Basic Concepts on On-Chip Networks

SoC(System-on-Chip)에 통합되는 core 수가 증가함에 따라, 통신 시스템의 역할이 점점 더 중요해지고 있다. Network-on-Chip(NoC) 설계 패러다임은 초미세 공정 시대의 확장성 문제를 해결할 수 있는 가장 현실적인 통신 인프라로 인식되고 있다. 본 장에서는 on-chip network와 관련된 가장 중요한 개념들을 다룬다. 네트워크 토폴로지, switching technique, routing algorithm과 같은 기본 개념을 다룬다. 이 주제들은 이후 장들에서 설명할 전략, 메커니즘, 방법론의 개념적 기초가 된다.
1.1 Introduction
초기의 프로그래머블 칩(예: microprocessor)은 단일 계산 코어(single computational core)로 설계되었다. 이런 칩은 프로그램 명령어를 순차적으로 실행하며, 클럭 주파수에 비례하는 속도로 작동했다. 따라서 칩 성능을 향상시키는 가장 일반적인 방법은 클럭 주파수를 높이는 것이었다.
하지만 클럭 주파수를 높이는 데에는 몇 가지 단점이 따른다. 가장 큰 문제는 전력 소비가 증가하면서 칩의 작동 온도가 올라간다는 점이다. 고클럭 주파수는 소수 제곱 센티미터의 작은 면적에서 높은 열을 발생시키고, 이는 열 발산 문제를 야기한다. 또한, 작동 온도가 10 °C 올라갈 때마다 구성 요소의 고장률이 두 배 가까이 증가하여 시스템 신뢰성에도 영향을 미친다.
현재와 차세대 애플리케이션의 연산 요구는 단순히 클럭 주파수 증가만으로는 충족할 수 없다. 이 한계를 극복하기 위해, 현대 칩은 낮은 클럭 주파수로 병렬로 동작 가능한 여러 개의 계산 코어(multiple parallel computational cores)를 통합하여 설계된다. 각 코어는 단일 코어보다 느리게 작동하지만, 병렬 실행을 통해 전체 성능을 향상시킬 수 있다.
칩에 통합되는 core 수가 증가할수록(Fig. 1.1 참조), on-chip communication의 중요성은 computation 자체보다 더 부각된다. 즉, 계산 능력은 core 수를 늘리면 되지만, 이들 간 상호작용을 조율하기 위한 효율적인 통신 인프라가 필요하다.

NoC는 차세대 many-core SoC의 통신 문제를 해결하기 위한 가장 유망한 솔루션으로 간주된다. NoC는 컴퓨터가 core로 대체된 네트워크라 볼 수 있으며, 정보는 on-chip 링크를 통해 패킷 형태로 전송되고, on-chip router에 의해 라우팅된다.
NoC는 MPSoC를 위한 확장 가능하고 신뢰성 있으며 모듈화된 interconnect fabric으로 자리잡고 있다. 하지만 network fabric은 시스템 전력 예산의 상당 부분을 차지한다. 전력은 billion-transistor 칩에서 매우 중요한 이슈이므로, network delay, 면적 외에도 전력 소모도 반드시 고려해야 한다. 따라서 NoC는 효율적인 topology, routing algorithm, router 구현을 통해 제한된 실리콘 면적에 적합하게 설계되어야 한다.
이 장에서는 NoC의 기본 개념인 network topology, switching technique, flow control mechanism, virtual channel, output selection, routing algorithm, 일반적인 NoC 아키텍처를 설명한다.
1.2 Network Topology
Network topology는 router의 배치 및 연결 구조를 다룬다. 즉, 네트워크를 통해 데이터를 전송하기 위해 사용 가능한 채널 및 연결 패턴을 정의한다. 성능, 비용, 확장성은 적절한 topology를 선택하는 데 중요한 요소이다. Shared-Bus, Crossbar, Butterfly Fat-Tree, Ring, Torus, 2D-Mesh는 상업적으로 사용된 대표적인 on-chip interconnect 토폴로지들이다.

Direct network는 네트워크의 각 router에 최소한 하나의 processing element(PE)가 연결된 구조로, router들이 PE 사이에 고르게 분포될 수 있게 해준다. 이는 물리적 구현을 단순화하는 데 도움을 준다. Shared-bus, Ring, 2D mesh/torus topology(Fig. 1.2 참조)는 대표적인 direct network이며, 성능 향상을 가져오지만 PE 수가 늘어날수록 하드웨어 오버헤드가 제곱 비율로 증가한다.
반면, indirect network는 PE에 연결되지 않은 router가 일부 포함된다. 예를 들어 butterfly topology나 crossbar switch는 indirect network이다.
Shared-bus topology는 모든 PE가 공유하는 단일 버스를 통해 통신하는 가장 단순한 방식이다. 하지만 통신량이 많은 애플리케이션에는 shared-bus의 대역폭 제약이 큰 문제가 되며 확장성이 낮다. 이에 대한 보완으로 모든 PE가 양 옆 이웃 두 개를 가지는 ring topology가 제안되었다. 이 구조에서는 메시지가 중간 PE들을 거쳐 최종 목적지까지 전달되며, 대부분의 트래픽 패턴에서 낮은 injection rate에서도 네트워크 포화가 발생한다. Crossbar topology는 모든 PE 간 직접 연결이 가능한 완전 연결 구조이다.
Fat-tree topology는 PE 수가 증가하면 router 수도 함께 증가하여 큰 네트워크 오버헤드를 유발한다. On-chip interconnect에서는 off-chip보다 network overhead가 더 중요한 문제가 되므로, 설계 확장성이 필수적이다. Mesh와 Torus network는 인접 연결이 가능하고 라우팅이 쉬워서 multiprocessor 아키텍처에서 널리 사용된다. 두 토폴로지 모두 완전 확장 가능하다. Torus는 더 나은 성능을 제공하지만, Mesh는 링크 활용도 및 네트워크 오버헤드 측면에서 더 효율적이다. 예컨대, Mesh는 가장자리에 위치한 router가 작기 때문에 경제적이다. 요약하자면, 각 topology는 고유한 장점과 단점을 가진다.
1.3 Switching Mechanism
Switching mechanism은 메시지가 네트워크 내 경로를 따라 어떻게 이동하는지를 결정한다. 목적은 네트워크를 통과하는 메시지들 사이에서 자원을 효과적으로 공유하는 것이다. 기본적으로, circuit switching과 packet switching이 두 가지 대표적인 방식이다.
Circuit switching에서는 source에서 destination까지의 연결을 데이터 전송 이전에 설정하며, 메시지가 완전히 전송될 때까지 해당 경로를 독점적으로 유지한다(예: 전화망에서는 통화마다 여러 router를 경유해 회선을 설정한다). 이 방식은 낮은 지연과 대역폭 보장을 제공하지만, channel utilization이 낮고 throughput도 낮으며, 연결 설정에 오랜 초기 시간이 걸리는 단점이 있다.
Packet switching은 사전에 경로를 설정하지 않는다. 메시지는 여러 개의 packet으로 나뉘며, 각 packet은 다른 packet들과 channel을 공유하면서 네트워크를 통과한다. 각 packet은 routing과 control 정보를 담고 있는 header, 데이터 payload, 그리고 tail로 구성된다. Header는 channel을 점유하며 payload는 그 뒤를 따르고, tail은 channel 점유를 해제한다. 각 packet은 독립적으로 라우팅되며, 최종적으로 목적지에서 원래 메시지로 조립된다.
메시지가 여러 packet으로 나뉠 경우, 수신지에서의 packet 순서는 전송 당시와 같아야 한다. 따라서 in-order delivery는 on-chip network에서 반드시 보장되어야 할 요소이다. Packet switching은 channel utilization과 network throughput을 향상시킨다.
Buffered Flow Control
Packet switching에서는 buffered flow control이 source와 destination 간의 channel과 buffer 할당을 조절하는 메커니즘을 정의한다. 두 개 이상의 packet이 동시에 동일한 channel을 사용하려 할 때 flow control이 필요하다. 일반적으로 세 가지 전략이 있다:
- Store-and-Forward
- Virtual Cut-Through
- Wormhole
각 방법은 성능 특성이 다르며 하드웨어 자원 요구사항도 서로 다르다.
1.3.1 Store-and-Forward
Store-and-Forward는 가장 단순한 flow control 메커니즘이다. 경로상의 각 router는 packet 전체를 buffer에 저장한 다음, 다음 router의 buffer에 충분한 공간이 있을 경우에만 packet을 전송한다. 각 router마다 최대 packet 크기만큼의 buffer 공간이 필요하므로 비용이 많이 든다. 또한, packet이 완전히 수신되어야 다음 router로 전송할 수 있기 때문에 network latency가 매우 크다. 따라서 이 방식은 large-scale NoC에서는 실용적이지 않다.
1.3.2 Virtual Cut-Through
Virtual Cut-Through는 store-and-forward의 latency 문제를 해결하기 위해 제안되었다. 이 방식에서는 packet이 현재 router에 완전히 수신되기 전에 다음 router로 전송될 수 있다. 그러나 다음 router가 사용할 수 없는 경우에는 store-and-forward와 동일하게 전체 packet을 저장해야 하므로 여전히 large buffer space가 필요하다.
1.3.3 Wormhole
Wormhole 방식에서는 packet이 작은 단위인 **FLITs (FLow control digIT)**로 나뉜다. Flit은 pipeline 방식으로 순차적으로 네트워크를 통과한다. 첫 번째 flit인 header는 router의 channel을 점유하고, body flit이 그 경로를 따라가며, tail flit은 channel 점유를 해제한다. 이 방식은 header flit이 다음 router로 경로를 설정할 때까지 전체 packet을 저장할 필요가 없다. 하나의 packet이 여러 intermediate router를 동시에 점유할 수 있다.
Wormhole은 virtual cut-through와 유사하지만, channel과 buffer의 할당 단위가 packet 단위가 아닌 flit 단위라는 점이 다르다. 따라서 훨씬 적은 buffer 공간으로도 동작할 수 있으며, 작고 빠른 router 설계가 가능하다. 이러한 장점으로 인해 wormhole은 on-chip network에 이상적인 flow control 방식으로 여겨진다.
1.4 Virtual Channels
Wormhole network에서는 하나의 packet이 경로상의 channel을 점유하면 다른 packet이 해당 channel을 사용할 수 없어 blocking이 발생할 수 있다. 이 문제를 해결하기 위해 **Virtual Channels (VCs)**이 도입되었다. VC는 여러 개의 flit queue를 갖는 논리적인 채널로, 동일한 물리적인 channel에 대해 여러 VC를 할당하여 blocking을 피할 수 있게 한다.
각 VC는 header flit이 도착하면 buffer가 할당되며, tail flit이 전송될 때까지 해당 VC를 점유한다. 특정 VC를 점유한 packet이 blocking 상태일지라도, 다른 VC에 속한 packet은 물리 채널을 사용할 수 있다.
Fig. 1.3에서 보듯, input port에 도착한 flit들은 서로 다른 VC buffer에 저장되며, 이들은 다시 multiplexer를 통해 output port로 전송된다. 하나의 채널이 block되어도 다른 채널은 output port에 접근할 수 있다. VC는 deadlock avoidance와 network latency 개선, throughput 향상을 위해 도입되었다.

Fig. 1.4a는 VC가 없는 경우 packet A가 router 3과 4 사이에서 block될 때 packet B도 함께 block되는 예를 보여준다. 반면 Fig. 1.4b는 VC를 사용할 경우, packet A가 block되어도 packet B는 router 3을 통과할 수 있음을 보여준다.
VC를 사용하면 성능과 Head-of-Line blocking (HoL) 문제가 개선되지만, link controller와 flow control mechanism의 설계 복잡도는 증가한다.

1.5 Network Dimension
NoC 설계는 주로 2D architecture와 3D architecture로 나뉜다.
- 2D NoC(Fig. 1.5a): 모든 switch가 하나의 layer에 배치되고, 같은 layer 내에서 연결된다.
- 3D NoC(Fig. 1.5b): layer들이 수직으로 stacking되며, 층 간 연결(inter-layer connection)이 존재한다.
각 layer는 서로 다른 기술, topology, 클럭 주파수를 사용할 수 있다. 최근에는 TSV (Through-Silicon Via) 기술이 층 간 연결을 위한 방식으로 각광받고 있으며, 빠르고 전력 효율적인 수직 통신을 가능하게 한다. Fig. 1.5는 core 수가 유사한 2D 및 3D network를 보여준다.

1.6 Output Scheduling
여러 packet이 하나의 output port를 요청하는 경우, 이들 중 어떤 packet이 먼저 전송될지 결정하는 output scheduling algorithm이 필요하다. 스케줄러는 각 packet에 우선순위를 할당한 후, 가장 높은 우선순위를 가진 packet이 선택된다.
일반적으로 다음과 같은 방식이 있다:
- Round-robin: 모든 packet을 순환 방식으로 공평하게 처리하여 starvation을 방지한다.
- First-come, first-served
- Priority-based scheduling: 특정 packet에 더 높은 우선순위를 부여하여 quality of service를 개선할 수 있다. 그러나 이 방식은 낮은 우선순위 packet의 starvation 문제를 초래할 수 있다.
따라서, starvation을 방지하기 위해 적절한 리소스 할당이 필요하다.
1.7 Routing Algorithm
Routing은 source와 destination 사이에서 packet이 적절한 방향으로 전달되도록 경로를 설정하는 과정이다.
일반적으로 routing algorithm은 두 개의 주요 블록으로 구성된다(Fig. 1.6 참조):

- Routing function: packet이 destination에 도달하기 위해 전송될 수 있는 admissible output channels의 집합을 계산한다.
- Selection function: routing function이 반환한 output channel 집합 중 하나를 선택한다.
- Deterministic routing algorithm을 사용하는 router에서는 routing function이 오직 하나의 output port만 반환하므로 selection block이 필요 없다(Fig. 1.6a).
- Oblivious routing에서는 selection block이 header flit 정보만을 기반으로 결정을 내린다(Fig. 1.6b).
- Adaptive routing을 구현한 router의 selection function은 link utilization, buffer occupation 등의 network status information을 사용한다(Fig. 1.6c).
Routing algorithm은 단지 전송 시간뿐만 아니라 전력 소모 및 혼잡도에도 영향을 미칠 수 있다.
1.7.1 Source Versus Distributed Routing
Routing은 source router에서 결정할 수도 있고, 경로 상의 각 router에서 분산된 방식으로 수행될 수도 있다.
- Source routing에서는 전체 경로가 source router에 의해 결정되며, router 간 이동 경로가 header에 저장된다. packet이 네트워크를 통과하면서 각 router는 이 정보를 이용해 packet을 forwarding 한다.
- 장점: 구조가 간단하다.
- 단점: header에 routing 정보가 모두 들어가야 하므로 오버헤드가 크다. 네트워크의 diameter가 k라면, header는 최대 k개의 routing 정보를 담아야 하며, network 크기가 커질수록 이 오버헤드는 실용적이지 않다.
- 반면, Distributed routing에서는 각 router가 목적지 주소(가끔은 source 주소도 필요)에 따라 경로를 동적으로 결정한다. 이 방식에서는 packet의 header에 목적지 주소만 포함하면 되며, routing decision은 경로상의 router가 처리한다.
- 장점: header 오버헤드가 작다.
- 단점: router 설계 복잡도가 증가한다.
1.7.2 Deterministic Versus Adaptive Routing
Distributed routing은 다음 세 가지로 분류된다:
- Deterministic routing: source와 destination 사이의 고정된 경로를 사용한다. 구현은 단순하지만 non-uniform하거나 burst traffic에는 load balancing이 되지 않아 비효율적이다.
- Oblivious routing: source에서 destination까지 여러 경로가 가능하며, 선택은 network 상태와 무관하게 이루어진다.
- Adaptive routing: network 상태에 따라 routing 경로가 동적으로 결정된다. 예를 들어, 혼잡하거나 고장난 링크를 피하려고 한다.
- packet들이 서로 다른 경로를 통해 도착하므로 in-order delivery를 보장하지 못한다.
- 순서를 맞추기 위해 reordering module이 필요하며, 이는 설계 복잡도와 통신 지연을 증가시킨다.
- Adaptive routing은 network 성능을 향상시키고, router나 링크에 문제가 생겼을 때 fault tolerance를 제공한다. 하지만 다음과 같은 단점이 있다:
따라서, Deterministic routing은 uniform traffic에는 적합하지만, Adaptive routing은 불규칙하거나 burst한 traffic, 혹은 고장이 발생하는 network에 더 적합하다.
1.7.3 Minimal Versus Non-minimal Routing
Adaptive routing algorithm은 다음 두 가지로 나뉜다:
- Minimal routing: packet이 destination까지 도달하는 가장 짧은 경로만 허용한다.
- Non-minimal routing: 더 긴 경로도 허용하여 우회 경로를 사용할 수 있다.
또한,
- Minimal fully adaptive routing: 모든 가능한 최단 경로 중에서 동적으로 선택할 수 있다.
- Minimal partially adaptive routing: 모든 최단 경로를 선택할 수 있는 것은 아니다.
1.7.4 Unicast and Multicast Routing Protocols
On-chip network에서의 통신은 Unicast (1:1) 또는 Multicast/Broadcast (1:多) 방식이 가능하다.
- Unicast: source router에서 하나의 destination router로 packet을 전송.
- Multicast: source router에서 여러 개의 destination router로 packet을 동시에 전송.
Multicast는 Replication, Barrier Synchronization, Cache Coherency(특히 distributed shared-memory 구조), Clock Synchronization 등 MPSoC 애플리케이션에서 자주 사용된다.
Multicast는 여러 번의 unicast로도 구현 가능하지만, 그럴 경우 불필요한 트래픽이 발생하여 latency와 혼잡을 증가시킨다.
1.7.5 Deadlock and Livelock

그림 1.7은 deadlock 상황의 예를 보여준다. 동일한 시간 t에, 네 개의 packet이 각각 다음 위치에 존재한다고 가정한다:
- Packet 1: Router 3의 west port
- Packet 2: Router 4의 south port
- Packet 3: Router 2의 east port
- Packet 4: Router 1의 north port
각 packet의 목적지는 반시계 방향으로 두 홉 떨어진 지점이다:
- Packet 1 → Node 2
- Packet 2 → Node 1
- Packet 3 → Node 3
- Packet 4 → Node 4
routing function이 최소 홉 수를 기준으로 반시계 방향을 우선시한다고 가정하면, 시간 t+1에 다음과 같은 일이 발생한다:
- Router 3는 west input port를 선택하여 east output port로 연결되는 shortcut을 형성한다.
- wormhole routing 규칙에 따라, Packet 1의 모든 flit이 Router 3를 통과할 때까지 이 shortcut은 유지된다.
- 동일한 방식으로, 다른 router들도 각각 input과 output port 사이에 shortcut을 만든다.
시간 t+2에 이르면:
- Packet 1의 첫 번째 flit은 Router 4의 west input buffer에 저장된다. 하지만 이 flit은 north output port로 나가야 하며, 해당 포트는 이미 Packet 2의 flit이 사용 중이다.
- 이로 인해 Packet 1은 block되고, 나머지 packet들도 서로 간에 경로를 점유하고 있어 모두 정지된다.
각 input buffer가 1개의 flit만 저장할 수 있다고 가정하면, 어떤 packet도 앞으로 나아갈 수 없고, 결과적으로 deadlock 상태에 빠진다.
Deadlock freedom을 검증하는 일반적인 방법은 Duato의 정리(Duato’s Theorem)를 사용하는 것이다. 이 정리는 adaptive routing function을 위한 Dally와 Seitz의 정리를 확장한 것이다. 이 정리는 routing function과 network topology로부터 도출되는 Channel Dependency Graph (CDG)의 분석에 기반한다.
- Topology Graph TG = G(P, L): 정점 pi는 network의 node를 나타내고, 간선 lij = (pi, pj)는 pi에서 pj로의 단방향 물리 링크를 나타낸다.
- 각 node p에 대해:
- Lin(p): p로 들어오는 input 링크들의 집합
- Lout(p): p에서 나가는 output 링크들의 집합
- Routing Function R(p): node p에 대해, 입력 링크 l과 목적지 q를 받아서 가능한 출력 링크들의 집합 ℘(Lout(p))을 반환한다.
- Channel Dependency Graph CDG: TG의 링크들을 정점으로 하고, 링크 간 direct dependency가 존재할 때 간선을 갖는다.
Duato’s Theorem: routing function R이 deadlock-free이기 위한 충분조건은, CDG에 사이클이 존재하지 않는 것이다.
Duato's Theorem을 정리해 보면, CDG에 사이클이 존재하면 Deadlock이 생길 수 있고, Deadlock이 생긴다고 해서 CDG에 사이클이 존재하는 것은 아니다.
Livelock은 packet이 네트워크 안에서 계속 순환하지만 목적지에 도달하지 못하는 상태이다. 이는 일반적으로 non-minimal adaptive routing algorithm을 사용할 때 발생할 수 있다.
Livelock-free routing algorithm은 모든 packet이 전진(progress)하도록 보장해야 하며, 각 hop마다 packet이 목적지에 더 가까워지도록 해야 한다.
1.7.6 Turn Model Routing
Turn Model Routing은 wormhole switching 기반의 라우팅 방식으로, 2D mesh topology에서 deadlock과 livelock을 방지한다. 이 모델은 minimal하고 부분적으로 adaptive한 라우팅 방식의 대표 사례이기도 하다.
핵심 아이디어는 라우팅 사이클을 깨기 위해 일부 turn만 금지함으로써 deadlock을 방지하는 것이다.
대표적인 네 가지 turn model은 다음과 같다 (Fig. 1.8 참조):
- XY
- Negative-First (NF)
- West-First (WF)
- North-Last (NL)
XY는 deadlock을 방지하기 위해 8개의 turn 중 4개를 금지하지만, NF, WF, NL은 단 2개의 turn만 금지한다.

Odd-Even Turn Model은 virtual channel 없이 동작 가능한 2D mesh on-chip network에서 널리 사용되는 부분적 adaptive wormhole routing algorithm이다.
기존 turn model이 모든 위치에서 특정 turn을 금지하는 데 비해, Odd-Even은 열(column)의 parity(짝/홀)에 따라 금지 규칙이 달라진다:
- 규칙 1: even column에서는 east turn 금지 (Fig. 1.9a)
- 규칙 2: odd column에서는 north turn 금지 (Fig. 1.9b)
이 구조 덕분에 Odd-Even 모델은 기존 turn model들보다 더 높은 적응성(adaptivity)을 제공한다.

1.7.7 Application Specific Routing Algorithms
임베디드 시스템에서는 일반적인 네트워크와 달리, 애플리케이션의 계산 및 통신 요구사항을 정확히 특성화할 수 있다.
- 어떤 core 쌍이 통신하는지, 통신하지 않는지가 명확히 정의된다.
- 오프라인 분석을 통해 통신 쌍 간의 대역폭 요구량도 추정할 수 있다.
- 애플리케이션이 NoC에 mapping 및 scheduling된 이후에는 동시에 발생하지 않는 통신 정보도 얻을 수 있다.
이러한 정보는 APSRA (Application Specific Routing Algorithms) 방법론을 가능하게 한다. 이는 특정 애플리케이션에 최적화된 라우팅 알고리즘을 생성하는 데 사용된다.
핵심 아이디어
- 일반적인 CDG 대신, 애플리케이션이 실제 사용하는 통신 경로만 고려하여 ASCDG (Application-Specific CDG)를 생성한다.
- ASCDG는 CDG보다 사이클 수가 적고, 따라서 deadlock을 피하기 위해 금지할 turn 수도 줄어든다.
- 그 결과, 라우팅 함수의 적응성 손실을 최소화할 수 있다.
- Fig. 1.10: Communication Graph와 Topology Graph
- Task T₁ ~ T₆는 각각 Node P₁ ~ P₆에 매핑되어 있다.
- Fig. 1.11: minimal fully adaptive routing을 적용했을 때의 CDG
- 여러 개의 사이클이 존재하므로, Duato’s Theorem을 만족하지 못하며 deadlock 가능성이 있다.
- 사이클을 제거하려면 dependency를 제거해야 하고, 이는 routing function의 적응성 감소를 초래한다.

하지만:
- Fig. 1.12: 실제 통신 정보를 반영하여 ASCDG를 생성하면
- 사용되지 않는 dependency (예: l₁,₂ → l₂,₃)를 제거할 수 있다.
- 통신 그래프에는 T₁→T₃, T₁→T₆, T₄→T₃가 존재하지 않기 때문에 해당 경로는 사용되지 않는다.
- 이처럼 다른 dependency도 분석하면, 많은 경로가 안전하게 제거될 수 있다.

결과적으로:
- ASCDG에는 단 두 개의 사이클만 남는다.
- 예: l₄,₁ → l₁,₂는 T₄→T₂로 인해 발생한다.
- 이 통신은 P₄→P₅→P₂ 또는 P₄→P₁→P₂ 경로로 수행 가능하다.
- 후자의 경로만 금지하면 해당 dependency는 제거된다.
- 동일 방식으로 l₁,₄ → l₄,₅도 제거 가능하다 (T₁→T₅ 통신 제거).
따라서 deadlock-free 상태를 유지하면서도 routing adaptivity를 최소한으로 손상시킬 수 있다.
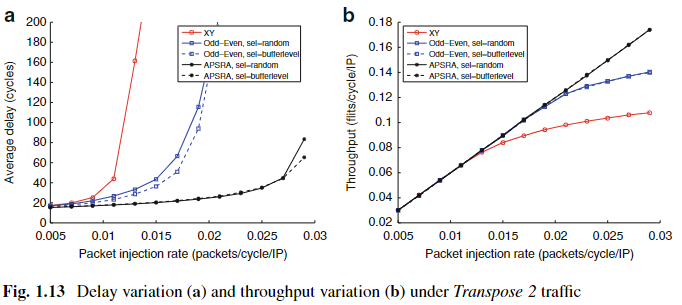
1.8 Performance Metrics
NoC 성능을 평가하고 비교하기 위해 다양한 지표(metrics)가 사용된다. 예를 들면 다음과 같다:
- 여러 형태의 latency:
- spread, minimum, maximum, average, expected
- 다양한 throughput
- latency jitter
- throughput jitter
그중 가장 널리 쓰이는 두 가지는 다음과 같다:
- Average Delay
- 모든 통신 쌍의 평균 communication delay의 평균.
- 하나의 통신에서의 communication delay는 packet들이 목적지까지 도달하는 데 걸린 시간의 평균이다.
- Packet delay는 packet의 header flit이 네트워크에 injection된 순간부터 tail flit이 도착할 때까지의 시간.
- Average Throughput
- 모든 목적지 node에 대한 throughput의 평균.
- 단위 시간당 목적지가 수신한 packet 수의 평균이다.
일반적으로, average delay와 average throughput은 packet injection rate에 따른 그래프로 나타낸다. 예시는 Fig. 1.13에 나와 있다.
- Transpose 2 트래픽 조건에서,
- XY, Odd-Even, APSRA routing function 비교.
- Selection policy는 random과 buffer-level.
1.9 Summary
이 장에서는 NoC 설계와 관련된 여러 핵심 개념들을 소개하였다.
다룬 주제는 다음과 같다:
- Direct 및 Indirect network에 대한 다양한 topology
- 다양한 switching 및 flow control mechanism
- Virtual channel 사용
- 여러 routing scheme
- Output selection technique
- 그리고 일반적인 NoC architecture