금융 거래는 뉴스, 가격, K라인 차트를 포함하는 다중 모달 정보 환경에 의해 정보가 제공되는 시장의 중요한 구성 요소이며, 다양한 자산을 이용한 정량적 거래와 고빈도 거래와 같은 다양한 작업을 포함한다. 심층 학습과 강화 학습과 같은 고급 AI 기술이 금융 분야에서 광범위하게 사용되지만, 금융 거래 작업에서의 적용은 다중 모달 데이터 처리의 부적절함과 다양한 작업에 대한 일반화의 한계로 인해 종종 어려움을 겪는다. 이러한 문제를 해결하기 위해, 금융 거래를 위한 도구 보강 다중 모달 기초 에이전트인 FinAgent를 제시한다. FinAgent의 시장 정보 모듈은 수치, 텍스트, 시각적 데이터를 포함한 다양한 데이터를 처리하여 금융 시장을 정확하게 분석한다. 독특한 이중 수준 반사 모듈은 시장 역학에 대한 빠른 적응을 가능하게 할 뿐만 아니라, 다양한 메모리 검색 시스템을 통합하여 에이전트가 과거 데이터로부터 학습하고 의사 결정 과정을 개선할 수 있는 능력을 향상시킨다. 에이전트의 행동에 대한 추론 강조는 금융 결정에 대한 신뢰를 증진한다. 또한, FinAgent는 확립된 거래 전략과 전문가의 통찰력을 통합하여 거래 접근 방식이 데이터 기반이면서도 건전한 금융 원칙에 뿌리를 두고 있음을 보장한다. 주식과 암호화폐를 포함한 6개의 금융 데이터 세트에 대한 포괄적인 실험을 통해, FinAgent는 6개의 금융 지표에서 12개의 최신 기준을 평균 36% 이상의 이익 향상으로 크게 능가한다. 특히, 한 데이터 세트에서 92.27%의 수익(84.39%의 상대적 향상)을 달성한다. 주목할 만하게도, FinAgent는 금융 거래 작업을 위해 설계된 최초의 고급 다중 모달 기초 에이전트이다.
1. Introduction
금융 시장은 경제적 안정성을 위해 필수적이며, 자본 할당과 위험 관리를 촉진한다. 기술적 분석 전략에서 발전된 금융 거래 시스템은 효율적인 거래를 가능하게 하여 이러한 시장을 강화한다. 규칙 기반 거래 시스템은 경직되어 있으며 시장 변동성에 적응하는 데 어려움을 겪어 종종 문제를 일으킨다.

진화하는 시장에서 성과가 저조하다. 강화 학습(Reinforcement learning) 기반 시스템[1]은 적응성이 향상되지만, 광범위한 훈련 데이터의 필요성과 의사 결정 과정의 설명 불가능성 같은 상당한 장애물에 직면한다. 또한, 다양한 시장 조건에 대한 일반화에 어려움을 겪고, 시장 잡음에 민감하며, 뉴스와 보고서 같은 다중 모드 시장 정보를 분석에 통합하는 데 종종 실패한다. 금융 거래 환경은 복잡한 시장 역학을 해결하기 위해 규칙 기반 및 RL 방법의 한계를 넘어서는 더 발전된 기계 학습 방법을 요구한다.
최근 대형 언어 모델(LLMs)은 AI 에이전트에 적용될 때 다양한 의사 결정 작업에서 잠재력을 보여주며, 자연어 처리에서 더 복잡하고 작업별 기능으로의 중요한 확장을 나타낸다 [27, 34, 42, 56]. 이 발전은 메모리와 계획 모듈의 통합을 포함하며, 이러한 에이전트가 인간의 인지 과정과 유사하게 동적 환경에 적응할 수 있게 한다. 이러한 진화는 GPT-4V [25]와 같은 다중 모드 LLM의 출현에 의해 더욱 추진되었으며, 이는 텍스트와 시각적 데이터를 모두 처리하여 LLM의 기능을 향상시킨다. 또한, Toolformer [32]와 같은 도구 보강 모델의 통합은 LLM이 외부 도구를 활용할 수 있게 하여 복잡한 시나리오에서 의사 결정 능력을 높인다. 이러한 적응성과 향상된 처리 능력의 조합은 핀테크와 같은 분야에서 새로운 가능성을 제공하며, 세밀한 분석과 적응이 중요하다.
LLMs는 BloombergGPT [47]와 FinGPT [49]와 같은 개발에서 입증된 바와 같이 금융 데이터를 분석하고 해석하는 데 놀라운 능력을 보여주었다. 그러나 거래에서 QA 작업과 순차적 의사 결정 사이에는 자연스러운 격차가 있다. FinMEM [55]은 인간에 맞춘 메모리 메커니즘과 캐릭터 디자인을 갖춘 LLM 거래 에이전트이지만, 포괄적인 자율 거래 시스템으로서 LLM의 전체 기능은 특히 다중 모드 데이터를 해석하고 다양한 도구를 활용하는 능력에서 아직 충분히 탐구되지 않았다. 금융 시장의 복잡성을 탐색하는 데 있어 다음과 같은 과제가 식별된다:
- Ch1: 불충분한 다중 모드 데이터 처리 능력. 숫자, 텍스트, 시각적 시장 정보 데이터를 처리하는 데 있어 주요 통찰력을 추출하고 시장 동향을 예측하기 위해 고급 분석 방법이 필요하다.
- Ch2: 부정확한 정보 검색. 주요 작업과 검색을 혼합하고 간단한 요약에 의존하면 부정확한 검색이 발생하여 관련 없는 데이터를 도입하고 성능을 저하시킨다.
- Ch3: 빠르게 변화하는 시장에서의 적응성. 금융 거래는 변동하는 시장 조건에 신속하게 적응할 수 있는 능력이 필요하다. 전통적인 방법은 종종 부족하여 실시간 데이터에 대응하고 역사적 시장 동향에 따라 전략을 조정할 수 있는 모델의 필요성을 강조한다.
- Ch4: 도메인 지식의 통합. 현재 모델은 종종 전문가 지침과 고급 거래 도구와 같은 확립된 방법을 효과적으로 통합하는 데 어려움을 겪어 시장 분석의 효과성과 깊이가 감소한다.
- Ch5. 행동에 대한 추론. 많은 정교한 AI 모델의 블랙박스 특성은 의사 결정의 결과를 직접 제공하면서 추론 과정을 제공하지 않는다.
다중 모드 LLM을 동적이고 정보가 풍부한 금융 거래 작업에 적응시키는 과제를 해결하기 위해, FinAgent를 제시한다. FinAgent는 시장 역학과 역사적 거래 패턴에 대한 포괄적인 분석을 위해 텍스트와 시각적 정보를 통합하는 다중 모드 기반 에이전트이다. 구체적으로, FinAgent의 시장 정보 모듈은 숫자, 텍스트, 시각적 데이터를 포함한 다중 모드 데이터를 처리하여 금융 시장 동향에 대한 정확한 분석을 제공하고, 미래 거래 작업에 대한 통찰력을 제공한다 (Ch1). 고유하게 설계된 이중 수준 반사 모듈은 시장 역학에 신속하게 적응할 뿐만 아니라 역사적 데이터로부터 학습하고 의사 결정 과정을 개선하는 에이전트의 능력을 향상시킨다 (Ch2). FinAgent는 시장 정보 및 반사 모듈을 위한 다양한 메모리 검색 시스템을 도입하여 거래 및 검색 작업을 분리하여 특정 기능에 집중하고 결과의 잡음을 최소화한다 (Ch3). 마지막으로, 의사 결정 모듈은 보조 전문가 지침과 보조 전문가 전략을 포함한 전문가 지식을 통합하여 에이전트의 결정을 안내한다. 행동에 대한 이유 있는 설명을 제공하는 데 중점을 두어 금융 결정에 대한 신뢰를 구축한다 (Ch4 & Ch5). 구체적으로, 우리의 기여는 네 가지로 요약된다:
- 자산 가격, 시각적 표현, 뉴스 및 전문가 분석을 포함하는 다중 모드 데이터 세트에서 주요 통찰력을 추출할 수 있는 시장 정보 모듈을 소개한다.
- 거래 작업을 위한 요약을 생성할 뿐만 아니라 검색 작업을 위한 쿼리 필드를 제공한다. 이러한 쿼리 텍스트는 특정 유형의 정보에 집중된 검색을 가능하게 하기 위해 다양한 검색 유형을 포함한다.
- 이중 수준 반사 모듈은 시장 가격 움직임을 분석하여 통찰력을 제공하는 저수준 반사와 과거 거래 결정을 평가하여 개선하는 고수준 반사를 결합하여 의사 결정에서 학습 과정을 모방한다.
- FinAgent에서 전문가 지침과 기술 지표 기반 고급 거래 전략을 포함한 도구 모음을 사용하여 금융 거래에 도메인 지식을 주입한다.
6개의 금융 데이터 세트, 주식 및 암호화폐를 포함한 포괄적인 실험을 통해 FinAgent는 6개의 금융 지표에서 12개의 최첨단 기준을 36% 이상의 평균 수익 향상으로 크게 능가한다. 특히, 한 데이터 세트에서 92.27%의 수익(84.39%의 상대적 향상)을 달성한다. 주목할 만하게, FinAgent는 금융 거래 작업을 위해 설계된 최초의 고급 다중 모드 기반 에이전트이다.
2. 관련 연구
2.1 의사 결정용 LLM 에이전트
인공지능 및 자연어 처리 분야는 ChatGPT [23]와 GPT-4 [24]와 같은 LLM의 출현으로 중요한 이정표에 도달했다. BloombergGPT [47]는 금융 도메인에서 최초의 LLM을 도입하여 금융과 텍스트를 결합했다.

FinGPT는 공개 접근 없이 데이터를 사용하지만, 최초의 오픈 소스 금융 LLM을 제안하며 인간 피드백을 통한 강화 학습을 통합하였다. LLM은 NLP 작업에서 인상적인 성과를 거두었으며, LLM이 단순한 언어 처리기를 넘어 복잡한 작업을 수행할 수 있는 에이전트로 기능할 수 있는 가능성을 탐구하는 연구가 증가하고 있다. AutoGPT, MetaGPT, Voyager, AI 에이전트와 같은 이니셔티브는 LLM의 복잡한 작업 수행 능력을 확장하여 기술을 크게 발전시키고 일상 생활에 영향을 미치고 있다. FinMEM은 자동 거래를 위한 인간 정렬 메모리 메커니즘과 캐릭터 디자인을 갖춘 LLM 에이전트를 제시한다.
최근에는 외부 도구와 모듈식 방법으로 AI 에이전트를 강화하려는 관심이 증가하고 있다. 도구 보강 언어 모델(TALM)은 최근 벤치마크를 통해 평가되었으며, 이는 외부 도구 사용을 요구하는 복잡한 추론 과제를 해결할 수 있는 능력을 평가하기 위해 설계되었다. 이러한 개선은 LLM이 웹 검색을 통해 최신 정보를 검색하고 외부 출처의 전문 지식을 적용할 수 있게 한다. 그러나 LLM 에이전트의 주요 제한점은 텍스트 기반 정보에 의존하여 환경과의 상호작용이 제한된다는 점이다. 시각적 기능을 갖춘 모델의 도입은 중요한 돌파구를 마련하였다. 다중 모달 에이전트는 다중 모달 대형 언어 모델의 시각적 기능을 활용하여 텍스트 전용 에이전트로는 수행할 수 없었던 작업을 수행한다. 대부분의 기존 금융 LLM은 NLP 작업에 중점을 두고 있으며, 거래에서의 잠재력은 충분히 탐구되지 않았다. FinAgent는 금융 거래의 격차를 해소하기 위한 다중 모달, 도구 보강 LLM 기초 에이전트이다.
2.2 금융 거래를 위한 AI
AI 기술은 다양한 금융 거래 작업에 널리 사용되고 있다. RNN 기반의 GRU 및 LSTM 모델은 순차 데이터의 시간적 패턴을 포착하도록 설계되어 주식 예측에 인기가 있다. 또 다른 연구 방향은 주식 간의 쌍별 관계를 모델링하기 위해 그래프 기반 DL 모델을 사용하는 것이다. 예를 들어, Feng 등은 그래프 합성 네트워크(GCN)를 시간적 합성으로 강화하여 주식 간 관계를 탐색한다. Sawhney 등은 주식 산업 데이터와 회사 CEO 간의 연결에 중점을 둔다. 트리 기반 모델도 강력한 성능을 달성한다. Xu와 Cohen은 트윗에서 잠재 정보를 추출하기 위해 변이 오토인코더 아키텍처를 제안한다. Chen 등은 전문 펀드 매니저의 투자 행동을 통해 거래 전략 설계를 강화한다. 경제 뉴스 및 실적 발표와 같은 다른 데이터 소스도 예측 성능을 향상시키는 데 사용된다. Sun 등은 새로운 3단계 앙상블 학습 방법을 도입한다. 강화 학습은 알고리즘, 플랫폼, 평가 도구와 함께 금융에서 성공을 거두었다. 그러나 대부분의 이러한 방법은 가격 데이터에 중점을 두고 일반화가 제한되어 있어 다중 모달 지능을 통합하고 복잡한 시장 역학을 탐색할 수 있는 고급 기술이 필요하다.
3. 문제 공식화
먼저 금융 거래의 마르코프 결정 과정(MDP) 공식화를 소개한다. 이후, 금융 거래에서 유연한 추론과 의사 결정을 가능하게 하는 RL 파이프라인에 LLM을 통합한 FinAgent의 공식적인 공식화를 제공한다.
3.1 금융 거래를 MDP로
금융 거래 작업은 특정 위험 허용 범위 내에서 총 이익을 극대화하기 위해 순차적으로 투자 결정을 내리는 것을 포함한다. 이를 고전적인 RL 시나리오에서 MDP로 공식화하며, 에이전트(투자자)가 환경(금융 시장)과 상호작용하여 이산 시간에 행동(투자 결정)을 하여 보상(이익)을 얻는다. MDP는 5-튜플(S, A, T, 𝑅,𝛾)로 구성된다. 구체적으로, S는 유한한 상태 집합이다. A는 유한한 행동 집합이다. 상태 전이 함수 T: S×A×S →[0, 1]는 선택한 행동에 따라 상태 간 전이 확률을 캡슐화한다. 보상 함수 𝑅: S × A →𝑅는 상태에서 행동을 취할 때의 즉각적인 보상을 정량화한다. 할인 인자는 𝛾∈[0, 1)이다. 정책 𝜋: S × A →[0, 1]는 각 상태 𝑠∈S에 대해 행동에 대한 분포를 할당하며, 𝑎∈A는 확률 𝜋(𝑎|𝑠)를 가진다. 훈련 중 에이전트는 전체 거래 기간 동안 각 시간 단계에서 투자 결정을 내리고, 할인된 보상의 기대 합(전체 이익)을 극대화하는 최적의 정책(투자 전략)을 학습하려고 한다: 𝜋𝜃∗= arg max𝜋𝜃E𝜋𝜃[Í𝑇 𝑖=0 𝛾𝑖𝑟𝑡+𝑖|𝑠𝑡= 𝑠].
구체적으로, 단일 자산(예: 주식 또는 암호화폐) 거래에 중점을 둔다. 상태는 가격 정보, 제한 주문서, 기술 지표, 추세 예측, 금융 뉴스, 전문가의 투자 행동 및 전체 시장 상태를 기반으로 한 금융 시장에 대한 RL 에이전트의 인식을 나타낸다. 행동 공간에는 자산을 매수, 매도 또는 보유하는 세 가지 선택지가 포함된다. 보상 함수는 수수료를 고려하여 시장 자본의 변화(얻은/잃은 돈)를 활용한다.
3.2 문제 공식화
멀티모달 LLMs를 RL(강화 학습) 프레임워크에 통합하여 추론 과정을 유연하게 정의할 수 있게 한다. FinAgent 공식화에서는 이러한 과정을 독립적으로 정의하고 학습하며 적용하는 필요성에 중점을 둔다. FinAgent를 위한 고전적인 RL 최적화 문제를 다음과 같이 확장한다:

여기서 𝑟𝑡는 환경 상태 𝑠𝑡와 행동 𝑎𝑡에 의존하는 시간 단계 𝑡에서의 보상이다. 𝜇(·)는 유익한 내부 추론 과정을 캡슐화하는 특수 모듈이다. 상태는 텍스트, 숫자, 시각적 데이터를 포함한 멀티모달 정보를 포함한다. 작업 𝜆에 직면하고 메모리 𝑀𝑒𝑚𝜆
𝑡와 도구 𝑇𝑜𝑜𝑙𝜆
𝑡를 갖춘 FinAgent는 멀티모달 LLM 에이전트로서 다음 과정을 통해 행동 𝑎𝑡를 결정한다:
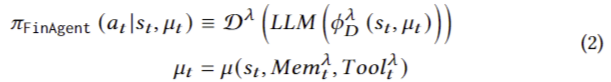
여기서 𝜙(·)는 작업 관련 프롬프트 생성기이다. 프롬프트는 멀티모달 LLM에 전달되어 응답이 생성된다. 마지막으로, 응답은 작업별 행동 파싱 함수 D𝜆(·)를 통해 환경에서 호환 가능한 행동을 수행한다. FinAgent는 이 프레임워크에서 금융 거래를 위해 특별히 설계된 멀티모달 LLMs 에이전트로, 시장 정보 모듈(M), 메모리 모듈(Mem), 저수준 반사 모듈(L), 고수준 반사 모듈(H), 의사결정 모듈(D) 등 다섯 개의 핵심 모듈을 포함한다. 𝜇𝑡와 다른 모듈을 다음과 같이 정의할 수 있다:

여기서 𝑀, 𝑀𝑒𝑚, 𝐿, 𝐻, 𝐷는 각각의 모듈에 해당하며, 𝑀𝑒𝑚∗,𝜆는 𝑀, 𝐿, 𝐻의 메모리를 나타낸다. 𝐾𝐶와 𝑇𝐶는 Kline 차트와 거래 차트를 나타낸다. 𝜙𝜆∗는 작업 𝜆와 관련된 각 모듈에 해당하는 프롬프트 생성기를 나타낸다. 따라서 메모리 메커니즘, 확장된 도구 및 여러 설계된 모듈의 통합으로 FinAgent의 전체 목표는 Eq. (2)에서 설명한 정책을 찾아 총 할인된 수익을 최적화하는 것이다:


| 최신 시장 정보 입력: 일일 주식 뉴스 및 금융 보고서와 같은 최신 시장 정보 프롬프트: 최신 시장 정보 및 가격은 다음과 같음: 애플의 VR 데뷔... 위의 정보를 바탕으로 주요 통찰을 분석하고 시장 정보를 요약해야 함. 다음 제약 조건과 출력 형식을 엄격히 따르시오: “분석”: 이 필드는 위의 정보에서 주요 통찰을 추출하는 데 사용됨. “요약”: 이 필드는 분석을 요약하고 주요 투자 통찰을 추출하는 데 사용됨. “쿼리”: 이 필드는 과거 시장 정보를 검색하는 데 사용됨 |
응답 분석: WWDC에서 새로운 AR/VR 헤드셋이 예상되며, 상당한 관심이 나타남. 요약: 애플의 새로운 AR/VR에 대한 기대감으로 긍정적인 분위기가 지배적임. 중기적으로 시장의 전반적인 분위기는 긍정적임. 쿼리: (다양한 검색 유형에 따라 분리된 검색) - 단기 쿼리: 고객 인출 문제, Meta Quest 3의 경쟁 압력, Apple Reality 관련 뉴스 매도 이벤트 - 중기 쿼리: WWDC 애플 AR/VR 헤드셋 기대 - 장기 쿼리: NSA 스파이 혐의, CEO 급여 조정 및 긴축 |
| 과거 시장 정보 입력: 다양한 검색으로 검색된 과거 시장 정보 프롬프트: 과거 시장 정보 및 가격은 다음과 같음: 애플은 2027년까지 50개의 신규 또는 재건된 소매점을 목표로 함... 위의 정보를 바탕으로 주요 통찰을 분석해야 함... “분석”: 이 필드는 위의 정보에서 주요 통찰을 추출하는 데 사용됨. “요약”: 이 필드는 분석을 요약하고 주요 투자 통찰을 추출하는 데 사용됨. |
응답 분석: 다가오는 애플 이벤트는 흥분을 불러일으킬 수 있으며, AAPL을 기록적인 고점으로 밀어 올릴 가능성이 있음. 기간: 단기. 분위기: 긍정적임. 요약: 애플은 회복력과 혁신 강점을 보여주며, 이는 투자자 신뢰를 유지하고 회사의 시장 가치를 상승시킬 수 있음. |
| 저수준 반영 입력: 최신 및 과거 시장 정보 요약, Kline 차트 및 가격 움직임 프롬프트: 위의 Kline 차트가 보여주듯이, 단기: 지난 1일 동안 가격 움직임 비율이 1.60% 증가를 보였음. 중기... 위의 정보를 바탕으로 과거부터 현재까지의 가격 움직임에 대한 이유를 분석해야 함. “추론”: 이 필드는 거래 결정을 위한 이유를 제공하는 데 사용됨... 위의 정보가 가격 움직임으로 이어진 이유를 결정하기 위한 자세한 추론을 제공해야 함. “쿼리”: 이 필드는 가격 움직임에 대한 과거 추론을 검색하는 데 사용됨. |
응답 추론: AAPL의 단기 가격 상승 1.60%는 애플의 다가오는 AR/VR 제품 라인에 대한 최근 긍정적인 시장 분위기에 기인할 수 있음. 지난 주 동안 AAPL은 3.38% 상승을 보였으며, 이는 새로운 제품 출시 기대감에 긍정적으로 연결됨. 쿼리: AAPL의 가격 단기 성장은 제품 흥분과 우려에 대한 반응에 의해 주도되며, 중기 이익은 긍정적인... |
| 고수준 반영 입력: 최신 및 과거 시장 정보 요약, 저수준 반영의 추론, 거래 차트, 역사적 행동 및 추론 프롬프트: 지난 14일 동안 당신의 조수가 내린 거래 결정과 추론은 다음과 같음: 2023-06-01. 매수. 분석은 강세 미래 추세를 나타내며, 이러한 시나리오에서 매수를 고려할 필요가 있음... “추론”: 각 시점에서 내린 결정이 옳았는지 틀렸는지를 반영하고 이유를 제공해야 함. “개선”: 잘못된 결정이 있다면, 이를 수정하고 수익을 극대화할 가능성이 있는가? 그렇다면 어떻게 수정할 것인가?... “요약”: 성공/실수에서 배운 교훈을 요약하여 미래 거래 결정에 적용할 수 있도록 해야 함. “쿼리”: 이 필드는 결정의 과거 반영을 검색하는 데 사용됨. |
응답 추론: 2023-06-01에 내린 매수 결정은 옳았던 것으로 보임. 이 결정은 시장 분위기와 Kline 차트 분석과 잘 맞아떨어짐. 개선: 그러나 상승 및 하락 시장 신호에 대한 지속적인 경계와 대응이 중요함. 미래 시나리오 균형을 위해, 손실을 줄이기 위한 손절매 설정과 같은 동적 거래 조정이 포함될 수 있음. 요약: 2023-06-01의 매수 결정의 성공은 시장 분석의 중요성을 강조하며, 시장 분위기와 같은 요소를 통합함. 쿼리: 가격 움직임 분석과 기술 지표는 강세 추세에 대한 설득력 있는 사례를 제공하여 매수 행동을 정당화함. |
| 의사 결정 입력: 최신 및 과거 시장 정보 요약, 가격 움직임에 대한 추론, 거래 결정에 대한 요약, 거래자 선호 및 보강 도구. 프롬프트: 위의 정보를 단계별로 분석해야 함. 그리고 자산에 대해 매수, 매도 또는 보유할 이유를 제공해야 함... “분석”: 위의 정보가 결정 결과에 어떻게 영향을 미칠 수 있는지 분석해야 함. 1. 시장 정보 요약을 분석할 때, 시장 정보가 긍정적인지, 부정적인지, 중립적인지를 결정해야 함... “추론”: 현재 관찰에 대한 거래 작업을 실행하기 위한 결정 결과를 결정하기 위한 자세한 추론을 제공해야 함. “행동”: 위의 정보를 함께 고려하여 정확한 매수, 보유 및 매도 결정 결과를 제공해야 함. |
응답 분석: 애플 주식(AAPL)에 대한 전반적인 정보는 중기적으로 긍정적인 분위기를 나타내며, 회사의 새로운 AR/VR 제품 라인에서 긍정적인 영향이 예상됨. 추론: 매수 결정은 여러 요인에 기반함. 첫째, NSA 스파이 혐의와 고객 인출에 대한 부정적인 분위기에도 불구하고, 시장 정보는 주로 애플의 새로운 AR/VR 제품 라인의 예상 영향으로 인해 긍정적이며, 이는 긍정적인 중기 전망에 영향을 미침. 행동: 매수 |
4. FINAGENT 프레임워크
그림 3에 나타난 바와 같이, FinAgent 프레임워크는 다섯 개의 핵심 모듈로 구성된다. 특히, 시장 정보 모듈(§4.1)은 시장 정보 수집, 정리, 요약 및 분석을 담당하며, 여기에는 주식 뉴스, 가격, 월간 및 분기별 재무 보고서에 대한 일일 업데이트가 포함된다. 저수준 반사 모듈(§4.3)은 시장 정보와 가격 변동 간의 내재적 상관관계를 설정한다. 고수준 반사 모듈(§4.3)은 과거 거래 결정의 결과를 바탕으로 시장 상황, 가격 변동 및 기타 요인을 반영하여 이전 경험에서 통찰력을 도출하고, 과거 결정의 효율성을 평가하여 수익성 향상의 잠재성을 식별하고, 향후 의사결정 과정에 대한 권장 사항을 제공하는 것을 목표로 한다. 메모리 모듈(§4.2)의 주요 역할은 앞서 언급한 세 가지 모듈을 지원하기 위해 저장 기능과 벡터 검색 기능을 제공하는 것이다. 도구가 확장된 의사결정 모듈(§4.4)은 앞서 언급한 정보와 확장된 도구 및 거래자의 선호도를 통합하여 종합적인 분석을 통해 최종 투자 결정을 내린다.
4.1 시장 정보 모듈
수익성 있는 투자 결정을 내리기 위해 다양한 멀티모달 금융 데이터 소스에서 주요 통찰력을 수집, 요약, 분석 및 추출하는 것이 유익하다. 시장 정보 모듈을 설계하여 이 목표를 달성한다. 시장 정보는 일반적으로 매크로 환경, 현재 시장 상황 또는 투자자의 감정에 대한 일일 데이터를 포함하며, 이는 투자 및 거래 결정을 알리는 데 사용된다. FinAgent에서는 최신 및 과거 뉴스, 재무 보고서, 대상 자산과 관련된 자산 가격의 힘을 활용하여 거래 결정을 알리고 최적화한다. 최신 시장 정보. 이 모듈은 주로 자산 뉴스와 일일 자산 가격으로 구성된다. 그러나 이러한 요소에만 국한되지 않는다. 시장에 영향을 미치는 모든 정보는 최신 시장 정보의 일부로 프레임워크에 포함될 수 있다. 이 구성 요소의 목표는 각 시장 정보 항목이 미래 자산 가격에 미치는 영향을 평가하고, 시장이 최근에 약세 또는 강세 경향을 보였는지에 대한 자세한 요약을 제공하여 정보에 입각한 의사결정을 지원하는 것이다. 그러나 과거 데이터는 미래 가격에 영향을 미칠 수 있는 패턴에 대한 통찰력을 제공하고 현재 및 향후 시장 역학에 잠재적으로 영향을 미칠 수 있다. 예를 들어, 과거 제품 출시가 회사 주가를 크게 상승시켰다면, 최근 출시도 유사한 효과를 가질 수 있다. 이러한 과거 경험과 패턴을 FinAgent의 고려 사항에 통합하고자 한다. 이는 과거 시장 정보에서 관련 정보를 검색하고, 그로부터 주요 통찰력과 과거 경험을 요약하는 두 가지 추가 기능 계층을 추가하도록 영감을 주었다. 다양화된 검색 작업. 간단한 접근 방식은 최신 시장 정보의 요약을 쿼리 텍스트로 사용하고, LLM을 사용하여 의미적으로 풍부한 임베딩을 추출하는 것이다. 이를 통해 벡터 유사성을 통해 유사한 내용을 가진 과거 시장 정보를 검색할 수 있다. 그러나 이 접근 방식을 채택하면 두 가지 주요 단점이 있다: i) 최근 시장 정보의 요약은 주로 후속 거래 결정 작업을 지원하기 위한 것이며, 검색 작업을 위한 것이 아니다. 이 두 목표 간의 큰 차이는 만족스럽지 않은 검색 결과를 초래할 수 있다; ii) 검색 작업과 관련 없는 일부 노이즈가 요약에 포함될 수 있으며, 이는 검색 결과에 직접적인 영향을 미칠 수 있다. 이러한 문제를 해결하기 위해 FinAgent에서는 다양화된 검색을 구현한다. 구체적으로, 최신 시장 정보 구성 요소의 출력에 검색 작업을 위해 전용된 추가 쿼리 텍스트 필드를 도입하여 거래 작업에 맞춘 요약과 병행하여 검색 작업을 수행한다. 주목할 점은 시장 정보는 시장 인식과 잠재적 결과에 미치는 영향을 기준으로 긍정적, 부정적, 중립적으로 분류될 수 있다. 일부 뉴스는 특정 이벤트 발생 후 회사 주가의 증가 또는 감소 비율을 자세히 설명할 것이다.

다양한 검색 유형을 정의하여 에이전트가 여러 관점에서, 여러 감각으로, 목적을 가지고 과거 시장 정보를 검색할 수 있음을 강조한다. Figure 3에 나타난 바와 같이, 𝑀개의 검색 유형이 있어, 상위 𝐾개의 과거 시장 정보를 개별적으로 검색하여 𝑀× 𝐾개의 과거 시장 정보를 조합할 수 있다. 이 접근 방식은 요약과 함께 각 과거 정보에 특정 검색 유형을 할당한다. 이러한 세밀한 라벨링은 보다 목표 지향적이고 효율적인 검색 및 검색 과정을 촉진한다.
과거 시장 정보. 유사한 과거 시장 정보가 검색되면, 요약 단계가 진행되어 거래 결정을 보강하기 위한 주요 통찰을 제공한다. 이 세심한 접근 방식은 가장 관련성 있는 정보만 통합되도록 하여, 잡음의 영향을 줄이고 거래 전략을 정보하는 데 있어 과거 데이터의 유용성을 극대화한다.
4.2 메모리 모듈
메모리 메커니즘은 LLM 에이전트가 광범위한 텍스트를 효과적으로 처리하고, 문맥을 파악하며, 대화의 일관성을 보장하고, 에이전트의 이해력과 논리적 능력을 향상시키는 데 중요하다. 금융 거래를 위한 다중 모달 LLM 에이전트의 맥락에서, 메모리 메커니즘은 세 가지 주요 측면에서 중요한 역할을 한다: i) 예리함. 이 기능은 다중 모달 LLM 에이전트가 시장 뉴스, 금융 보고서 및 기타 정보를 사용하여 더 나은 시장 예측을 할 수 있게 한다. 과거 데이터와 현재 사건을 분석함으로써, 이러한 에이전트는 시장 동향과 자산 가격을 보다 정확하게 예측하여 효과적인 거래 결정을 돕는다. ii) 적응성. 시장 상황이 빠르게 변함에 따라, 메모리 메커니즘은 다중 모달 LLM 에이전트가 빠르게 배우고 적응할 수 있게 한다. 시장 데이터를 지속적으로 분석하고 거래 결과를 평가함으로써, 이러한 에이전트는 변동성을 처리하고 새로운 기회를 포착하기 위해 전략을 조정한다. iii) 수정 가능성. 이는 다중 모달 LLM 에이전트가 과거의 실수와 성공적인 거래로부터 학습할 수 있게 한다. 이러한 경험을 반영함으로써, 에이전트는 실수를 반복하지 않고 거래 전략을 개선할 수 있다. 이러한 지속적인 학습은 성능을 향상시키고 보다 견고하고 효율적인 거래 전략을 만든다.
3A 우월성 - 예리함, 적응성, 수정 가능성 - 을 메모리 메커니즘에서 실현하기 위해, 메모리 모듈 개발에 벡터 저장 아키텍처를 사용하였다. 이 모듈은 세 가지 주요 구성 요소로 구성된다: 시장 정보 메모리, 저수준 반사 메모리, 고수준 반사 메모리. Figure 3에 나타난 바와 같이, 요약 작업은 각 모듈에 대한 쿼리 텍스트 필드를 생성하여 메모리 저장 및 검색을 향상시킨다. 시장 정보 모듈은 벡터 유사성에 기반한 효율적인 매칭을 위해 벡터 표현을 사용하여 과거 데이터를 고유하게 검색한다. 시장 정보, 저수준 반사, 고수준 반사 모듈의 모든 분석 및 요약은 메모리 모듈에 저장된다. 이 통합은 에이전트에게 광범위한 시장 데이터와 통찰을 제공하여 의사 결정 능력을 향상시킨다.
4.3 반사 모듈
반사 모듈은 인간의 의사 결정에 내재된 인지 학습 과정을 모방하기 위해 에이전트의 설계에 통합된다. 반사 프레임워크는 저수준 반사와 고수준 반사로 나뉘며, 각각 에이전트의 거래 결정을 향상시키기 위한 별개의 목적을 수행한다. 저수준 반사 모듈은 에이전트의 관찰(예: 뉴스, 금융 보고서, Kline 차트 및 기술 지표)과 시장에서의 결과 가격 변동 간의 관계를 반영하여 제공된 정보와 실제 가격 변동 간의 연결을 그린다. 반면, 고수준 반사 단계는 과거 결정을 검토하여 에이전트의 행동과 그에 따른 가격 변동을 추적하여 과거의 성공이나 실수로부터 학습한다.
저수준 반사 모듈의 주요 초점은 주어진 시장 정보와 Kline 차트 및 기술 지표와 과거 및 미래 가격 변동 간의 연결을 분석하여 의사 결정을 향상시키는 것이다. 가격 변동 데이터를 수집한 후, 모듈은 단기, 중기, 장기 관점을 아우르는 다양한 시간적 범위에 대한 상세한 분석을 생성한다.
5. 실험 설정
연구는 FinAgent의 거래 효율성을 철저히 평가하는 것을 목표로 하며, 특히 역사적 데이터 훈련 창을 크게 줄여도 효율적으로 작동할 수 있는 독특한 능력을 강조한다. 이 평가는 정보적 및 에이전트 보조 도구를 포함한 다중 모달 데이터 입력을 활용하고, 다각적이고 다양화된 검색을 포함한다. 이 접근 방식은 시장 역학과 감정을 이해하는 데 도움을 주어 더 포괄적이고 논리적인 의사 결정 과정을 가능하게 하며, 입증된 설명을 제공한다. 효과성을 검증하기 위해 다음 연구 질문(RQ)을 다루는 일련의 실험을 수행하였다:
• RQ1: FinAgent가 현재 최첨단 거래 에이전트를 능가하고 다른 알고리즘이 도전하는 작업을 처리하는가?
• RQ2: FinAgent의 각 구성 요소가 전체 성능에 기여하는 효과는 무엇인가?
• RQ3: FinAgent에 보강 도구를 통합하면 거래 성능이 눈에 띄게 향상되는가?
• RQ4: FinAgent의 다양화된 검색은 얼마나 효과적인가?
5.1
데이터셋
표 3: 각 자산에 대한 데이터 소스의 연대기적 기간과 수를 자세히 설명한 데이터셋 통계.
자산
AAPL
AMZN
GOOGL
MSFT
TSLA
ETHUSD
거래 날짜
2022-06-01부터 2024-01-01까지 (398 거래일)
자산 가격
398 × (시가, 고가, 저가, 종가, 조정 종가)
시각적 데이터
398 × (K선 차트, 거래 차트)
자산 뉴스
9748
10007
7923
8178
10076
2611
전문가 지침
593
509
488
393
600
−
FinAgent를 철저히 평가하기 위해 6개의 실제 데이터셋을 평가한다. 여기에는 미국 주식 시장의 5개 데이터셋과 하나의 암호화폐가 포함된다. 각각은 다양한 출처에서 온 여러 형태의 데이터를 가지고 있다. 구체적으로, i) 일별 자산 가격은 시가, 고가, 저가, 종가, 조정 종가의 가격 데이터를 포함한다. ii) 시각적 데이터는 자산 시장 데이터와 거래 과정을 일일 기준으로 시각적으로 나타내는 역사적 K선 차트와 거래 차트로 구성된다. iii) 자산 뉴스는 Bloomberg Technology, Seeking Alpha, CNBC Television과 같은 다양한 권위 있는 출처에서 일일 업데이트를 제공하여 금융 시장에 대한 다양하고 철저한 관점을 보장한다. iv) 금융 전문가가 제공하는 전문가 지침은 시장 상태에 대한 철저하고 잘 정리된 이해를 제공하기 위한 보조 정보로 제공된다. 6개의 데이터셋 통계를 표 3에 요약하고 부록 B에서 더 자세히 설명한다.
다양화된 포트폴리오에는 Apple Inc. (AAPL), Amazon.com Inc. (AMZN), Alphabet Inc. (GOOGL), Microsoft Corporation (MSFT), Tesla Inc. (TSLA)와 유명한 암호화폐인 Ethereum (ETHUSD)이 포함된다. 이 선택은 다양한 금융 자산에 걸쳐 FinAgent의 다재다능함과 일관성을 보여주기 위한 것이다. 광범위한 뉴스 보도와 다양한 시장 부문을 대표하기 위해 선택된 이 데이터는 다양한 금융 환경에서 FinAgent의 일반화 능력을 평가하기 위한 견고한 기반을 제공한다. 데이터셋 분할의 경우, 연말의 데이터는 테스트(2023-06-01 ∼2024-01-01) 목적으로 할당되며, 전년도의 데이터는 훈련(2022-06-01 ∼2023-06-01) 목적으로 사용된다.
5.2
평가 지표
FinAgent와 기준선을 6개의 금융 지표로 비교한다. 여기에는 1개의 수익 지표: 연간 수익률(ARR), 3개의 위험 조정 수익 지표: 샤프 비율(SR), 칼마 비율(CR), 소르티노 비율(SOR), 2개의 위험 지표: 최대 손실(MDD), 변동성(VOL)이 포함된다. 정의와 공식은 다음과 같다:
• 연간 수익률(ARR)은 연간 평균 수익률로, 𝐴𝑅𝑅= 𝑉𝑇−𝑉0
𝑉0
× 𝐶
𝑇로 계산되며, 여기서 𝑇는 총 거래일 수이고, 𝐶= 252는 연간 거래일 수이다. 𝑉𝑇와 𝑉0는 최종 및 초기 포트폴리오 가치를 나타낸다.
• 샤프 비율(SR)은 포트폴리오의 위험 조정 수익을 측정한다. 이는 𝑆𝑅= E[r]
𝜎[r]로 정의되며, E[·]는 기대값, 𝜎[·]는 표준 편차, r = [𝑉1−𝑉0
𝑉0
, 𝑉2−𝑉1
𝑉1
, ..., 𝑉𝑇−𝑉𝑇−1
𝑉𝑇−1
]𝑇는 수익률의 역사적 시퀀스를 나타낸다.
• 변동성(VOL)은 시간에 따른 투자 수익의 변동을 측정하며, 표준 편차 𝜎[r]로 측정된다.
• 최대 손실(MDD)은 최악의 경우를 보여주기 위해 어떤 정점에서든 가장 큰 손실을 측정한다. 이는 𝑀𝐷𝐷= max𝑇
𝑖=0
𝑃𝑖−𝑅𝑖
𝑃𝑖로 정의되며, 여기서 𝑅𝑖= Î𝑇
𝑖=1
𝑉𝑖
𝑉𝑖−1이고 𝑃𝑖= max𝑇
𝑖=1 𝑅𝑖이다.
• 칼마 비율(CR)은 평균 연간 수익률을 최대 손실과 비교하여 위험 조정 성과를 평가한다. 이는 𝐶𝑅= E[r]
𝑀𝐷𝐷로 정의된다.
• 소르티노 비율(SoR)은 포트폴리오의 하락 위험에 중점을 둔 위험 조정 측정이다. 이는 𝑆𝑜𝑅= E[r]
𝐷𝐷로 정의되며, 𝐷𝐷는 부정적 수익의 표준 편차이다.
5.3
기준선
FinAgent의 거래 성과를 네 가지 널리 인정된 전통적인 규칙 기반 거래 전략(B&H, MACD, KDJ&RSI 및 ZMR)과 여덟 가지 고급 알고리즘과 비교하고 평가한다. 이 중 가격 예측 모델은 기계 학습 및 심층 학습(ML & DL 기반)으로 LGBM[51], LSTM[51], Transformer[51]이 포함된다. SAC [10], PPO [33] 및 DQN [20]은 심층 강화 학습(RL 기반) 방법을 사용한 세 가지 모델이며, FinGPT [49]는 LLM 기반이고, 다른 하나는 LLM 에이전트를 기반으로 한 FinMem [55]이다. 다음은 각 모델에 대한 간략한 소개이다:
• 규칙 기반
– 매수 후 보유(B&H)는 단기 시장 변동에 관계없이 자산을 장기간 보유하여 장기 수익이 더 유리할 것이라고 가정한다.
– 이동 평균 수렴 확산(MACD)은 MACD 지표와 신호선 교차를 사용하여 거래 신호와 시장 동향을 식별하는 기술 분석 도구이다.
– KDJ와 RSI 필터(KDJ&RSI)는 금융 시장에서 정확한 거래 신호를 식별하기 위해 모멘텀 분석을 위한 RSI 지표와 시장 극단을 감지하기 위한 KDJ 지표를 통합한다.
– Z-점수 평균 회귀(ZMR)는 Z-점수의 척도로 시간이 지남에 따라 가격이 평균으로 되돌아갈 것이라고 가정한다.
• ML&DL 기반
– LGBM [51]은 일련의 트리 모델을 사용하여 가격 변동을 예측하고 매수 및 매도 신호를 제공한다.
– LSTM [51]은 장단기 메모리를 활용하여 가격 예측의 정확성을 향상시킨다.
Page 4
--- Page 4 ---
KDD '24, 2024년 8월 25-29일, 스페인 바르셀로나
Wentao Zhang 외
표 4: 여섯 가지 수익성 지표에 대한 모든 방법의 성능 비교. 빨간색, 노란색, 녹색으로 표시된 결과는 각 데이터셋에서 가장 좋은, 두 번째로 좋은, 세 번째로 좋은 결과를 나타낸다. 개선 행은 가장 성능이 좋은 기준선 대비 FinAgent의 개선을 나타낸다.
-
그림 4: 모든 자산에 걸쳐 FinAgent와 다른 벤치마크 간의 시간에 따른 성능 비교.
- Transformer 모델은 가격 예측의 정확성을 높이기 위해 자기 주의 메커니즘을 활용한다.
- RL 기반
- SAC는 오프 폴리시 액터-크리틱 알고리즘으로, 연속적인 행동 공간에서 엔트로피 정규화와 소프트 가치 함수를 사용하여 거래 전략을 최적화한다.
- PPO는 탐색과 활용의 균형을 맞추기 위해 거래 정책을 반복적으로 업데이트하여 안정성과 샘플 효율성을 보장한다.
- DQN은 심층 신경망을 사용하여 행동-가치 함수를 근사하고 시장 데이터로부터 거래 결정을 내린다.
- LLM 기반
- FinGPT는 금융 뉴스와 가격을 금융 결정으로 변환하는 오픈 소스 LLM 프레임워크이다.
- FinMem은 투자 수익을 높이기 위해 미세 조정된 자동 거래를 위한 고급 LLM 에이전트 프레임워크이다.
5.4 구현 세부사항
FinAgent의 훈련과 추론은 GPU 없이도 가능하지만, 벤치마크 방법을 위해 NVIDIA RTX A6000 GPU를 사용하였다. 공정한 비교를 위해 모든 벤치마크는 훈련과 평가 모두 동일한 RL 환경에서 수행된다. FinAgent와 관련된 다음 실험은 특별히 언급되지 않는 한 다양화된 검색을 포함한다. 벤치마크와 실험 설정에 대한 세부사항은 부록에 제공된다.
6 실험 결과
기준선과의 비교 (RQ1). FinAgent를 9개의 기준선 방법과 6개의 금융 지표 측면에서 비교하였다. 표 4와 그림 4는 FinAgent가 기존 기준선을 크게 능가하며, 특히 수익성에서 주목할 만한 개선을 이루고 있음을 보여준다. FinAgent의 전체 결과와 사례 연구는 부록 C에 제공된다. FinAgent의 다섯 주식에 대한 성능은 ARR%와 SR로 측정되며, 각각 가장 성능이 좋은 기준선 대비 최소 10%와 19%의 향상을 보였다. 특히 TSLA 데이터셋에서의 성능은 더욱 두드러져, 84%와 118%의 개선을 이루어 다른 모든 기준선을 크게 능가하였다. 모든 데이터셋에 걸쳐 FinAgent는 수익성 측면에서 시장을 일관되게 능가하는 유일한 방법이다. 반면, FinMem은 AMZN 데이터셋에서 ARR%가 40%로 시장의 매수 및 보유(B&H) 전략의 42%에 미치지 못한다. 이는 다른 기준선에 비해 FinAgent의 우수한 안정성과 견고성을 강조한다. 또한 규칙 기반 방법이 위험을 통제하는 데 최적이지만 수익을 포착하는 데는 뛰어나지 않음을 관찰할 수 있다. 이는 규칙 기반 모델 방법이 데이터의 이상치와 노이즈에 강하여 의사결정 위험을 줄일 수 있기 때문이다. 높은 수익은 종종 높은 위험을 수반한다는 점을 주목할 필요가 있다. 따라서 FinAgent는 위험 통제에 있어 약간의 타협을 나타낸다. 이 결과는 공격적인 거래자를 선호하는 투자자 선호와 관련이 있다.
multimodal foundation agent for financial trading_p09-12
Page 1
--- Page 1 ---
금융 거래를 위한 다중 모드 기반 에이전트: 도구 보강, 다양화, 그리고 일반화
FinAgent는 약간 더 높은 위험을 감수하여 상당히 높은 수익을 달성할 수 있다. 이는 FinAgent가 위험과 보상을 효과적으로 균형 잡아 성능을 최적화할 수 있게 한다. 그림 4는 FinAgent의 성능이 누적 수익 측면에서 다른 방법들을 능가함을 보여주며, 특히 TSLA 데이터셋에서 두드러진다. 시장 정보와 반영 메커니즘을 활용하여 FinAgent는 2023년 9월 14일 이후 주가가 크게 하락할 것을 예측한다. 숏 포지션을 취함으로써 잠재적인 거래 손실을 효과적으로 헤지하고 높은 수익을 창출할 수 있다. 우리의 접근 방식이 암호화폐 ETH에서 FinMem보다 약간 낮은 수익을 내는 것은 주로 보조 에이전트가 주식에 맞춘 전문화된 전략이기 때문이다. FinAgent에 대한 세부적인 연구 결과는 암호화폐에 일반화된 보조 에이전트를 사용하면 현재 44%에서 54%로 수익을 증가시킬 수 있음을 보여준다. 이 중요한 차이는 향후 세부 연구에서 자세히 설명될 것이다.
7
세부 연구
7.1
각 구성 요소의 효과 (RQ2)
표 5에서 시장 정보(M), 저수준 반영(L), 고수준 반영(H), 보강 도구(T)의 효과를 연구한다. M과 ML만 사용하는 것과 비교할 때, 저수준 반영 모듈의 통합은 TSLA와 ETHUSD에서 ARR%를 45%에서 101%로 인상적으로 증가시키고, 위험을 14%에서 44%로 줄인다. ML과 MLH를 비교할 때, 고수준 반영 모듈의 추가는 ARR%와 SR을 크게 향상시키며, 위험을 현저히 줄인다. 이 개선은 TSLA에서 MDD%가 약간 7% 증가하는 작은 대가를 수반한다. MLH와 MLHT를 비교할 때 주식 수익성에서 약간의 개선이 있다. 그러나 보조 에이전트로서 주식에만 특화된 규칙 기반 방법의 도입으로 인해 ETH 암호화폐의 성능이 20% 이상 감소했다.
표 5: 다양한 구성 요소에 대한 세부 연구. √는 FinAgent에 구성 요소를 추가함을 나타낸다. 빨간색과 녹색은 성능 향상과 감소를 나타낸다.
7.2
보강 도구의 효과 (RQ3)
앞서 논의한 바와 같이, 주식 투자에 보조 에이전트를 추가하면 수익이 개선되지만, 암호화폐에서는 상당한 성능 저하를 초래한다. 따라서 보조 에이전트가 규칙 기반 방법으로서 보강 도구로만 결정을 내리는 실험을 수행했다. 다양한 보조 에이전트가 결정과 설명을 제공하는 실험을 수행했다. 이러한 입력은 다른 모듈의 개입 없이 FinAgent의 의사 결정 모듈에 직접 통합된다. 표 4와 표 5에 나타난 바와 같이, T 방법만으로 16%의 ARR%는 ETHUSD에서 B&H의 29% ARR%와 극명한 대조를 이루며, 암호화폐에 대한 주식 특화 규칙 기반 방법의 비효율성을 강조하고 FinAgent에 도입하면 성능에 크게 영향을 미친다. 이는 투자자가 투자 지원을 위해 보조 에이전트를 무분별하게 추가해서는 안 되며, 시장의 특성에 맞는 에이전트를 신중하게 선택해야 함을 시사한다.
7.3
다양화된 검색의 효과 (RQ4)
그림 5(a)에 나타난 바와 같이, AAPL에서 FinAgent의 성능을 다양화된 검색을 사용한 경우와 사용하지 않은 경우를 비교하고, 다양화된 검색의 사용이 ARR과 SR의 명백한 개선에 기여할 수 있음을 발견했다. 그림 5(b)에 나타난 바와 같이, AAPL의 다양화된 검색을 통해 일일로 검증 세트에서 다양한 유형의 시장 정보를 추출하고, 동일한 유형의 동일한 내용을 가진 개체를 필터링했다. LLM이 추출한 임베딩의 t-SNE 시각화를 수행했으며, LLM이 추출한 임베딩이 서로 다른 검색 유형 간에 명확한 구분을 가지고 있음을 발견할 수 있었으며, 이는 우리의 방법의 효과를 입증한다.
8
결론 및 향후 연구
이 논문은 높은 추론 능력과 일반성을 가진 LLM 기반의 금융 거래 에이전트인 FinAgent를 소개한다. FinAgent는 텍스트와 시각 데이터를 모두 통합하는 다중 모드 에이전트로, 시장 역학과 과거 거래 행동에 대한 포괄적인 이해를 가능하게 한다. 이는 다양한 시간 척도에 걸쳐 세부적인 시장 데이터 분석을 위해 보조 도구를 독립적으로 활용하도록 설계되었다. 다각적이고 다양한 검색 접근 방식을 통해 FinAgent는 현재 시장 상황과 과거 시장 패턴 및 추세 간의 상관관계를 효과적으로 식별하고, 시장 정보를 통합하여 최종적이고 효과적인 결정을 내린다. 향후 연구 방향으로는 FinAgent를 포트폴리오 관리와 같은 다른 금융 작업에 적용할 것이며, LLM을 사용하여 관찰된 시장 정보를 바탕으로 각 주식을 순위 매기고 주식을 선택할 것이다.
9
감사의 글
이 프로젝트는 싱가포르의 산업 정렬 기금 – 사전 배치(IAF-PP) 자금 지원 이니셔티브 하에 싱가포르 국가 연구 재단의 지원을 받았다. 이 자료에 표현된 의견, 발견 및 결론 또는 권장 사항은 저자(들)의 것이며 싱가포르 국가 연구 재단의 견해를 반영하지 않는다.
Page 2
--- Page 2 ---
KDD '24, 2024년 8월 25-29일, 스페인 바르셀로나
Wentao Zhang 외
참고문헌
[1] Bo An, Shuo Sun, Rundong Wang. 2022. 정량적 거래를 위한 심층 강화 학습: 도전과 기회. IEEE Intelligent Systems 37, 2 (2022), 23–26.
[2] Chi Chen, Li Zhao, Jiang Bian, Chunxiao Xing, Tie-Yan Liu. 2019. 투자 행동은 내재된 것을 말할 수 있다: 주식 추세 예측을 위한 주식 내재 속성 탐색. ACM SIGKDD 국제 컨퍼런스 지식 발견 및 데이터 마이닝 논문집. 2376–2384.
[3] Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, Tony Xia. 2023. Theoremqa: 정리 기반 질문 응답 데이터셋. arXiv preprint arXiv:2305.12524 (2023).
[4] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann 외. 2023. Palm: 경로를 통한 언어 모델링 확장. Journal of Machine Learning Research 24, 240 (2023), 1–113.
[5] Filippos Christianos, Georgios Papoudakis, Matthieu Zimmer, Thomas Coste, Zhihao Wu, Jingxuan Chen, Khyati Khandelwal, James Doran, Xidong Feng, Jiacheng Liu, Zheng Xiong, Yicheng Luo, Jianye Hao, Kun Shao, Haitham Bou-Ammar, Jun Wang. 2023. Pangu-Agent: 구조적 추론을 갖춘 미세 조정 가능한 일반 에이전트. arXiv:2312.14878 [cs.AI]
[6] Yue Deng, Feng Bao, Youyong Kong, Zhiquan Ren, Qionghai Dai. 2016. 금융 신호 표현 및 거래를 위한 심층 직접 강화 학습. IEEE Transactions on Neural Networks and Learning Systems 28, 3 (2016), 653–664.
[7] Yi Ding, Weiqing Liu, Jiang Bian, Daoqiang Zhang, Tie-Yan Liu. 2018. 투자자 모방자: 거래 지식 추출을 위한 프레임워크. ACM SIGKDD 국제 컨퍼런스 지식 발견 및 데이터 마이닝 논문집. 1310–1319.
[8] Robert D Edwards, John Magee, WH Charles Bassetti. 2018. 주식 추세의 기술적 분석. CRC press.
[9] Fuli Feng, Xiangnan He, Xiang Wang, Cheng Luo, Yiqun Liu, Tat-Seng Chua. 2019. 주식 예측을 위한 시간적 관계 순위. ACM Transactions on Information Systems (TOIS) 37, 2 (2019), 1–30.
[10] Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel 외. 2018. 소프트 액터-크리틱 알고리즘 및 응용. arXiv preprint arXiv:1812.05905 (2018).
[11] Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, Jürgen Schmidhuber. 2023. MetaGPT: 다중 에이전트 협업 프레임워크를 위한 메타 프로그래밍. arXiv:2308.00352 [cs.AI]
[12] Ziniu Hu, Weiqing Liu, Jiang Bian, Xuanzhe Liu, Tie-Yan Liu. 2018. 혼란스러운 속삭임 듣기: 뉴스 지향 주식 추세 예측을 위한 심층 학습 프레임워크. ACM 국제 컨퍼런스 웹 검색 및 데이터 마이닝 (WSDM) 논문집. 261–269.
[13] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu. 2017. Lightgbm: 고효율 그래디언트 부스팅 결정 트리. 신경 정보 처리 시스템의 발전 30 (2017).
[14] Xiao-Yang Liu, Hongyang Yang, Qian Chen, Runjia Zhang, Liuqing Yang, Bowen Xiao, Christina Dan Wang. 2020. FinRL: 정량적 금융에서 자동 주식 거래를 위한 심층 강화 학습 라이브러리. Deep RL Workshop, NeurIPS 2020 (2020).
[15] Yang Liu, Qi Liu, Hongke Zhao, Zhen Pan, Chuanren Liu. 2020. 적응형 정량적 거래: 모방 심층 강화 학습 접근법. AAAI 인공지능 컨퍼런스 논문집, Vol. 34. 2128–2135.
[16] Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, Jianfeng Gao. 2023. Mathvista: 시각적 맥락에서 기초 모델의 수학적 추론 평가. arXiv preprint arXiv:2310.02255 (2023).
[17] Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, Ashwin Kalyan. 2022. 설명을 배우다: 과학 질문 응답을 위한 사고 체인을 통한 다중 모달 추론. 신경 정보 처리 시스템의 발전 35 (2022), 2507–2521.
[18] Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Jianfeng Gao. 2023. Chameleon: 대형 언어 모델을 통한 플러그 앤 플레이 구성적 추론. arXiv:2304.09842 [cs.CL]
[19] Pan Lu, Liang Qiu, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Tanmay Rajpurohit, Peter Clark, Ashwin Kalyan. 2022. 반구조적 수학적 추론을 위한 정책 경사에 의한 동적 프롬프트 학습. arXiv preprint arXiv:2209.14610 (2022).
[20] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller. 2013. 심층 강화 학습을 통한 아타리 게임 플레이. arXiv preprint arXiv:1312.5602 (2013).
[21] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders 외. 2021. Webgpt: 인간 피드백을 통한 브라우저 지원 질문 응답. arXiv preprint arXiv:2112.09332 (2021).
[22] David MQ Nelson, Adriano CM Pereira, Renato A de Oliveira. 2017. LSTM 신경망을 사용한 주식 시장 가격 움직임 예측. 2017 국제 합동 신경망 컨퍼런스 (IJCNN). 1419–1426.
[23] OpenAI. 2021. Chatgpt. https://openai.com/research/chatgpt
[24] OpenAI. 2023. GPT-4 기술 보고서. arXiv:2303.08774 [cs.AI]
[25] OpenAI. 2023. GPT-4V(ision) 시스템 카드. https://openai.com/research/gpt-4v-system-card
[26] Aaron Parisi, Yao Zhao, Noah Fiedel. 2022. Talm: 도구 증강 언어 모델. arXiv preprint arXiv:2205.12255 (2022).
[27] Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, Michael S. Bernstein. 2023. 생성 에이전트: 인간 행동의 상호작용 시뮬라크라. arXiv:2304.03442 [cs.HC]
[28] Molei Qin, Shuo Sun, Wentao Zhang, Haochong Xia, Xinrun Wang, Bo An. 2023. Earnhft: 고빈도 거래를 위한 효율적인 계층적 강화 학습. arXiv preprint arXiv:2309.12891 (2023).
[29] Ramit Sawhney, Shivam Agarwal, Arnav Wadhwa, Rajiv Shah. 2020. 소셜 미디어 텍스트 및 회사 상관관계를 통한 주식 움직임 예측을 위한 심층 주의 학습. 2020년 경험적 방법론을 통한 자연어 처리 컨퍼런스 (EMNLP) 논문집. 8415–8426.
[30] Ramit Sawhney, Piyush Khanna, Arshiya Aggarwal, Taru Jain, Puneet Mathur, Rajiv Shah. 2020. VolTAGE: 수익 발표를 위한 그래프 컨볼루션 네트워크를 통한 텍스트-오디오 융합을 통한 변동성 예측. 2020년 경험적 방법론을 통한 자연어 처리 컨퍼런스 (EMNLP) 논문집. 8001–8013.
[31] Ramit Sawhney, Arnav Wadhwa, Shivam Agarwal, Rajiv Shah. 2021. 자연어를 통한 정량적 일일 거래: 강화 학습을 사용하여. 북미 컴퓨팅 언어학 협회: 인간 언어 기술 2021년 컨퍼런스 논문집. 4018–4030.
[32] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, Thomas Scialom. 2023. Toolformer: 언어 모델이 스스로 도구 사용을 가르칠 수 있다. arXiv preprint arXiv:2302.04761 (2023).
[33] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov. 2017. 근접 정책 최적화 알고리즘. arXiv preprint arXiv:1707.06347 (2017).
[34] Theodore R Sumers, Shunyu Yao, Karthik Narasimhan, Thomas L Griffiths. 2023. 언어 에이전트를 위한 인지 아키텍처. arXiv preprint arXiv:2309.02427 (2023).
[35] Liangtai Sun, Yang Han, Zihan Zhao, Da Ma, Zhennan Shen, Baocai Chen, Lu Chen, Kai Yu. 2023. Scieval: 과학 연구를 위한 다중 수준 대형 언어 모델 평가 벤치마크. arXiv preprint arXiv:2308.13149 (2023).
[36] Shuo Sun, Molei Qin, Xinrun Wang, Bo An. 2023. PRUDEX-Compass: 금융 시장에서 강화 학습의 체계적 평가를 향하여. Transactions on Machine Learning Research (2023).
[37] Shuo Sun, Molei Qin, Wentao Zhang, Haochong Xia, Chuqiao Zong, Jie Ying, Yonggang Xie, Lingxuan Zhao, Xinrun Wang, Bo An. 2023. TradeMaster: 강화 학습으로 강화된 전체론적 정량적 거래 플랫폼. 신경 정보 처리 시스템 데이터셋 및 벤치마크 트랙 제37회 컨퍼런스.
[38] Shuo Sun, Rundong Wang, Bo An. 2023. 정량적 거래를 위한 강화 학습. ACM Transactions on Intelligent Systems and Technology 14, 3 (2023), 1–29.
[39] Shuo Sun, Xinrun Wang, Wanqi Xue, Xiaoxuan Lou, Bo An. 2023. 다양한 거래 전문가의 효율적인 혼합으로 주식 시장을 마스터하기. ACM SIGKDD 지식 발견 및 데이터 마이닝 컨퍼런스 (KDD '23) 논문집. 2109–2119.
[40] Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du 외. 2022. Lamda: 대화 응용을 위한 언어 모델. arXiv preprint arXiv:2201.08239 (2022).
[41] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar 외. 2023. Llama: 개방적이고 효율적인 기초 언어 모델. arXiv preprint arXiv:2302.13971 (2023).
[42] Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, Anima Anandkumar. 2023. Voyager: 대형 언어 모델을 갖춘 개방형 구현 에이전트. arXiv preprint arXiv: Arxiv-2305.16291 (2023).
[43] Jia Wang, Tong Sun, Benyuan Liu, Yu Cao, Hongwei Zhu. 2019. CLVSA: 금융 시장 추세 예측을 위한 주의 기반 변이 시퀀스-투-시퀀스 모델. 국제 합동 인공지능 컨퍼런스 (IJCAI) 논문집. 3705–3711.
[44] Rundong Wang, Hongxin Wei, Bo An, Zhouyan Feng, Jun Yao. 2021. 수수료는 충분하지 않다: 포트폴리오 관리를 위한 계층적 강화 프레임워크. AAAI 인공지능 컨퍼런스 논문집, Vol. 35. 626–633.
[45] Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R Loomba, Shichang Zhang, Yizhou Sun, Wei Wang. 2023. Scibench: 대형 언어 모델의 대학 수준 과학 문제 해결 능력 평가. arXiv preprint arXiv:2307.10635 (2023).
Page 3
--- Page 3 ---
금융 거래를 위한 다중 모달 기초 에이전트: 도구 보강, 다양화, 그리고 일반화
KDD '24, 2024년 8월 25-29일, 스페인 바르셀로나
[46] Zhicheng Wang, Biwei Huang, Shikui Tu, Kun Zhang, 그리고 Lei Xu. 2021. DeepTrader: 시장 조건 임베딩을 통한 위험-수익 균형 포트폴리오 관리에 대한 심층 강화 학습 접근법. AAAI 인공지능 학회 회의 논문집, Vol. 35. 643–650.
[47] Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, 그리고 Gideon Mann. 2023. Bloomberggpt: 금융을 위한 대형 언어 모델. arXiv 사전 인쇄 arXiv:2303.17564 (2023).
[48] Yumo Xu 그리고 Shay B Cohen. 2018. 트윗과 역사적 가격으로부터의 주식 움직임 예측. 컴퓨터 언어학 협회 연례 회의 논문집, Vol. 56. 1970–1979.
[49] Hongyang Yang, Xiao-Yang Liu, 그리고 Christina Dan Wang. 2023. FinGPT: 오픈 소스 금융 대형 언어 모델. arXiv 사전 인쇄 arXiv:2306.06031 (2023).
[50] Hui Yang, Sifu Yue, 그리고 Yunzhong He. 2023. 온라인 의사결정을 위한 Auto-GPT: 벤치마크와 추가 의견. arXiv:2306.02224 [cs.AI]
[51] Xiao Yang, Weiqing Liu, Dong Zhou, Jiang Bian, 그리고 Tie-Yan Liu. 2020. Qlib: AI 지향 정량적 투자 플랫폼. arXiv 사전 인쇄 arXiv:2009.11189 (2020).
[52] Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, 그리고 Lijuan Wang. 2023. MM-REACT: 다중 모달 추론 및 행동을 위한 ChatGPT 프롬프트. arXiv:2303.11381 [cs.CV]
[53] Yunan Ye, Hengzhi Pei, Boxin Wang, Pin-Yu Chen, Yada Zhu, Ju Xiao, 그리고 Bo Li. 2020. 강화 학습 기반 포트폴리오 관리와 보강된 자산 이동 예측 상태. AAAI 인공지능 학회 회의 논문집, Vol. 34. 1112–1119.
[54] Wenhao Yu, Dan Iter, Shuohang Wang, Yichong Xu, Mingxuan Ju, Soumya Sanyal, Chenguang Zhu, Michael Zeng, 그리고 Meng Jiang. 2022. 검색보다는 생성: 대형 언어 모델은 강력한 맥락 생성기이다. arXiv 사전 인쇄 arXiv:2209.10063 (2022).
[55] Yangyang Yu, Haohang Li, Zhi Chen, Yuechen Jiang, Yang Li, Denghui Zhang, Rong Liu, Jordan W. Suchow, 그리고 Khaldoun Khashanah. 2023. FinMem: 계층적 메모리와 캐릭터 디자인을 갖춘 성능 향상 LLM 거래 에이전트. arXiv:2311.13743 [q-fin.CP]
[56] Chi Zhang, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, 그리고 Gang Yu. 2023. AppAgent: 스마트폰 사용자로서의 다중 모달 에이전트. arXiv:2312.13771 [cs.CV]
Page 4
--- Page 4 ---
KDD ’24, August 25–29, 2024, Barcelona, Spain
Wentao Zhang et al.
A
기호의 세부사항
주요 기호를 표 6에 제공한다.
표 6: 논문에서 사용된 기호.
기호
설명
𝑡
현재 날짜
𝑇
총 거래일
𝑡−𝑠,𝑡+ 𝑠
𝑡−𝑠부터 𝑡까지와 𝑡부터 𝑠까지의 단기 가격 분석
𝑡−𝑚,𝑡+ 𝑚
𝑡−𝑚부터 𝑡까지와 𝑡부터 𝑚까지의 중기 가격 분석
𝑡−𝑙,𝑡+ 𝑙
𝑡−𝑙부터 𝑡까지와 𝑡부터 𝑙까지의 장기 가격 분석
S
유한 상태 집합
𝑠𝑡
날짜 𝑡의 상태
A
유한 행동 집합
𝑎𝑡
날짜 𝑡의 행동
T
전이 함수 (Transition function)
𝑅
보상 함수 (Reward function)
𝑟𝑡
날짜 𝑡의 상태 𝑠𝑡와 행동 𝑎𝑡에 대한 보상
𝛾
할인 인자
𝜋
정책
𝜇(·)
추론을 위한 특수 모듈
𝜇𝑡
날짜 𝑡의 특수 모듈
𝜆
금융 거래 과제
𝑀𝑒𝑚𝜆
𝑡
과제 𝜆에서 날짜 𝑡의 메모리
𝑇𝑜𝑜𝑙𝜆
𝑡
과제 𝜆에서 날짜 𝑡의 도구
𝜙(·)
과제 관련 프롬프트 생성기
D𝜆
𝑡
행동 구문 분석 함수
𝑀𝜆
𝑡, 𝐿𝜆
𝑡, 𝐻𝜆
𝑡
M, L, H 모듈
𝜙𝜆
𝑀,𝜙𝜆
𝐿,𝜙𝜆
𝐻
M, L, H에 대한 프롬프트 생성기
𝑀𝑒𝑚𝑀,𝜆
𝑡
, 𝑀𝑒𝑚𝐿,𝜆
𝑡
, 𝑀𝑒𝑚𝐻,𝜆
𝑡
과제 𝜆에서 날짜 𝑡의 M, L, H 모듈의 메모리
𝐾𝐶𝑡
날짜 𝑡의 Kline 차트
𝑇𝐶𝑡
날짜 𝑡의 거래 차트
𝑆𝐿𝑀𝐼𝑡
날짜 𝑡의 최신 시장 정보 요약
𝑄𝐿𝑀𝐼𝑡= {𝑄𝐿
1 , ...,𝑄𝐿
𝑀}
날짜 𝑡의 과거 시장 정보를 검색하기 위한 𝑀개의 쿼리 텍스트
𝐾
검색된 상위 k 항목
𝑄𝑃
𝑖,𝑗
검색 유형 𝑖와 상위 𝑗개의 검색된 과거 최신 정보
𝑆𝑃𝑀𝐼𝑡
날짜 𝑡의 과거 시장 정보 요약
𝐿𝐿𝑅𝑆𝑇
𝑡
, 𝐿𝐿𝑅𝑀𝑇
𝑡
, 𝐿𝐿𝑅𝐿𝑇
𝑡
단기, 중기 및 장기 영향에 대한 저수준 반영 결과
𝑄𝐿𝐿𝑅𝑡
날짜 𝑡의 저수준 반영을 위한 쿼리 텍스트
𝑃𝐿𝐿𝑅𝑆𝑇
𝑡
, 𝑃𝐿𝐿𝑅𝑀𝑇
𝑡
, 𝑃𝐿𝐿𝑅𝐿𝑇
𝑡
단기, 중기 및 장기에서 검색된 상위 k 저수준 반영
𝐻𝐿𝑅𝑡
날짜 𝑡의 고수준 반영 결과
𝑄𝐻𝐿𝑅𝑡
날짜 𝑡의 고수준 반영을 위한 쿼리 텍스트
𝑃𝐻𝐿𝑅𝑡
날짜 𝑡의 검색된 상위 k 고수준 반영
B
데이터셋 및 처리의 세부사항
FinAgent의 철저한 평가를 위해 6개의 실제 데이터셋을 평가한다. 여기에는 미국 주식 시장의 5개 데이터셋과 암호화폐 1개가 포함된다. 각각은 다양한 출처에서 온 여러 형태의 데이터를 포함한다. 구체적으로, i) 일별 자산 가격, 개장, 최고, 최저, 종가 및 조정 종가의 가격 데이터 포함; ii) 시각적 데이터는 자산 시장 데이터와 거래 과정을 일별로 시각적으로 나타내는 역사적 Kline 차트와 거래 차트로 구성된다; iii) Bloomberg Technology, Seeking Alpha, CNBC Television 등 다양한 권위 있는 출처에서 매일 업데이트되는 자산 뉴스 보도를 통해 금융 시장에 대한 다양하고 철저한 관점을 보장한다; iv) 금융 전문가가 제공하는 전문가 지침은 시장 상태에 대한 철저하고 균형 잡힌 이해를 제공하기 위한 보조 정보로 제공된다. 6개의 데이터셋 통계를 표 3에 요약하고 이를 다음과 같이 자세히 설명한다.
'AI' 카테고리의 다른 글
| Trading Agent: 다중 에이전트 LLM 금융 거래 프레임워크 (5) | 2025.03.13 |
|---|---|
| SEC F-13 Report Download (0) | 2025.03.11 |
| Moat 분석을 위한 10-K 보고서의 키워드 기반 평가 방법 (1) | 2025.03.11 |
| Agentic AI: 자율성과 적응성을 갖춘 차세대 인공지능 (0) | 2025.03.08 |
| Algorithmic Trading and Financial Forecasting Using Advanced AI Methodologies (0) | 2025.03.07 |