Here's a detailed guide designed for university students who are new to SoC, explaining how to use a multicore cache behavior simulator. This guide includes the simulation's purpose, detailed technical descriptions of each component, how to run the code, and how to analyze the results.
1. Purpose of the Simulator This simulator is a tool for understanding cache operations and bus arbitration algorithms in multicore processors. Each core manages its own cache and processes memory access requests through a bus. The simulation allows you to observe firsthand how cache coherence is maintained and how data synchronization issues are handled in a multicore environment.
2. Simulation Component Descriptions (1) CacheLine Class -Purpose: Models an individual cache line within the cache system. A cache line is the basic unit for storing blocks of data in memory. -Attributes: -`state`: Indicates the current state of the cache line.
Possible states include `Invalid`, `Shared`, `Exclusive`, and `Modified`. - `data`: Represents the actual data stored in the cache line.
(2) Bus Class -Purpose: Models the role of a bus that mediates data transfers between the CPU and memory. In multicore systems, the bus is a critical component for managing cache coherence and data synchronization. -Methods: -`broadcast(sender, address, action)`: Alerts other CPUs when a particular CPU requests data, facilitating appropriate actions to maintain coherence.
(3) BusArbitrator Class - Purpose: Ensures fair bus access across multiple cores in a multicore system. - Functionality: Uses a round-robin algorithm to sequentially allocate bus access to each CPU.
(4) CPU Class - Purpose: Represents each core in a multicore processor. Operates as a separate thread, independently simulating memory access requests. - Methods: - `run()`: Main execution function of the CPU thread, simulating various memory access requests. - `access_memory(address, mode)`: Handles cache hits or misses based on the given address.
3. How to Run the Code 1. Install Python: Ensure Python is installed on your system. 2. Create Code File: Save the above code as `cache_simulation.py`. 3. Execute Code: Run the script by typing `python cache_simulation.py` in the terminal. 4. Check Log Files: After execution, review the log file generated. The log file is saved in the same directory as the script with the format `cache_simulation_YYYY-MM-DD_HH-MM-SS.log`.
4. How to Analyze Results - Log File Analysis: Check each CPU's cache hits, misses, snooping events, and clock cycles in the log file. -Performance Metrics: Calculate the total clock cycles and average latency for each CPU from the logs to assess the overall system performance.
This guide aims to provide students with a deeper understanding of the complexities of multicore systems and cache management, bridging theoretical knowledge with practical operation to enhance the learning experience.
SystemC는 C++을 사용한 하드웨어 모델링을 위한 무료 라이브러리입니다. 처음에는 OSCI(Open SystemC Initiative)에 의해 홍보되었고, 현재는 Accellera에서 제공되며 IEEE-1666 표준으로 지정되어 있습니다. 각 하드웨어 구성 요소는 하위 구성 요소를 포함할 수 있는 C++ 클래스에 의해 정의됩니다. SystemC는 TLM(Transaction Level Modelling)과 net-level 모델링의 혼합을 지원하며, 시뮬레이션 및 합성(synthesis)에도 사용할 수 있습니다. 원래는 C++ 내에서 디지털 로직을 표현하기 위한 RTL-equivalent 방법으로 설계되었습니다.
SystemC 핵심 라이브러리의 주요 요소:
모듈 시스템 및 inter-module 채널: C++ 클래스 인스턴스는 회로 구성 요소 구조에 따라 계층적으로 인스턴스화됩니다. 이는 RTL 모듈이 서로 인스턴스화되는 방식과 유사합니다.
유저 스페이스에서 실행되는 커널: 이 커널은 시스템 시간, 시뮬레이션 일시 정지, 이름 해석 기능을 제공합니다. VHDL의 상세한 의미론을 대략적으로 따르는 EDS(Event-Driven Simulation) 이벤트 큐를 구현하며, 이벤트 알림과 쓰레드를 제공합니다. 이 쓰레드들은 선점형(preemptive)이 아니므로, 데이터 구조 잠금에 대해 경량 접근 방식을 사용할 수 있지만, 다중 코어 워크스테이션에서 SystemC를 실행할 때 문제가 발생할 수 있습니다.
compute/commit 신호 패러다임: 이 패러다임은 zero-delay 모델의 클럭 도메인에서 shoot-through 현상을 피하기 위해 필요합니다. 이 현상은 하나의 flip-flop이 이전 값을 읽기 전에 다른 flip-flop이 출력을 변경할 때 발생합니다.
임의의 고정 소수점 정수 라이브러리: 하드웨어는 다양한 너비의 버스와 카운터를 사용하는데, SystemC는 이와 동일하게 동작하는 다양한 너비의 부호 있는(signed) 및 부호 없는(unsigned) 변수를 제공합니다.
파형 출력 기능: 파형을 파일에 캡처하고, 이를 gtkwave와 같은 표준 파형 뷰어 프로그램에서 볼 수 있도록 합니다.
SystemC의 문제점:
Reflection API 부족: C++에는 Python과 같은 reflection API가 없기 때문에, 런타임 오류 보고나 기타 정적 분석(static analysis)을 수행하는 것이 어렵습니다. 이를 극복하기 위해, SystemC 코딩 시 구조를 문자열로 주석 처리해야 하는 경우가 있지만, C 전처리기를 사용해 식별자의 중복 입력을 최소화할 수 있습니다.
C++ 전문성 부족: 하드웨어 엔지니어들이 C++에 익숙하지 않은 경우가 많아, 라이브러리를 잘못 사용하면 복잡하고 난해한 C++ 오류 메시지를 접할 수 있습니다.
SystemC의 주요 장점:
뛰어난 성능: C++로 코딩된 것은 본질적으로 매우 뛰어난 성능을 제공합니다.
산업 표준: SystemC는 전자 설계 자동화(EDA) 산업에서 채택된 표준입니다. 애플리케이션 코드와 디바이스 드라이버를 포함한 일반적인 동작 코드가 이 공통 언어로 모델링 및 구현됩니다.
SystemC는 SC_MODULE 및 SC_CTOR 매크로를 사용해 컴포넌트를 정의할 수 있습니다. 예를 들어, 바이너리 카운터를 SC_MODULE로 정의하고, SC_CTOR를 사용해 생성자를 만듭니다. SC_METHOD를 사용해 클럭 엣지마다 호출되는 동작을 정의할 수 있습니다. 예제는 10비트 바이너리 카운터를 SystemC 클래스 모듈로 코딩한 것입니다.
SystemC 구조적 netlist
SystemC에서 templated 채널은 컴포넌트 간의 일반적인 인터페이스입니다. sc_in, sc_out, sc_signal과 같은 파생 형태를 주로 사용합니다. 이들은 delta 사이클을 위해 compute/commit 패러다임을 구현하여, zero-delay 모델에서의 레이싱 불확실성을 피합니다.
Schematic (left) and SystemC structural netlist (right) for a 2-bit shift registe
SystemC 쓰레드와 메소드
SystemC는 사용자가 모듈에 자신의 쓰레드와 스택을 가질 수 있도록 합니다. 메모리 풋프린트가 적으므로, non-blocking upcalls만 사용하는 trampoline 스타일로 작동하는 것이 바람직합니다. 효율성을 위해, SC_METHOD를 가능한 한 자주 사용하고, SC_THREAD는 프로그램 카운터에 중요한 상태를 유지해야 할 때나 비동기적(active) 동작이 필요할 때 사용해야 합니다.
SystemC Plotting 및 GUI
SystemC는 파형을 Verilog Change Dump (VCD) 파일에 덤프해 나중에 gtkwave나 ModelSim 등의 시각화 도구로 볼 수 있도록 지원합니다. VCD 파일은 net 이름과 이들의 값 변화 목록을 타임스탬프와 함께 저장합니다.
더 큰 모델링 효율성을 향하여
SystemC 채널을 통해 커널 작업당 더 많은 데이터를 전달하는 접근 방식은 더 큰 모델링 효율성을 제공합니다. 예를 들어, capsule 구조체를 정의하고, 이를 통해 두 개의 정수를 한 번에 전송할 수 있습니다. 이는 트랜잭션 모델링의 한 걸음입니다.
이처럼 SystemC는 하드웨어 설계와 모델링에 유용한 도구이며, C++의 강력한 기능을 활용해 다양한 모델링과 시뮬레이션 요구사항을 충족할 수 있습니다. 그러나 C++에 대한 깊은 이해가 필요하며, 이를 효과적으로 사용하기 위해서는 숙련된 엔지니어링 지식이 필요합니다.
interconnect 모델은 SoC 설계 초기 단계에서 실제 interconnect를 설계하기 전에 성능을 분석하고, 최적화하기 위해 사용됩니다. 또한, 이러한 모델은 전체 SoC를 ESL(Electronic System Level)로 모델링할 때 현실적인 지연 시간을 예측하는 데 도움이 됩니다. 상세한 interconnect 모델은 생산 단계에서 발생한 문제를 복제하고, 이를 해결하기 위한 연구에 사용될 수도 있습니다.
interconnect 모델링의 주요 개념
Packetised Networks on Chip (NoC)와 전통적인 Circuit-Switched interconnect는 모두 queuing(큐잉)과 arbitration(중재)를 포함하는 discrete event(이산 이벤트)를 처리합니다. 이러한 이유로, 두 시스템 모두에 같은 모델링 기법을 적용할 수 있습니다.
interconnect 모델링의 종류
interconnect 모델링은 매우 추상적인 수준에서부터 상세한 수준까지 여러 단계로 나눌 수 있습니다:
High-level static analysis: 트래픽 흐름 행렬을 사용하여 간단한 스프레드시트(또는 이와 유사한 도구)를 통해 모델링합니다. 이 방법은 초기 설계에 적합하며, TLM(Transaction Level Modelling) 모델에 기본적인 지연 시간을 추가할 수 있습니다.
Virtual queuing: 실제 queue 모델이나 지연 시간을 포함하지 않고 트랜잭션을 전파합니다. 그러나, 트래픽이 각 중재 지점에서 어떻게 변동하는지는 정확하게 반영됩니다. 이 방법은 TLM 모델에서 사용되며, 트랜잭션 지연 필드에 지연 패널티를 추가합니다.
TLM queuing: 스위칭 요소의 high-level 모델이 트랜잭션 queue를 포함합니다. 이 방식에서는 TLM 블로킹 코딩이 필요합니다.
Cycle-accurate modelling: 클럭 사이클 단위로 정확한 시뮬레이션을 수행합니다. 이 방식은 TLM이나 RTL(Register Transfer Level) 수준에서 이루어질 수 있습니다.
Stochastic Interconnect Modelling
네트워크 설계 분야에서는 다양한 유형의 랜덤 트래픽을 모델링하는 데 많은 연구가 이루어졌습니다. Markov process(마코프 과정)을 기반으로 한 모델은 매우 유용한 분석 도구입니다. 이러한 모델은 시스템의 현재 상태만으로 다음 상태를 예측할 수 있는 특성을 가지고 있으며, 독립적인 트래픽 소스와 라운드 트립 지연과 관계없는 부하가 있을 때 효과적으로 작동합니다.
하지만, Markov 모델은 실제 생산 칩에서 발생하는 특정 문제를 해결하는 데는 항상 도움이 되지 않습니다. 예를 들어, 트래픽 패턴의 상관관계가 높은 경우에는 Markov 모델이 잘못된 결과를 제공할 수 있습니다.
Cycle-accurate Interconnect Modelling
Cycle-accurate 모델링은 가장 상세한 수준의 interconnect 모델링입니다. 이 모델은 각 개별 트래픽 흐름을 클럭 사이클 단위로 정확하게 시뮬레이션하며, 이는 특히 여러 트래픽이 동일한 NoC virtual channel을 공유할 때 중요합니다. 예를 들어, 두 개의 패킷이 동시에 스위칭 요소에 도착하면 arbitration이 필요해 지연이 발생하지만, 순차적으로 도착하면 이러한 지연이 발생하지 않습니다.
전체 interconnect를 Cycle-accurate 수준에서 모델링하려면, 각 서브 모델이 Cycle-accurate 수준으로 동작해야 합니다. 입력 자극은 실세계 시스템에서 얻은 트레이스 자료 또는 인공적으로 생성된 시나리오를 사용할 수 있습니다.
경우에 따라 여러 클럭이 사용되거나 클럭 엣지의 세부 사항을 정확하게 모델링해야 하는 상황이 있을 수 있습니다. 이 경우에는 Cycle-accurate 모델만으로는 문제의 세부 사항을 충분히 포착하지 못할 수 있습니다.
요약
interconnect 모델링은 SoC 설계에서 매우 중요한 역할을 합니다. 모델링은 설계 초기 단계에서 성능을 최적화하고, 생산 단계에서 발생할 수 있는 문제를 해결하는 데 사용됩니다. interconnect 모델은 high-level의 정적 분석에서부터 Cycle-accurate 모델링에 이르기까지 다양한 수준에서 수행될 수 있으며, 각 수준은 특정 설계 목표와 요구에 따라 선택될 수 있습니다.
Packetised Networks on Chip (NoC)와 전통적인 Circuit-Switched interconnect는 SoC(System on Chip) 설계에서 데이터 전송을 관리하는 두 가지 주요 방식입니다. 이들은 각각 고유한 특징과 장단점을 가지고 있으며, 특정 설계 목표와 요구사항에 따라 선택됩니다. 아래에 각각의 특징과 장단점을 자세히 설명하겠습니다.
Packetised Networks on Chip (NoC)
특징:
패킷 기반 데이터 전송: NoC에서는 데이터가 작은 패킷으로 분할되어 전송됩니다. 각 패킷에는 목적지 주소와 같은 메타데이터가 포함되어 있어, 네트워크 내에서 독립적으로 라우팅됩니다.
동적 라우팅: NoC는 네트워크 내의 라우터를 통해 패킷을 동적으로 라우팅합니다. 이는 네트워크의 상태에 따라 패킷이 다른 경로를 선택할 수 있음을 의미합니다.
유연한 구조: NoC는 다양한 토폴로지(예: 메쉬, 링, 트리 등)를 지원하여 시스템 요구사항에 따라 설계될 수 있습니다. 이로 인해 설계 유연성이 높습니다.
확장성: NoC는 네트워크의 규모에 따라 쉽게 확장될 수 있으며, 복잡한 SoC에서도 효율적으로 동작합니다.
장점:
높은 유연성: NoC는 다양한 토폴로지를 지원하고, 동적 라우팅을 통해 네트워크 혼잡을 줄일 수 있어 설계 유연성이 매우 높습니다.
확장성: 네트워크의 크기와 복잡성에 관계없이 쉽게 확장할 수 있어, 대규모 SoC 설계에 적합합니다.
병목 현상 최소화: 패킷이 여러 경로로 라우팅될 수 있어 특정 경로의 병목 현상을 줄일 수 있습니다.
재사용 가능성: 모듈화된 설계 덕분에 기존 NoC 인프라를 재사용하여 새로운 설계에 적용할 수 있습니다.
단점:
복잡한 라우팅 및 제어: 동적 라우팅과 패킷 스위칭으로 인해 라우터의 설계와 제어가 복잡해질 수 있으며, 이로 인해 전력 소모와 설계 시간이 증가할 수 있습니다.
지연 시간 변동: 패킷이 서로 다른 경로로 라우팅될 수 있어, 지연 시간이 일정하지 않을 수 있습니다. 이는 실시간 애플리케이션에 문제가 될 수 있습니다.
전력 소모: 여러 라우터와 스위치가 필요해 전력 소모가 증가할 수 있습니다.
Circuit-Switched Interconnect
특징:
회로 기반 데이터 전송: Circuit-switched interconnect는 두 노드 간에 전용 경로(회로)를 설정한 후, 데이터를 전송합니다. 이 경로는 데이터 전송이 끝날 때까지 유지됩니다.
고정된 경로: 데이터 전송 동안 경로가 고정되어 있으므로, 데이터가 전송되는 동안 경로 변경이 일어나지 않습니다.
간단한 제어: 경로가 고정되므로, 라우팅 제어가 비교적 간단합니다.
장점:
일정한 지연 시간: 전송 경로가 고정되어 있어, 지연 시간이 일정합니다. 이는 실시간 애플리케이션에서 매우 중요한 이점입니다.
낮은 전력 소모: 라우터와 스위치의 복잡성이 낮아 전력 소모가 비교적 적습니다. 특히, 데이터 전송 경로가 최적화된 경우 전력 효율성이 높습니다.
간단한 구현: 회로 스위칭 방식은 라우팅과 제어가 비교적 간단하므로, 구현이 쉬운 편입니다.
단점:
비효율적인 자원 사용: 회로가 설정되면, 데이터 전송이 끝날 때까지 경로가 다른 트래픽에 의해 사용될 수 없습니다. 이는 네트워크 자원의 비효율적인 사용을 초래할 수 있습니다.
확장성 문제: 네트워크 규모가 커질수록 회로를 설정하고 유지하는 데 필요한 자원이 증가하므로, 대규모 SoC에서는 확장성이 제한될 수 있습니다.
유연성 부족: 경로가 고정되어 있어 네트워크 혼잡이 발생할 경우 대체 경로를 사용할 수 없으므로, 병목 현상이 발생할 수 있습니다.
요약
NoC는 유연성과 확장성 측면에서 뛰어나지만, 복잡한 제어와 전력 소모, 지연 시간 변동이 단점으로 작용할 수 있습니다.
Circuit-switched interconnect는 일정한 지연 시간과 낮은 전력 소모를 제공하지만, 자원 사용의 비효율성과 확장성 문제, 유연성 부족이 단점으로 작용할 수 있습니다.
두 방식은 각기 다른 요구사항과 상황에 맞게 선택될 수 있으며, SoC 설계의 목표와 환경에 따라 적합한 방식을 선택하는 것이 중요합니다.
Q) 위에 내용에 의하면 interconnect 모델이 cycle-accurate 하면, sub-system들이 모두 cycle-accurate 하다고 했잖아. 그러면 SoC 안에는 전부 cycle-accurate 수준으로 모델링을 해야 하네.
cycle-accurate 수준의 모델링을 한다는 것은 시스템 내의 모든 구성 요소(sub-system)들이 클럭 사이클 단위로 정확하게 동작하는 것을 의미합니다. SoC(System on Chip) 안에서 전체 interconnect를 cycle-accurate 모델링 하려면, 해당 interconnect와 상호작용하는 모든 sub-system들이 역시 cycle-accurate 수준으로 모델링되어야 합니다.
이유 및 주요 고려 사항
정확한 타이밍 분석:
Cycle-accurate 모델링은 각 클럭 사이클마다 발생하는 모든 이벤트를 정확하게 시뮬레이션합니다. SoC 내에서 interconnect와 연결된 sub-system들이 서로 데이터를 주고받을 때, 이 모든 상호작용이 클럭 사이클 단위로 정확히 일치해야 하므로 모든 sub-system이 cycle-accurate로 모델링되어야 합니다.
성능 및 지연 시간 분석:
SoC 전체의 성능 및 지연 시간을 정확하게 분석하기 위해서는, 모든 sub-system이 동일한 수준의 타이밍 정확도를 가져야 합니다. cycle-accurate 모델링은 클럭 사이클마다 변화를 포착하므로, 시스템 전체의 성능을 정확하게 평가하려면 모든 sub-system이 cycle-accurate 모델로 구성되어 있어야 합니다.
상호작용의 세부 사항 포착:
각 sub-system 간의 상호작용, 특히 데이터 전송이나 중재(arbitration) 같은 중요한 이벤트들은 cycle-accurate 모델링에서만 정확히 반영될 수 있습니다. 이는 특히 복잡한 SoC에서 중요한데, 작은 타이밍 오차가 전체 시스템의 동작에 큰 영향을 미칠 수 있기 때문입니다.
단점 및 현실적인 고려 사항
그러나, SoC 전체를 cycle-accurate 수준으로 모델링하는 것은 매우 복잡하고 시간이 많이 소요되며, 많은 컴퓨팅 자원이 필요합니다. 이런 이유로 설계 초기 단계에서는 고수준 모델링(high-level modelling)이나 TLM(Transaction Level Modelling) 같은 추상화된 방법을 사용하고, 중요한 부분에 대해서만 cycle-accurate 모델링을 적용하기도 합니다.
요약
Cycle-accurate interconnect 모델링을 하려면, 해당 interconnect와 연결된 모든 sub-system들이 cycle-accurate 수준으로 모델링되어야 합니다.
이는 시스템의 성능과 지연 시간을 정확하게 평가하기 위한 필수 조건입니다.
하지만, SoC 전체를 cycle-accurate로 모델링하는 것은 복잡성과 자원 소모가 크기 때문에, 현실적으로 중요한 부분에만 적용하고, 나머지 부분은 고수준 모델링을 사용할 수 있습니다.
따라서, 전체 SoC에서 cycle-accurate 모델링이 필요한지 여부는 설계 목표와 분석의 필요성에 따라 결정됩니다.
SoC는 하드웨어와 소프트웨어를 결합하여 다양한 인터페이스를 통해 외부와 통신합니다. SoC의 설계 과정에서는 설계 입력부터 제조에 이르기까지 모든 단계를 지원하는 모델링 시스템이 이상적입니다. 그러나 SoC 전체를 세부적으로 모델링하고 운영 체제 부팅을 합리적인 시간 내에 시뮬레이션하는 것은 불가능합니다. 예를 들어, 실제 하드웨어보다 백만 배 느린 모델은 10초간의 부팅 시퀀스를 시뮬레이션하는 데 115일이 걸릴 것입니다! 따라서 ESL 가상 플랫폼은 여러 수준의 추상화된 모델링을 지원하고, 이들 사이의 상호작용을 가능하게 해야 합니다.
대부분의 ESL 모델은 이벤트 기반 시뮬레이션(EDS: Event-Driven Simulation)을 바탕으로 만들어집니다. EDS 시뮬레이터는 다양한 유형의 이산 이벤트를 정의하고, 시뮬레이션은 시간 영역에서 이벤트의 진행을 따라갑니다. 모델링의 주요 차이점은 주로 사용되는 이벤트의 유형입니다. 예를 들어, 개별 디지털 네트의 상태 변화부터 전체 Ethernet 패킷의 전달까지 다양합니다. 즉 사용하고자 하는 Application에 따라 Abstraction 의 수준이 결정이 됩니다. 보고자 하는 부분은 Low Level 이 될 것입니다.
모델링 수준의 전체적인 분류는 다음과 같습니다:
Functional modelling: 시뮬레이션의 출력이 정확합니다. 기능적 모델링(Functional Modelling)에서는 내부 구조가 실제 SoC와 같을 필요는 없고, 중요한 것은 최종 출력이 동일하게 나오는 것입니다. 즉, 이 모델은 SoC가 해야 할 동작을 제대로 수행하고 있는지 확인하기 위한 것으로, 내부의 구현 방식보다는 외부로 나타나는 결과가 정확한지를 중점으로 합니다. 이렇게 하면 SoC의 기본 동작을 확인하고 설계 초기 단계에서 큰 틀을 잡는 데 유용합니다.
Memory-accurate modelling: 메모리의 내용과 레이아웃이 정확합니다.
Cycle lumped or untimed TLM: IP 블록 간의 데이터 전달과 같은 완전한 트랜잭션이 원자적(atomic) 이벤트로 모델링됩니다. 트랜잭션에 타임스탬프가 기록되지 않습니다. 프로그램 실행 후 사이클 수는 정확하지만, 개별 사이클은 모델링되지 않습니다. 일반적으로 서브 모델이 일정 작업을 수행한 후 사이클 수를 업데이트합니다.
Stochastic or loosely timed TLM: 트랜잭션 수는 정확하지만 순서가 틀릴 수 있으며, 표준 큐잉 모델을 기반으로 각 트랜잭션에 타임스탬프가 부여됩니다. 따라서 전체 실행 시간이 보고될 수 있습니다.
Approximately timed TLM: 트랜잭션 수와 순서가 정확하며, 그들이 겹치거나 방해되는 정도를 측정합니다.
Cycle-accurate simulation: 사용된 클럭 사이클 수가 정확하고, 각 클럭 사이클에서 수행된 작업이 정확하게 모델링됩니다. 합성 가능한 RTL 시뮬레이션이 이러한 모델을 제공합니다.
Net-level EDS: 서브시스템의 네트리스트가 완전히 모델링되며, 클럭 사이클 내에서 네트 변화의 순서가 정확합니다.
Analogue and mixed-signal simulation: 특정 노드의 전압 파형이 모델링됩니다.
이러한 모델링 수준을 더 자세히 설명하기 전에, 추가로 정의할 가치가 있는 두 가지 용어가 있습니다:
1. Programmer-view accuracy: 이 모델은 프로그래머가 볼 수 있는 메모리와 레지스터의 내용을 정확하게 반영합니다. 프로그래머의 관점(PV)은 소프트웨어 프로그래머가 명령어로 조작할 수 있는 구조적으로 중요한 레지스터만 포함합니다. 특정 하드웨어 구현의 다른 레지스터, 예를 들어 파이프라인 단계와 구조적 위험을 극복하기 위한 홀딩 레지스터 등은 PV 모델에 포함되지 않습니다. PV 모델이 시간 개념을 포함하면, 이를 PV+T라고 합니다. 비슷하게, PV+ET는 에너지와 시간 사용을 모델링하는 것을 의미합니다. 2. Behavioral modelling: 이 용어는 정확한 정의가 없지만, 일반적으로 실제 구현과는 다른 시뮬레이션 모델을 나타냅니다. 예를 들어, 특정 구성 요소나 서브시스템의 행동을 모델링하기 위해 핸드크래프트된 프로그램이 작성될 수 있습니다. 보다 구체적으로는, 소프트웨어 프로그래밍과 같이 명령형 스레드를 사용하여 구성 요소의 동작을 표현하는 모델을 의미할 수 있습니다.
일부 애플리케이션 클래스에서는 SoC의 시작점이 SoC가 생성해야 할 출력과 동일한 출력을 생성하는 소프트웨어 프로그램일 수 있습니다. 이것이 Functional model입니다. 예를 들어 IoT 장치의 경우, 이 모델은 네트워크를 통해 동일한 응답을 제공해야 합니다. RF 송신기 서브시스템의 경우, 실제 안테나에 전달할 아날로그 파형을 모델링 워크스테이션의 파일에 기록할 수 있습니다. 이러한 모델은 SoC 구현의 구조를 전혀 나타내지 않지만, 필요한 기본 동작을 정의하고 SoC 기반 솔루션과 생태계의 나머지 부분을 평가하는 데 사용할 수 있는 참조 데이터를 제공합니다.
SoC는 일반적으로 대량의 메모리를 포함합니다. 다음 단계는 SoC 내에 몇 개의 논리 메모리 공간이 있어야 하는지를 결정하고, 그들의 상세한 레이아웃을 계획하는 것입니다. 기능적 모델의 소프트웨어는 하드웨어를 나타내는 부분과 SoC 내에서 실행되는 소프트웨어로 분할해야 합니다. 이 모델에는 최종적으로 실제 하드웨어의 하나 이상의 SRAM 및 DRAM 구성 요소에 저장될 여러 배열이 포함됩니다. Memory-accurate model에서는 모델 내 각 배열의 내용이 최종 구현에서 실제 메모리의 내용과 동일합니다. 이 모델의 배열에서의 작업 빈도 또는 내부 루프 반복 횟수를 수동으로 계산하면, SoC에 필요한 처리 능력과 메모리 대역폭을 예비 추정할 수 있습니다. 이러한 수치를 간단히 스프레드시트로 분석하여 최종 전력 소비와 배터리 수명을 첫 번째로 추정할 수 있습니다.
ESL 모델링에서 다음 단계는 트랜잭션 레벨 모델(TLM)을 생성하는 것입니다. TLM 모델에서는 수많은 실제 네트나 인터커넥트 구성 요소를 전혀 나타낼 필요가 없습니다. 이로 인해 TLM 모델이 네트 레벨 시뮬레이션보다 훨씬 빠르게 실행됩니다. TLM 모델은 옵션으로 시간, 전력 및 에너지를 포함할 수 있습니다.
사이클 정확 모델은 서브시스템의 레지스터와 RAM의 모든 상태 비트를 모델링합니다. 상태 비트는 클럭 사이클마다 업데이트되어 해당 클럭 엣지에서의 새 값을 반영합니다. 성능을 향상시키기 위해, 사이클 정확 모델은 일반적으로 Verilog나 VHDL의 더 풍부한 논리 대신 간단한 2값 논리 시스템 또는 4값 논리 시스템을 사용합니다. 사이클 호출 가능한 모델은 하나의 클럭 도메인의 사이클 정확 모델입니다. 이는 기본적으로 상위 시뮬레이터의 스레드에 의해 호출될 수 있는 서브루틴으로 구성되어 있으며, 모델이 한 클럭 사이클씩 진행하도록 합니다. 예를 들어, 카운터의 사이클 호출 가능한 모델은 카운터 값을 증가시키는 서브루틴일 것입니다. 저수준 모델은 실제 구현의 모든 플립플롭과 버스를 나타내며, 이러한 모델들은 구성 요소의 RTL 구현을 기반으로 합니다.
논의된 것처럼, 네트에서 전압 파형을 시뮬레이션하는 저수준 시뮬레이션도 가능합니다. 이는 아날로그 및 혼합 신호 시스템에 필요하지만, 디지털 논리에는 일반적으로 필요하지 않습니다.
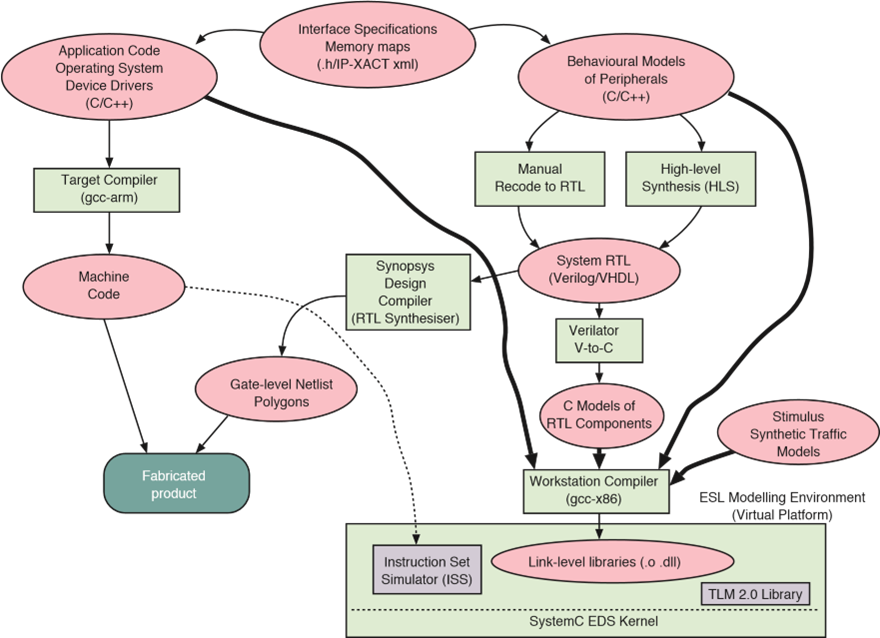
ESL Flow Diagram
ESL흐름은 주로 C++ 기반으로 이루어지며, SystemC TLM 라이브러리도 일반적으로 사용됩니다. SoC 설계에서 C/C++은 주로 Peripherals의 행동 모델링(Behavioural Models), 임베디드 애플리케이션, 운영 체제, 그리고 디바이스 드라이버를 위해 사용됩니다. 하드웨어와 소프트웨어 간의 API에 대한 인터페이스 사양은 .h 파일에 있으며, 이 파일들은 하드웨어와 소프트웨어 모두에서 사용됩니다. 이 C++ 파일들은 이미지의 상단에 표시되어 있습니다.
SoC 수준의 제품에 대한 임베디드 머신 코드를 생성하기 위해, 소프트웨어 측은 해당 임베디드 코어에 적합한 컴파일러(gcc-arm 등)를 사용하여 컴파일됩니다. 하드웨어 측에서는 하드웨어의 행동 모델이 다양한 방법으로 RTL(Register Transfer Level) 및 게이트 레벨(Gate-level)로 변환됩니다. 이 과정은 그림에서 오른쪽에서 왼쪽으로 대각선 방향으로 나타나 있습니다.
반면, 가장 빠른 ESL 모델은 일반적으로 왼쪽에서 오른쪽으로 내려가는 경로를 통해 생성됩니다. 이 경로에서는 하드웨어 모델과 임베디드 소프트웨어를 함께 연결하여 전체 시스템을 단일 애플리케이션 프로그램으로 실행할 수 있게 합니다. 이는 적절한 코딩 가이드라인이 따라져야만 가능합니다. 이 하이브리드 모델은 실제 시간보다 빠르게 실행될 수 있으며, 경우에 따라서는 고성능 모델링 워크스테이션이 임베디드 SoC 코어보다 더 강력한 프로세서를 가지고 있을 때, 더 빠르게 실행될 수도 있습니다.
성능 향상의 예
네트워크 패킷을 디바이스 드라이버가 수신하고 이를 버스를 통해 메모리로 전송하는 상황을 생각해 봅시다. 실제 구현에서는 수만 번의 게이트 출력 전환이 일어나게 됩니다. 네트 레벨(Net-level) 시뮬레이션을 사용하면, 각 게이트 전환의 시뮬레이션은 모델링 워크스테이션에서 100번의 명령어를 실행할 수 있습니다. 하지만 적절한 ESL 코딩 스타일을 사용하면, 패킷 수신 트랜잭션은 한 컴포넌트에서 다른 컴포넌트로 간단한 메소드 호출로 모델링될 수 있으며, 총 100개 이하의 명령어만을 필요로 합니다. 메모리 관리를 신중하게 하면, 트랜잭션으로 전송되는 데이터는 복사될 필요가 없으며, 버퍼에 대한 포인터만 전송하면 됩니다.
주요 포인트
Instruction Set Simulator (ISS): ISS는 임베디드 코어의 머신 코드를 해석하기 위해 사용될 수 있습니다. 최상의 ISS 구현은 자주 사용되는 실행 경로를 식별하고, 이 코드들을 모델링 워크스테이션의 네이티브 머신 코드로 크로스 컴파일하여 실제 시간보다 빠른 성능을 달성할 수 있습니다.
RTL과 C++ 모델 간 변환: RTL 모델이 초기 고수준 모델과 크게 다르거나 고수준 모델이 존재하지 않는 경우, RTL 디자인은 표준 도구를 사용해 C++ 모델로 변환될 수 있습니다. Verilator와 같은 도구가 이러한 변환을 수행하는 데 자주 사용됩니다. 예를 들어, Arm은 Carbon 도구 체인을 사용해 내부 RTL에서 생성된 C++ 모델을 제공합니다.
이 흐름은 SoC 설계에서 매우 중요한데, 이 과정을 통해 빠르고 효율적인 모델링 및 시뮬레이션이 가능해집니다.
SystemC EDS Kernel
SystemC EDS Kernel은 SystemC 라이브러리의 핵심 구성 요소 중 하나로, **Event-Driven Simulation**(EDS) 커널이라고도 불립니다. 이는 SystemC에서 시뮬레이션을 관리하고 실행하는 중심 역할을 담당합니다. SystemC는 C++ 기반의 하드웨어 설계 언어로, 하드웨어의 동작을 소프트웨어 방식으로 시뮬레이션할 수 있게 해줍니다.
SystemC EDS Kernel의 역할
1. 이벤트 기반 시뮬레이션 관리 - EDS Kernel은 하드웨어 시뮬레이션에서 발생하는 이벤트를 관리합니다. 하드웨어 시뮬레이션은 주로 이벤트(예: 신호의 변화, 타이머 이벤트 등)가 발생할 때마다 상태를 업데이트하고 다음 이벤트를 처리하는 방식으로 진행됩니다. - SystemC에서는 각 컴포넌트(예: 모듈, 프로세스)가 이벤트를 생성하거나 해당 이벤트에 반응하여 동작을 수행합니다. EDS Kernel은 이러한 이벤트들을 시간 순서에 따라 정렬하고 처리합니다.
2. 동기화 및 스케줄링 - SystemC EDS Kernel은 시뮬레이션 시간에 따라 프로세스와 이벤트를 동기화합니다. 이는 실제 하드웨어가 클럭에 따라 동작하는 것과 유사하게 시뮬레이션이 정확한 타이밍에 따라 진행되도록 합니다. - 커널은 각 프로세스가 언제 실행되어야 하는지, 어떤 순서로 이벤트가 발생해야 하는지를 결정합니다. 이를 통해 하드웨어 설계의 정확성과 타이밍을 검증할 수 있습니다.
3. 컨텍스트 스위칭 최소화 - 고성능 시뮬레이션을 위해 EDS Kernel은 컨텍스트 스위칭을 최소화하도록 설계되었습니다. 이는 프로세스 간의 전환을 줄이고, 가능한 한 빠르게 시뮬레이션을 실행하는 데 도움을 줍니다. - 예를 들어, 하드웨어 설계 시나리오에서 여러 프로세스가 동시에 실행될 때, EDS Kernel은 이러한 프로세스들이 최대한 효율적으로 실행되도록 스케줄링합니다.
4. 하이브리드 시뮬레이션 지원 - SystemC EDS Kernel은 소프트웨어와 하드웨어 간의 하이브리드 시뮬레이션을 지원합니다. 이는 전체 시스템을 단일 프로그램으로 실행하는 방식으로, 실제 하드웨어보다 빠르게 시뮬레이션이 가능하도록 설계되었습니다. - 이를 통해 복잡한 SoC의 성능을 빠르고 효율적으로 검증할 수 있습니다.
SystemC EDS Kernel은 하드웨어 시뮬레이션에서 이벤트 기반 방식으로 동작을 관리하고, 시뮬레이션 시간에 따라 프로세스와 이벤트를 동기화하며, 시뮬레이션의 효율성을 높이기 위해 컨텍스트 스위칭을 최소화하는 역할을 합니다. 이 커널은 복잡한 SoC 설계를 시뮬레이션하고 검증하는 데 필수적인 요소로, SystemC를 사용한 하드웨어 및 시스템 모델링의 핵심이라고 할 수 있습니다.
SystemC의 역할
SystemC가 ESL설계에서 매우 중요한 도구이긴 하지만, ESL 설계가 SystemC에만 의존하는 것은 아닙니다. SystemC는 ESL 설계를 위한 강력하고 널리 사용되는 도구이지만, ESL(전자 시스템 레벨) 설계를 수행하는 다양한 방법과 도구가 존재합니다.
SystemC는 특히 C++ 기반의 하드웨어 설계와 시뮬레이션에 탁월하며, Transaction Level Modeling(TLM)과 같은 높은 추상화 수준의 모델링을 지원합니다. 이러한 이유로, SoC(System on Chip) 설계에서 널리 사용되며, ESL 설계 흐름에서 매우 중요한 역할을 합니다.
ESL 설계의 다양한 접근법
그러나 SystemC 없이도 ESL 설계가 가능합니다. 다음은 몇 가지 예시입니다:
기타 언어 및 라이브러리:
ESL 설계를 위해 다른 하드웨어 설계 언어 또는 라이브러리도 사용될 수 있습니다. 예를 들어, MATLAB/Simulink는 하드웨어와 시스템 수준의 모델링 및 시뮬레이션에 자주 사용됩니다.
Python 기반의 MyHDL, VHDL, Verilog와 같은 언어도 고수준의 모델링과 시뮬레이션에 사용될 수 있습니다.
전용 ESL 툴:
Cadence, Synopsys, Mentor Graphics 등에서 제공하는 상용 ESL 도구들은 SystemC를 사용하지 않고도 ESL 설계를 가능하게 합니다. 이들 도구는 각각의 ESL 설계 흐름을 지원하며, 다양한 추상화 수준에서의 하드웨어와 소프트웨어 통합 설계를 수행할 수 있습니다.
비-시뮬레이션 기반 검증:
ESL 설계는 반드시 시뮬레이션 기반일 필요가 없습니다. 수학적 검증, 형식 검증(formal verification), 모델 검증(model checking) 등의 방법도 ESL 설계에서 사용할 수 있습니다. 이러한 방법들은 SystemC와 무관하게 사용할 수 있으며, SoC 설계의 정확성을 보장하는 데 중요한 역할을 합니다.
SystemC는 ESL 설계에서 매우 유용하고 강력한 도구이지만, 필수불가결한 요소는 아닙니다. 다양한 도구와 방법을 사용해 ESL 설계를 수행할 수 있으며, 각 도구와 방법은 특정 요구사항에 따라 선택될 수 있습니다. SystemC가 없더라도 ESL 설계는 가능하며, 그 성공 여부는 설계자의 요구사항에 맞는 도구와 방법을 얼마나 잘 선택하고 사용하는지에 달려 있습니다.