을 제시하고, 6장에서는 평가 결과를 보여줍니다. 7장에서는 관련 연구를 제시하고, 8장에서 논문을 결론짓습니다.
3. PRELIMINARY
3.1 Understanding NPU
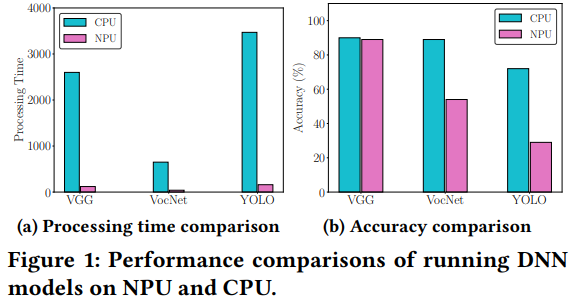
NPU에 대한 더 나은 이해를 위해, 우리는 NPU와 CPU에서 다양한 DNN(Deep Neural Network) 모델을 실행할 때의 정확도와 처리 시간을 비교했습니다. 이 실험은 NPU를 탑재한 화웨이 메이트 10 프로(HUAWEI mate 10 pro)에서 진행되었고, 결과는 그림 1에 나타나 있습니다. 평가에 사용된 세 가지 DNN 모델의 세부 사항은 다음과 같습니다.
- 얼굴 인식에 사용되는 VGG 모델입니다. 실험에서는 LFW 데이터셋에서 얼굴 이미지를 사용했습니다.
- 다중 물체 인식에 사용되는 VocNet 모델입니다. 평가는 VOC 데이터셋에서 선택된 4000개의 물체 이미지를 바탕으로 했으며, 결과는 F1-score를 기반으로 합니다.
- 이미지 내 물체를 탐지하는 데 설계된 YOLO Small 모델입니다. 평가는 MS COCO 데이터셋에서 무작위로 선택된 4000개의 이미지를 바탕으로 했으며, 결과도 F1-score를 기반으로 합니다.
그림 1(a)에서 보듯이, CPU에 비해 NPU에서 VGG, VocNet, Yolo Small을 실행하면 처리 시간을 95%까지 크게 줄일 수 있습니다. 그림 1(b)에서 보듯이, NPU를 사용할 때의 정확도 손실은 DNN 모델에 따라 다릅니다. 예를 들어, CPU에 비해 NPU를 사용할 때 VGG는 비슷한 정확도를 보이지만, VocNet은 30%의 정확도 손실이 있고, YOLO Small을 실행할 때는 F1-score가 0.3으로 떨어집니다.
이 정확도 손실의 주된 이유는 NPU가 FP16 연산만을 지원하고 각 레이어의 중간 결과를 FP16으로 저장하기 때문입니다. FP16을 사용하여 DNN을 실행하면 메모리를 절약하고 처리 시간을 줄일 수 있지만, FP16을 사용할 때의 수치적 불안정성으로 인해 큰 정확도 손실이 발생할 수 있습니다. 이러한 수치적 불안정성은 부동 소수점 오버플로우나 언더플로우에 의해 발생합니다. 일부 모델의 경우, 결과는 NaN이나 0이 될 수도 있어 해석이 불가능합니다.
이것은 텐서플로우 라이트(Tensorflow Lite)와 같은 많은 기존 딥 러닝 프레임워크에서 FP16을 사용하는 것에 대한 일반적인 오해와는 다릅니다. 텐서플로우 라이트에서는 처리 시간을 줄이기 위해 FP16을 사용하지만, 이는 모델 매개변수와 입력 데이터를 저장하는 데만 사용됩니다. 많은 연산, 예를 들어 누적,은 전체 정밀도로 수행되며 중간 결과는 FP32로 저장됩니다.
정확도 손실은 DNN 모델에 따라 다릅니다. VocNet 모델과 Yolo Small 모델은 VGG보다 복잡합니다. VGG는 얼굴 이미지에서 추출된 두 특징 벡터 간의 유사성을 비교하기만 합니다. 유사성이 미리 정의된 임계값 이상이면 두 이미지는 같은 사람에게 속합니다. NPU에 의해 도입된 작은 오류는 특징 벡터의 값들을 변경할 수 있지만, 대부분의 입력 데이터에 대해 유사성과 임계값 간의 관계는 크게 바뀌지 않으므로 CPU와 동일한 수준의 정확도를 가집니다. 그러나 VocNet과 Yolo Small은 이미지 내 다중 물체를 식별하고 위치시키기 위해 특징 벡터의 더 많은 정보를 사용합니다. 특징 벡터의 각 값은 물체의 카테고리, 위치 또는 크기를 나타내며, NPU에 의해 도입된 작은 오류는 예측을 완전히 바꿀 수 있습니다. 결과적으로, 이들은 NPU에서 실행될 때 훨씬 더 낮은 정확도를 가집니다.
그림 1에서 볼 수 있듯이, NPU는 CPU보다 훨씬 빠릅니다. VGG와 같은 일부 DNN 모델을 실행하는 데 NPU를 사용하는 것은 좋은 선택입니다. NPU는 처리 시간을 크게 줄이면서도 높은 정확도를 유지할 수 있습니다. 그러나 VocNet과 Yolo Small과 같은 일부 DNN 모델을 실행하는 데는 최선의 선택이 아닐 수 있습니다. 이는 높은 정확도 손실 때문입니다. 이 문제를 해결하기 위해, 우리는 모델 분할 기술을 제안합니다.
3.2 Motivation
모델 분할에서는 일부 모델 레이어가 CPU에서, 다른 레이어가 NPU에서 실행됩니다. 문제는 어떤 레이어를 CPU에서, 어떤 레이어를 NPU에서 실행할지 결정하는 것인데, 이는 애플리케이션의 정확도와 지연 요구 사항을 충족해야 합니다. 모델 분할에서 중요한 두 가지 요소는 정확도 손실과 레이어 처리 시간입니다. 정확도 손실과 레이어 처리 시간을 측정하기 위해, 우리는 MS COCO 데이터셋에서 무작위로 선택된 4000개의 이미지를 사용하여 화웨이 메이트 10 프로(HUAWEI mate 10 pro)에서 YOLO Small(하나의 DNN 모델)을 사용해 물체를 탐지했습니다.

그림 2는 YOLO Small 모델의 각 레이어를 NPU에서 실행할 때의 처리 시간 감소와 정확도 손실을 보여줍니다. 예를 들어, 레이어 𝑃2를 NPU에서 실행하고 다른 레이어는 CPU에서 실행하면 처리 시간을 6% 줄이고 4%의 정확도 손실을 초래합니다. 직관적으로, 처리 시간을 크게 줄이면서 정확도 손실이 거의 없거나 전혀 없는 레이어(예: 𝐶6)는 NPU에서 실행해야 합니다. NPU에서 실행할 때 정확도 손실이 훨씬 더 높지만 처리 시간 감소는 거의 없는 레이어(예: 𝐶17)는 CPU에서 실행해야 합니다. 그러나 대부분의 레이어(예: 𝐶23)는 이 두 극단적인 경우에 해당하지 않으므로, 이러한 레이어를 어디에서 실행할지 결정하기 어렵습니다. 여러 레이어를 동시에 실행할 때의 중첩 효과를 고려하면 결정은 더 어려워집니다. 예를 들어, 𝐶6과 𝐶22를 NPU에서 실행하고 다른 레이어는 CPU에서 실행할 때의 정확도 손실은 0.08로, 이들의 정확도 손실 합계(즉, 0.04)와 같지 않습니다. 레이어 조합으로 DNN을 실행할 때의 정확도 손실은 각 레이어에서 수행되는 덧셈과 곱셈의 수, 입력/출력 데이터가 차지하는 메모리 공간과 같은 많은 요소에 따라 달라집니다. 정확도 손실과 이러한 요소들 간의 복잡한 관계 때문에, 레이어 조합으로 DNN 모델을 실행할 때의 정확도를 추정하는 방정식을 유도하기는 어렵습니다.
𝑛개의 레이어를 가진 DNN 모델의 경우, 2^𝑛 개의 모델 분할 결정이 있습니다. 고급 DNN 모델의 경우 일반적으로 수십 개 또는 수백 개의 레이어가 있으므로, 최선의 해결책을 찾기 위해 무작위 방법을 사용하는 것은 불가능합니다. 이 문제를 해결하기 위해, 우리는 '최대 정확도(Max-Accuracy)'와 '최소 시간(Min-Time)' 문제를 정식화하고, 이를 해결하기 위한 휴리스틱 기반 알고리즘을 제안합니다. 그런 다음, 성능을 더 향상시키기 위한 기계 학습 기반 모델 분할(MLMP) 알고리즘을 제안합니다."

4. MAX-ACCURACY AND MIN-TIME
4-1. The Max-Accuracy Problem
도입부에서 설명한 시나리오에서, 처리 시간은 드론과 같은 일부 애플리케이션에 있어 중요하며, 우리는 일정한 시간 제약 하에 정확도를 최대화해야 합니다. 이것을 '최대 정확도' 문제라고 합니다. 이 문제를 해결하기 위해, 우리는 먼저 문제를 정의하고 휴리스틱 기반의 해결책을 제안합니다.


4.2 The Min-Time Problem
스마트폰 잠금 해제, 결제 같이 얼굴 인식을 통한 트랜잭션을 수행하는 애플리케이션들에서는 처리 시간보다 정확도가 더 중요합니다. 따라서, '최소 시간' 문제를 연구합니다. 이 문제의 목표는 특정 임계값 이상의 정확도를 유지하면서 처리 시간을 최소화하는 것입니다. 먼저 문제를 정의하고 휴리스틱 기반 해결책을 제시합니다.

5. MACHINE LEARNING BASED MODEL PARTITION (MLMP)
'AI' 카테고리의 다른 글
| ChatGPT Prompt (0) | 2024.01.01 |
|---|---|
| ChatGPT Cheat Sheet (0) | 2023.12.31 |
| Kernel Trick (0) | 2023.12.26 |
| [분석] NPU Thermal Management (0) | 2023.12.25 |
| AI 생산성 도구 (2) | 2023.12.12 |